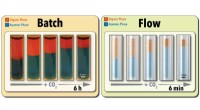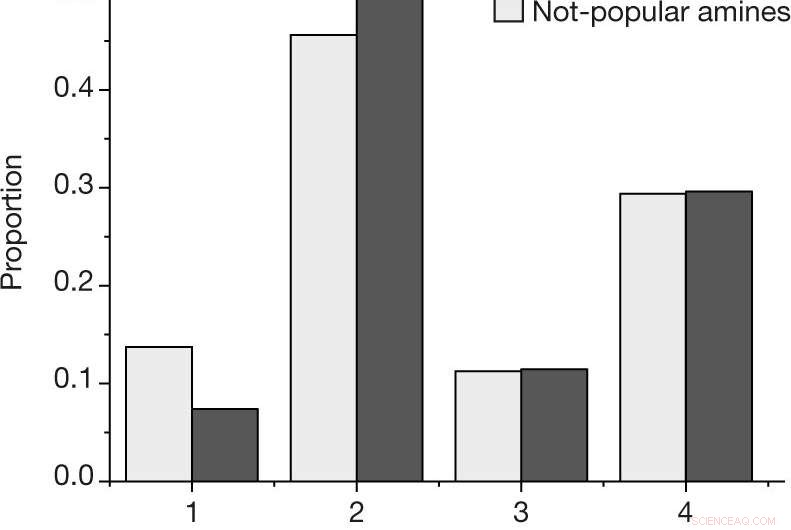
un, La proporzione per risultato per ogni reazione, utilizzando la scala dei risultati descritta in Metodi, per le ammine popolari e non popolari nel set di dati selezionato dall'uomo. B, Probabilità stimata di osservare almeno una reazione di successo (risultato 4) o fallimento (risultati 1, 2 e 3) per una data ammina, per le N = 27 ammine popolari e N = 28 non popolari nel set di dati selezionato dall'uomo. I valori centrali indicano la proporzione osservata dei risultati. Le barre di errore indicano una stima bootstrap della deviazione standard. Credito: Natura (2019). DOI:10.1038/s41586-019-1540-5
Un team di scienziati dei materiali dell'Haverford College ha mostrato come la distorsione umana nei dati può influire sui risultati degli algoritmi di apprendimento automatico utilizzati per prevedere nuovi reagenti da utilizzare nella realizzazione dei prodotti desiderati. Nel loro articolo pubblicato sulla rivista Natura , il gruppo descrive come testare un algoritmo di apprendimento automatico con diversi tipi di set di dati e cosa hanno trovato.
Una delle applicazioni più note degli algoritmi di apprendimento automatico è nel riconoscimento facciale. Ma ci sono possibili problemi con tali algoritmi. Uno di questi problemi si verifica quando un algoritmo facciale destinato a cercare un individuo tra molti volti è stato addestrato utilizzando persone di una sola razza. In questo nuovo sforzo, i ricercatori si sono chiesti se il pregiudizio, involontario o meno, potrebbero emergere nei risultati degli algoritmi di apprendimento automatico utilizzati nelle applicazioni chimiche progettate per cercare nuovi prodotti.
Tali algoritmi utilizzano dati che descrivono gli ingredienti delle reazioni che portano alla creazione di un nuovo prodotto. Ma i dati su cui è addestrato il sistema potrebbero avere un impatto importante sui risultati. I ricercatori osservano che attualmente, tali dati sono ottenuti da sforzi di ricerca pubblicati, il che significa che sono tipicamente generati dagli esseri umani. Notano che i dati di tali sforzi potrebbero essere stati generati dagli stessi ricercatori, o da altri ricercatori che lavorano su sforzi separati. I dati potrebbero anche provenire da una singola persona semplicemente relazionandosi a memoria, o dal suggerimento di un professore, o uno studente laureato con un'idea brillante. Il punto è, i dati potrebbero essere distorti in termini di background della risorsa.
In questo nuovo sforzo, i ricercatori volevano sapere se tali distorsioni potrebbero avere un impatto sui risultati degli algoritmi di apprendimento automatico utilizzati per le applicazioni chimiche. Per scoprirlo, hanno esaminato un insieme specifico di materiali chiamati borati di vanadio ammina-templati. Quando sono sintetizzati con successo, forma di cristalli, un modo semplice per determinare se una reazione ha avuto successo.
L'esperimento consisteva nell'addestrare un algoritmo di apprendimento automatico sui dati che circondano la sintesi dei borati di vanadio, e quindi programmare il sistema per crearne uno proprio. Alcuni dei dati raccolti dai ricercatori sono stati generati dall'uomo, e una parte è stata raccolta a caso. Riferiscono che l'algoritmo addestrato sui dati casuali ha fatto meglio a trovare modi per sintetizzare i borati di vanadio rispetto a quando ha utilizzato dati generati dagli esseri umani. Sostengono che questo mostra un chiaro pregiudizio nei dati creati dagli umani.
© 2019 Scienza X Rete