TbD-net risolve il problema del ragionamento visivo suddividendolo in una catena di attività secondarie. La risposta a ciascuna sottoattività è mostrata in mappe di calore evidenziando gli oggetti di interesse, consentendo agli analisti di vedere il processo di pensiero della rete. Credito:Intelligence and Decision Technologies Group 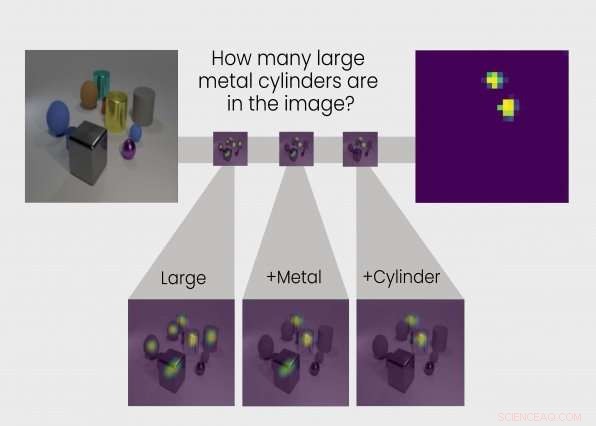
Impariamo attraverso la ragione come interpretare il mondo. Così, pure, fare reti neurali. Ora un team di ricercatori dell'Intelligence and Decision Technologies Group del MIT Lincoln Laboratory ha sviluppato una rete neurale che esegue passaggi di ragionamento simili a quelli umani per rispondere a domande sui contenuti delle immagini. Chiamato Transparency by Design Network (TbD-net), il modello rende visivamente il suo processo di pensiero mentre risolve i problemi, permettendo agli analisti umani di interpretare il suo processo decisionale. Il modello offre prestazioni migliori rispetto alle migliori reti neurali di ragionamento visivo di oggi.
Capire come una rete neurale arriva alle sue decisioni è stata una sfida di vecchia data per i ricercatori di intelligenza artificiale (AI). Come suggerisce la parte neurale del loro nome, le reti neurali sono sistemi di intelligenza artificiale ispirati al cervello destinati a replicare il modo in cui gli umani apprendono. Sono costituiti da livelli di input e output, e strati intermedi che trasformano l'input nell'output corretto. Alcune reti neurali profonde sono diventate così complesse che è praticamente impossibile seguire questo processo di trasformazione. Ecco perché vengono definiti sistemi "scatola nera", con le loro esatte vicende all'interno opachi anche agli ingegneri che li costruiscono.
Con TbD-net, gli sviluppatori mirano a rendere trasparenti questi meccanismi interni. La trasparenza è importante perché consente agli esseri umani di interpretare i risultati di un'IA.
È importante sapere, Per esempio, che cosa pensa esattamente che una rete neurale utilizzata nelle auto a guida autonoma sia la differenza tra un pedone e un segnale di stop, e in quale punto lungo la sua catena di ragionamento vede quella differenza. Queste informazioni consentono ai ricercatori di insegnare alla rete neurale a correggere eventuali ipotesi errate. Ma gli sviluppatori di TbD-net affermano che le migliori reti neurali oggi mancano di un meccanismo efficace per consentire agli umani di comprendere il loro processo di ragionamento.
"I progressi nel miglioramento delle prestazioni nel ragionamento visivo sono andati a scapito dell'interpretabilità, " dice Ryan Soklaski, che ha costruito TbD-net con i colleghi ricercatori Arjun Majumdar, David Mascharka, e Filippo Tran.
Il gruppo del Lincoln Laboratory è stato in grado di colmare il divario tra prestazioni e interpretabilità con TbD-net. Una chiave del loro sistema è una raccolta di "moduli, " piccole reti neurali specializzate per eseguire sottoattività specifiche. Quando a TbD-net viene posta una domanda di ragionamento visivo su un'immagine, suddivide la domanda in sottoattività e assegna il modulo appropriato per svolgere la sua parte. Come gli operai in una catena di montaggio, ogni modulo si basa su ciò che il modulo prima di aver capito per produrre alla fine il finale, risposta corretta. Nel complesso, TbD-net utilizza una tecnica di intelligenza artificiale che interpreta le domande del linguaggio umano e suddivide queste frasi in attività secondarie, seguito da molteplici tecniche di intelligenza artificiale di visione artificiale che interpretano le immagini.
Majumdar dice:"Spezzando una complessa catena di ragionamenti in una serie di sottoproblemi più piccoli, ognuno dei quali può essere risolto indipendentemente e composto, è un mezzo potente e intuitivo per ragionare."
L'output di ogni modulo è rappresentato visivamente in quella che il gruppo chiama una "maschera di attenzione". La maschera di attenzione mostra i blob della mappa termica sugli oggetti nell'immagine che il modulo sta identificando come risposta. Queste visualizzazioni consentono all'analista umano di vedere come un modulo interpreta l'immagine.
Prendere, Per esempio, la seguente domanda posta a TbD-net:"In questa immagine, di che colore è il grande cubo di metallo?" Per rispondere alla domanda, il primo modulo individua solo oggetti di grandi dimensioni, producendo una maschera di attenzione con quegli oggetti grandi evidenziati. Il modulo successivo prende questo output e trova quali di quegli oggetti identificati come grandi dal modulo precedente sono anch'essi di metallo. L'output di quel modulo viene inviato al modulo successivo, che identifica quale di quelle grandi, oggetti di metallo è anche un cubo. Alla fine, questa uscita viene inviata ad un modulo in grado di determinare il colore degli oggetti. L'output finale di TbD-net è "rosso, "la risposta corretta alla domanda.
Quando testato, TbD-net ha ottenuto risultati che superano i modelli di ragionamento visivo più performanti. I ricercatori hanno valutato il modello utilizzando un set di dati visivo di risposta alle domande composto da 70, 000 immagini di formazione e 700, 000 domande, insieme a set di test e convalida di 15, 000 immagini e 150, 000 domande. Il modello iniziale ha raggiunto un'accuratezza del test del 98,7% sul set di dati, quale, secondo i ricercatori, supera di gran lunga altri approcci basati su reti di moduli neurali.
È importante sottolineare che i ricercatori sono stati quindi in grado di migliorare questi risultati grazie al vantaggio chiave del loro modello:la trasparenza. Osservando le maschere di attenzione prodotte dai moduli, potevano vedere dove le cose andavano storte e perfezionare il modello. Il risultato finale è stata una prestazione all'avanguardia con una precisione del 99,1 percento.
"Il nostro modello fornisce in modo semplice, output interpretabili in ogni fase del processo di ragionamento visivo, "dice Mascharka.
L'interpretabilità è particolarmente preziosa se gli algoritmi di deep learning devono essere implementati insieme agli umani per aiutare ad affrontare complesse attività del mondo reale. Per creare fiducia in questi sistemi, gli utenti avranno bisogno della capacità di ispezionare il processo di ragionamento in modo che possano capire perché e come un modello potrebbe fare previsioni errate.
Paul Metzger, leader del gruppo Intelligence and Decision Technologies, afferma che la ricerca "fa parte del lavoro del Lincoln Laboratory per diventare un leader mondiale nella ricerca applicata sull'apprendimento automatico e nell'intelligenza artificiale che promuove la collaborazione uomo-macchina".
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.