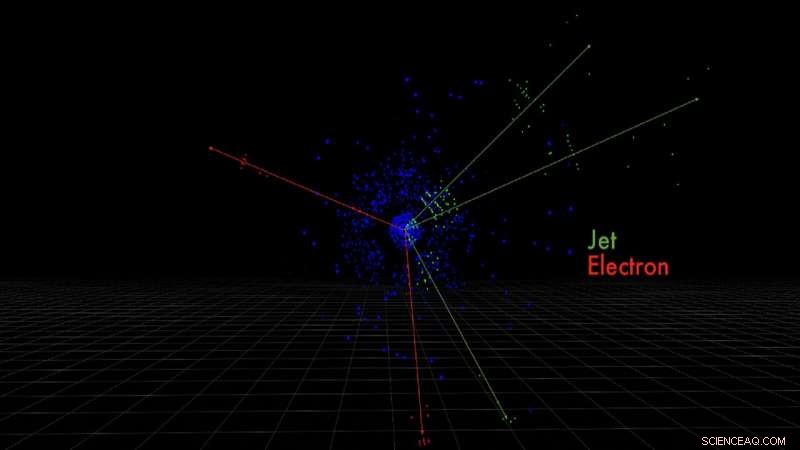
Questi sono i pixel del rivelatore di elettroni e getti di quark prodotti da una collisione di protoni simulata, misurato dal rivelatore ATLAS. Credito:Taylor Childers
Mentre la fisica e la cosmologia delle alte energie sembrano mondi separati in termini di pura scala, fisici e cosmologi dell'Argonne stanno utilizzando metodi di apprendimento automatico simili per affrontare i problemi di classificazione sia delle particelle subatomiche che delle galassie.
La fisica e la cosmologia delle alte energie sembrano mondi a parte in termini di pura scala, ma le componenti invisibili che compongono il campo dell'una informano la composizione e la dinamica dell'altra:stelle che collassano, nebulose stellari e, forse, materia oscura.
Per decenni, le tecniche con cui i ricercatori in entrambi i campi hanno studiato i loro domini sembravano quasi incompatibili, anche. La fisica delle alte energie si affidava ad acceleratori e rivelatori per ottenere informazioni sulle interazioni energetiche delle particelle, mentre i cosmologi guardavano attraverso tutti i tipi di telescopi per svelare i segreti dell'universo.
Sebbene nessuno dei due abbia rinunciato all'attrezzatura fondamentale del loro campo particolare, fisici e cosmologi dell'Argonne National Laboratory del Dipartimento dell'Energia degli Stati Uniti (DOE) stanno attaccando complessi problemi multiscala utilizzando varie forme di una tecnica di intelligenza artificiale chiamata machine learning.
Già utilizzato in numerosi campi, l'apprendimento automatico può aiutare a identificare modelli nascosti imparando dai dati di input e migliorando progressivamente le previsioni sui nuovi dati. Può essere applicato a compiti di classificazione visiva o nella rapida riproduzione di calcoli complicati e costosi dal punto di vista computazionale.
Con il potenziale per trasformare radicalmente il modo in cui viene condotta la scienza, queste tecniche di intelligenza artificiale ci aiuteranno a comprendere meglio la distribuzione delle galassie nell'universo oa visualizzare meglio la formazione di nuove particelle da cui potremmo dedurre nuova fisica.
"Nel corso dei decenni, abbiamo sviluppato algoritmi tradizionali che ricostruiscono le firme delle varie particelle che ci interessano, " ha detto Taylor Childers, un fisico delle particelle e un informatico con l'Argonne Leadership Computing Facility (ALCF), una struttura per gli utenti dell'Office of Science del DOE.
"Ci è voluto molto tempo per svilupparli e sono molto precisi, " aggiunse. "Ma allo stesso tempo, sarebbe interessante sapere se le tecniche di classificazione delle immagini dell'apprendimento automatico che sono state utilizzate con successo da Google e Facebook possono semplificare o abbreviare lo sviluppo di algoritmi che identificano le firme delle particelle nei nostri rilevatori 3D".
