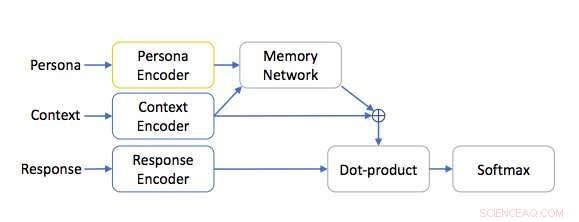
Architettura di rete basata sulla persona. Credito:Mazaré et al.
I ricercatori di Facebook hanno recentemente compilato un set di dati di 5 milioni di personaggi e 700 milioni di dialoghi basati su personaggi. Questo database potrebbe essere utilizzato per addestrare sistemi di dialogo end-to-end, risultando in dialoghi più coinvolgenti e ricchi tra agenti informatici e umani.
Sistemi di dialogo, o agenti di conversazione (CA), sono sistemi informatici progettati per comunicare con gli esseri umani tramite testo, discorso, grafica, o altri metodi, in modo coerente. Finora, sistemi di dialogo basati su architetture neurali, come LSTM o reti di memoria, si sono rivelati particolarmente promettenti nel raggiungere una comunicazione fluente, in particolare se addestrato direttamente sui registri di dialogo.
"Uno dei loro principali vantaggi è che possono fare affidamento su grandi fonti di dati di dialoghi esistenti per imparare a coprire vari domini senza richiedere alcuna conoscenza esperta, " hanno scritto i ricercatori nel loro articolo, che è stato pre-pubblicato su arXiv. "Però, il rovescio della medaglia è che mostrano anche un coinvolgimento limitato, soprattutto in contesti di chiacchiere:mancano di coerenza e non sfruttano strategie di coinvolgimento proattive come fanno (anche parzialmente) i chatbot con script".
In un recente studio, un diverso team di ricercatori del Montreal Institute for Learning Algorithms (MILA) e Facebook AI ha creato un set di dati chiamato PERSONA-CHAT, che include dialoghi tra agenti con profili testuali, o personaggi, ad essi attaccato. Hanno scoperto che la formazione di un sistema di dialogo su una particolare persona ha migliorato il loro coinvolgimento nelle interazioni.
"Però, il set di dati PERSONA-CHAT è stato creato utilizzando un meccanismo di raccolta dati artificiale basato su Mechanical Turk, " hanno spiegato i ricercatori nel loro articolo. "Di conseguenza, né i dialoghi né i personaggi possono essere pienamente rappresentativi delle reali interazioni utente-bot e la copertura del set di dati rimane limitata, contenente poco più di 1k personaggi diversi."
Per affrontare i limiti del set di dati precedentemente compilato, i ricercatori di Facebook hanno creato un nuovo, set di dati di dialogo su larga scala basato sulla persona, composto da conversazioni estratte dalla piattaforma online Reddit. Il loro studio porta il lavoro dei loro predecessori un passo avanti, utilizzando interazioni più rappresentative.
"In questo documento, costruiamo un set di dati di dialogo basato su persona su larga scala utilizzando conversazioni precedentemente estratte da Reddit, " hanno scritto i ricercatori. "Con semplici euristiche, creiamo un corpus di oltre 5 milioni di persone che abbracciano più di 700 milioni di conversazioni."
Per valutarne l'efficacia, i ricercatori hanno addestrato sistemi di dialogo end-to-end basati sulla persona sul loro set di dati appena sviluppato. I sistemi formati sul loro set di dati sono stati in grado di condurre conversazioni più coinvolgenti, superando altri agenti conversazionali che non hanno avuto accesso ai personaggi durante la loro formazione.
interessante, il loro set di dati ha portato a risultati all'avanguardia anche quando i sistemi di dialogo erano semplicemente pre-addestrati su di esso. In futuro, questi risultati potrebbero portare allo sviluppo di chatbot più coinvolgenti, che possono anche essere personalizzati e formati per acquisire una particolare persona.
"Mostriamo che i modelli di formazione per allineare le risposte sia con la persona del loro autore sia con il contesto migliorano le prestazioni di previsione, " hanno scritto i ricercatori. "Poiché il pre-allenamento porta a un notevole miglioramento delle prestazioni, il lavoro futuro potrebbe mettere a punto questo modello per vari sistemi di dialogo".
© 2018 Tech Xplore