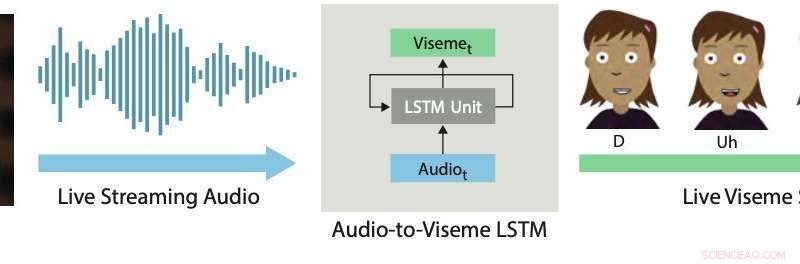
Sincronizzazione labiale in tempo reale. Il nostro approccio al deep learning utilizza un LSTM per convertire l'audio in streaming live in visemi discreti per i personaggi 2D. Credito:Aneja &Li.
L'animazione live 2-D è una forma di comunicazione abbastanza nuova e potente che consente agli attori umani di controllare i personaggi dei cartoni animati in tempo reale mentre interagiscono e improvvisano con altri attori o membri di un pubblico. Esempi recenti includono Stephen Colbert che intervista gli ospiti dei cartoni animati su L'ultimo spettacolo , Homer risponde alle domande telefoniche in diretta degli spettatori durante un segmento di I Simpson , Archer parla con un pubblico dal vivo al ComicCon, e le stelle di Disney's Star contro le forze del male e Il mio piccolo pony ospitare sessioni di chat dal vivo con i fan tramite YouTube o Facebook Live.
La produzione di animazioni live 2-D realistiche ed efficaci richiede l'uso di sistemi interattivi in grado di trasformare automaticamente le performance umane in animazioni in tempo reale. Un aspetto chiave di questi sistemi è ottenere una buona sincronizzazione labiale, il che significa essenzialmente che le bocche dei personaggi animati si muovono in modo appropriato quando parlano, imitando i movimenti osservati nella bocca degli artisti.
Una buona sincronizzazione labiale può rendere l'animazione 2-D dal vivo più convincente e potente, consentendo ai personaggi animati di incarnare la performance in modo più realistico. Al contrario, una scarsa sincronizzazione labiale in genere rompe l'illusione dei personaggi come partecipanti dal vivo in una performance o in un dialogo.
In un articolo recentemente prepubblicato su arXiv, due ricercatori di Adobe Research e dell'Università di Washington hanno introdotto un sistema interattivo basato sull'apprendimento profondo che genera automaticamente la sincronizzazione labiale dal vivo per personaggi animati 2-D a strati. Il sistema che hanno sviluppato utilizza un modello di memoria a lungo termine (LSTM), un'architettura di rete neurale ricorrente (RNN) spesso applicata a compiti che comportano la classificazione o l'elaborazione di dati, oltre a fare previsioni.
"Dal momento che il parlato è la componente dominante di quasi tutte le animazioni dal vivo, crediamo che il problema più critico da affrontare in questo dominio sia la sincronizzazione labiale dal vivo, che comporta la trasformazione del discorso di un attore in corrispondenti movimenti della bocca (cioè, sequenza di visemi) nel personaggio animato. In questo lavoro, ci concentriamo sulla creazione di sincronizzazione labiale di alta qualità per l'animazione 2-D dal vivo, " Wilmot Li e Deepali Aneja, i due ricercatori che hanno condotto la ricerca, detto TechXplore via e-mail.
Li è uno scienziato principale presso Adobe Research con un dottorato di ricerca. in informatica che ha condotto ricerche approfondite incentrate su argomenti all'intersezione tra computer grafica e interazione uomo-computer. Aneja, d'altra parte, sta attualmente completando un dottorato di ricerca. in informatica presso l'Università di Washington, dove fa parte del Laboratorio di Grafica e Imaging.
Il sistema sviluppato da Li e Aneja utilizza un semplice modello LSTM per convertire l'ingresso audio in streaming in una sequenza visema corrispondente a 24 fotogrammi al secondo, con una latenza inferiore a 200 millisecondi. In altre parole, il loro sistema consente alle labbra di un personaggio animato di muoversi in modo simile a quelle di un utente umano che parla in tempo reale, con meno di 200 millisecondi di ritardo tra la voce e il movimento delle labbra.
"In questo lavoro, diamo due contributi:identificare la rappresentazione delle caratteristiche e la configurazione di rete appropriate per ottenere risultati all'avanguardia per la sincronizzazione labiale 2-D dal vivo e ideare un nuovo metodo di potenziamento per la raccolta dei dati di addestramento per il modello, "Li e Aneja hanno spiegato.
"Per la sincronizzazione labiale di creazione manuale, gli animatori professionisti prendono decisioni stilistiche sulla scelta specifica dei visemi e sui tempi e il numero di transizioni. Di conseguenza, è improbabile che la formazione di un singolo modello "generale" sia sufficiente per la maggior parte delle applicazioni, " Dissero Li e Aneja. Inoltre, ottenere dati di sincronizzazione labiale etichettati per addestrare modelli di deep learning può essere sia costoso che dispendioso in termini di tempo. Gli animatori professionisti possono dedicare dalle cinque alle sette ore di lavoro al minuto di discorso alle sequenze di visemi dell'autore manuale. Consapevole di questi limiti, Li e Aneja hanno sviluppato un metodo in grado di generare dati di allenamento in modo più rapido ed efficace.