Childers lavora con i fisici delle alte energie Argonne, tutti membri della collaborazione sperimentale ATLAS al Large Hadron Collider (LHC) del CERN, il più grande e potente collisore di particelle al mondo. Cercando di risolvere una vasta gamma di problemi di fisica, il rivelatore ATLAS è alto otto piani e lungo 150 piedi in un punto attorno all'anello di collisione della circonferenza di 17 miglia dell'LHC, dove misura i prodotti di protoni che collidono a velocità prossime a quella della luce.
Secondo il sito web di ATLAS, "Ogni secondo nel rivelatore ATLAS avvengono oltre un miliardo di interazioni tra particelle, una velocità di trasmissione dati equivalente a 20 conversazioni telefoniche simultanee tenute da ogni persona sulla terra."
Sebbene solo una piccola percentuale di queste collisioni sia ritenuta degna di studio, circa un milione al secondo, fornisce comunque una montagna di dati per gli scienziati da indagare.
Queste collisioni di particelle ad alta velocità creano nuove particelle nella loro scia, come elettroni o sciami di quark, ciascuno lasciando una firma univoca nel rivelatore. Sono queste firme che Childers vorrebbe identificare attraverso l'apprendimento automatico.
Tra le sfide c'è quella di catturare quelle firme energetiche come immagini in un complesso spazio 3-D. Una foto, Per esempio, è essenzialmente una rappresentazione 2D di dati 3D con posizioni verticali e orizzontali. I dati dei pixel, i colori nell'immagine, sono orientati spazialmente e contengono informazioni spaziali codificate, ad esempio, gli occhi di un gatto sono vicino al naso, e le orecchie sono in alto a sinistra e a destra.
"Quindi il loro orientamento spaziale è importante. Lo stesso vale per le immagini che scattiamo all'LHC. Quando una particella attraversa il nostro rivelatore, lascia un'impronta energetica in schemi spaziali che sono specifici delle diverse particelle, " ha spiegato Childers.
Aggiungete a ciò la quantità di dati codificati non solo nelle firme, ma lo spazio 3-D intorno a loro. Dove i tradizionali esempi di machine learning per il riconoscimento delle immagini, quei gatti, di nuovo:gestisci centinaia di migliaia di pixel, Le immagini di ATLAS contengono centinaia di milioni di pixel del rilevatore.
Quindi l'idea, Egli ha detto, consiste nel trattare le immagini del rilevatore come immagini tradizionali. Utilizzando una tecnica di apprendimento automatico chiamata reti neurali convoluzionali, che apprendono come i dati sono correlati spazialmente, possono estrarre lo spazio 3D per identificare più facilmente le caratteristiche delle particelle specifiche.

L'immagine mostra un anello di Einstein (al centro a destra) formato dalla lente gravitazionale di una galassia che forma stelle (blu) da una massiccia galassia luminosa rossa (arancione). Questo sistema è stato scoperto per la prima volta dalla Sloan Digital Sky Survey nel 2007; le immagini provengono dal telescopio spaziale Hubble. Credito:NASA
Childers spera che questi algoritmi di apprendimento automatico alla fine sostituiranno i tradizionali algoritmi fatti a mano, riducendo notevolmente il tempo necessario per elaborare quantità simili di dati e migliorando la precisione dei risultati misurati.
"Possiamo anche sostituire lo sviluppo decennale necessario per nuovi rivelatori e ridurlo con nuovi modelli di addestramento per rivelatori futuri, " Egli ha detto.
Uno spazio più grande
I cosmologi di Argonne utilizzano metodi di apprendimento automatico simili per affrontare i problemi di classificazione, ma su scala molto più ampia.
"Il problema con la cosmologia è che gli oggetti che stiamo guardando sono complicati e sfocati, " disse Salman Habib, Direttore della divisione di Scienze computazionali di Argonne e vicedirettore ad interim della sua divisione di fisica delle alte energie. "Quindi descrivere i dati in modo più semplice diventa molto difficile."
Lui e i suoi colleghi stanno sfruttando i supercomputer dell'Argonne e di altri laboratori nazionali del DOE per ricostruire i particolari dell'universo, galassia per galassia. Stanno creando cataloghi di galassie simulate altamente dettagliati che possono essere utilizzati per il confronto con i dati reali presi dai telescopi di indagine, come il Large Synoptic Survey Telescope, una partnership tra il DOE e la National Science Foundation.
Ma per rendere queste risorse preziose per i ricercatori, devono essere il più vicino possibile alla realtà.
Algoritmi di apprendimento automatico, Habib ha detto, sono molto bravi a individuare caratteristiche che possono essere facilmente caratterizzate dalla geometria, come quei gatti. Ancora, simile all'avvertimento sugli specchietti del veicolo, gli oggetti nei cieli non sono sempre come appaiono.
Prendi il fenomeno della forte lente gravitazionale; la distorsione di una sorgente di luce di fondo, una galassia o un ammasso di galassie, da parte di una massa interposta. La deviazione delle traiettorie dei raggi luminosi dalla sorgente dovuta alla gravità porta ad una distorsione della forma della sorgente di sfondo, posizione e orientamento; questa distorsione fornisce informazioni sulla distribuzione di massa dell'oggetto interposto. La situazione osservativa attuale non è così semplice, però.
Un blob completamente rotondo che è obiettivo, Per esempio, potrebbe apparire allungato in una direzione o nell'altra, mentre un giro, un oggetto a forma di disco senza lente potrebbe sembrare ellittico se visto parzialmente sul bordo.
"Quindi come fai a sapere se l'oggetto che stai guardando non è un oggetto rotondo che è stato ruotato, o uno che è stato girato?", ha chiesto Habib. "Questo è il tipo di cose complicate che l'apprendimento automatico deve essere in grado di capire".
Per fare questo, i ricercatori creano un campione di formazione di milioni di oggetti dall'aspetto realistico, metà dei quali sono lenti. Gli algoritmi di apprendimento automatico si occupano quindi del lavoro di cercare di apprendere le differenze tra gli oggetti lenti e non lenti. I risultati vengono verificati rispetto a un insieme noto di oggetti sintetici con e senza lenti.
Ma i risultati raccontano solo metà della storia:quanto bene gli algoritmi funzionano sui dati dei test. Per migliorare ulteriormente la loro precisione per i dati reali, i ricercatori mescolano una percentuale di dati sintetici con i dati osservati in precedenza ed eseguono gli algoritmi, ancora, confrontando quanto bene hanno scelto gli oggetti lenti nel campione di addestramento rispetto ai dati combinati.
"Alla fine, potresti scoprire che funziona abbastanza bene, ma forse non come vorresti, " ha spiegato Habib. "Potresti dire 'OK, questa informazione da sola non sarà sufficiente, Ho bisogno di raccogliere di più.' È un processo piuttosto lungo e complesso".
Due obiettivi primari della moderna cosmologia, Egli ha detto, servono a capire perché l'espansione dell'universo sta accelerando e qual è la natura della materia oscura. La materia oscura è circa cinque volte più abbondante della materia normale, ma la sua origine ultima rimane misteriosa. Per avvicinarsi a distanza a una risposta, la scienza deve essere molto deliberata, molto preciso.
"Nella fase attuale, Non credo che possiamo risolvere tutti i nostri problemi con le applicazioni di machine learning, " ha ammesso Habib. "Ma direi che l'apprendimento automatico sarà molto importante per tutti gli aspetti della cosmologia di precisione nel prossimo futuro".
Man mano che le tecniche di apprendimento automatico vengono sviluppate e perfezionate, la loro utilità sia per la fisica delle alte energie che per la cosmologia crescerà sicuramente in modo esponenziale, fornendo la speranza di nuove scoperte o nuove interpretazioni che alterano la nostra comprensione del mondo su più scale.