Per addestrare il loro modello LSTM in modo più efficace, Li e Aneja hanno introdotto una nuova tecnica che aumenta i dati di allenamento scritti a mano utilizzando il time warping audio. Questa procedura di aumento dei dati ha ottenuto una buona sincronizzazione labiale anche durante l'addestramento del modello su un piccolo set di dati etichettato.
Per valutare l'efficacia del loro sistema interattivo nel produrre la sincronizzazione labiale in tempo reale, i ricercatori hanno chiesto agli spettatori umani di valutare la qualità delle animazioni dal vivo alimentate dal loro modello con quelle prodotte utilizzando strumenti di animazione 2-D commerciali. Hanno scoperto che la maggior parte degli spettatori preferiva la sincronizzazione labiale generata dal loro approccio rispetto a quella prodotta da altre tecniche.
"Abbiamo anche studiato il compromesso tra la qualità della sincronizzazione labiale e la quantità di dati di allenamento, e abbiamo scoperto che il nostro metodo di aumento dei dati migliora significativamente l'output del modello, " Dissero Li e Aneja. "In generale, possiamo produrre risultati ragionevoli con soli 15 minuti di dati di sincronizzazione labiale scritti a mano."
interessante, i ricercatori hanno scoperto che il loro modello LSTM può acquisire diversi stili di sincronizzazione labiale in base ai dati su cui è addestrato, pur generalizzando bene su un'ampia gamma di oratori. Impressionati dagli incoraggianti risultati raggiunti dal modello, Adobe ha deciso di integrarne una versione all'interno del suo software Adobe Character Animator, uscito nell'autunno del 2018.
"Preciso, la sincronizzazione labiale a bassa latenza è importante per quasi tutte le impostazioni di animazione dal vivo, e i nostri esperimenti di giudizio umano mostrano che la nostra tecnica migliora sui motori di sincronizzazione labiale 2-D all'avanguardia esistenti, la maggior parte dei quali richiede l'elaborazione offline, " Dissero Li e Aneja. Così, i ricercatori ritengono che il loro lavoro abbia implicazioni pratiche immediate per la produzione di animazione 2-D sia dal vivo che non dal vivo. I ricercatori non sono a conoscenza del precedente lavoro di sincronizzazione labiale 2-D con confronti altrettanto completi con strumenti commerciali.
Nel loro recente studio, Li e Aneja sono stati in grado di affrontare alcune delle principali sfide tecniche associate allo sviluppo di tecniche per l'animazione 2-D dal vivo. Primo, hanno dimostrato un nuovo metodo per codificare le regole artistiche per la sincronizzazione labiale 2-D usando gli RNN, che potrebbe essere ulteriormente potenziato in futuro.
I ricercatori ritengono che ci siano molte più opportunità per applicare moderne tecniche di apprendimento automatico per migliorare i flussi di lavoro di animazione 2-D. "Finora, una sfida è stata la mancanza di dati di formazione, che è costoso da raccogliere. Però, come mostriamo in questo lavoro, potrebbero esserci modi per sfruttare i dati strutturati e gli algoritmi di modifica automatica (ad es. distorsione temporale dinamica) per massimizzare l'utilità dei dati di animazione realizzati a mano, " Dissero Li e Aneja.
Sebbene la strategia di aumento dei dati proposta dai ricercatori possa ridurre significativamente i requisiti dei dati di addestramento per i modelli progettati per produrre la sincronizzazione labiale in tempo reale, l'animazione manuale di un contenuto di sincronizzazione labiale sufficiente per addestrare nuovi modelli richiede ancora un lavoro e uno sforzo considerevoli. Secondo Li e Aneja, però, riqualificare un intero modello da zero per ogni nuovo stile di sincronizzazione labiale che incontra potrebbe non essere necessario.
I ricercatori sono interessati a esplorare strategie di messa a punto che potrebbero consentire agli animatori di adattare il modello a stili diversi con una quantità molto minore di input dell'utente. "Un'idea correlata è quella di apprendere direttamente un modello di sincronizzazione labiale che includa in modo esplicito parametri stilistici sintonizzabili. Sebbene ciò possa richiedere un set di dati di allenamento molto più ampio, il potenziale vantaggio è un modello abbastanza generale da supportare una gamma di stili di sincronizzazione labiale senza ulteriore formazione, " hanno detto i ricercatori.
interessante, nei loro esperimenti, i ricercatori hanno osservato che la semplice perdita di entropia incrociata che hanno usato per addestrare il loro modello non rifletteva accuratamente le differenze percettive più rilevanti tra le sequenze di sincronizzazione labiale. Più specificamente, hanno riscontrato che alcune discrepanze (ad es. perdere una transizione o sostituire un visema a bocca chiusa con uno a bocca aperta) sono molto più evidenti di altri. "Pensiamo che progettare o apprendere una perdita basata sulla percezione nella ricerca futura possa portare a miglioramenti nel modello risultante, " Dissero Li e Aneja.
© 2019 Science X Network














