Illustrazione del processo di identificazione convenzionale dei metaboliti. Credito:Pacific Northwest National Laboratory
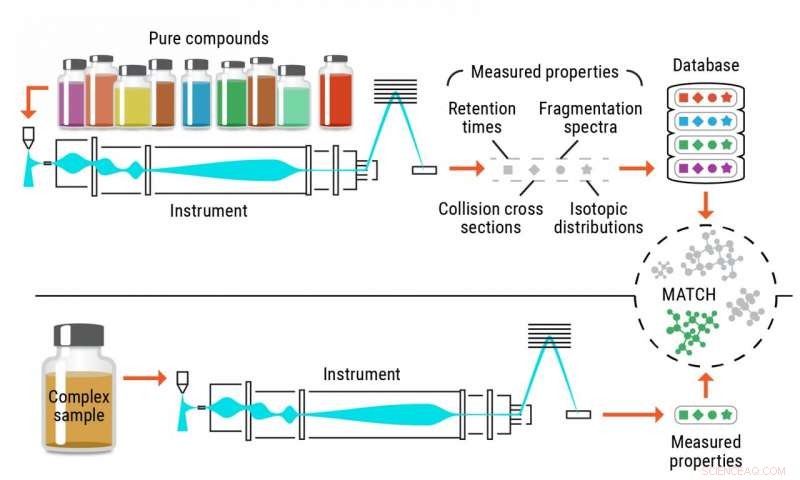
Identificazione accurata dei metaboliti, e altri piccoli prodotti chimici, nei campioni biologici e ambientali è storicamente insufficiente quando si utilizzano metodi tradizionali. Le tattiche convenzionali si basano su composti di riferimento puri, chiamati standard, riconoscere le stesse molecole in campioni complessi. Questi approcci sono limitati dalla disponibilità delle sostanze chimiche pure utilizzate come standard.
"Volevamo davvero aggirare l'attuale paradigma di come viene condotto un esperimento di metabolomica e di come le molecole vengono identificate con sicurezza, "ha detto Tom Metz, scienziato biomedico presso il Pacific Northwest National Laboratory (PNNL) e direttore del Pacific Northwest Advanced Compound Identification Core.
Un problema con il metodo attuale è che ci sono solo così tanti composti puri che i ricercatori possono acquistare dai fornitori; la maggior parte dei fornitori ha accesso a circa 3, 000-4, 000 composti.
"Se si considera ciò che si prevede che accada in natura, stai guardando> 1030 composti o più che potrebbero essere possibili, " disse Metz. "Allora, quando si confrontano le poche migliaia di sostanze chimiche standard a cui si ha accesso con il vasto numero di potenziali composti, non sei nemmeno vicino."
Approccio all'identificazione senza standard
Per risolvere questo problema Metz e il suo team al PNNL hanno concettualizzato un approccio - metabolomica senza standard - con cui calcolano o prevedono informazioni su più proprietà per molecole di interesse al fine di generare librerie di riferimento complete e quindi abbinare i dati sperimentali contenenti le stesse proprietà a queste biblioteche, che consente l'identificazione del composto.
Utilizzando questo nuovo approccio, i ricercatori inviano strutture chimiche attraverso programmi di apprendimento automatico o di chimica quantistica per prevedere con precisione le proprietà sperimentali dei metaboliti.
"Se siamo abbastanza accurati su queste previsioni, in teoria non avremmo mai più bisogno di analizzare un composto puro, " ha detto Metz. "Questa raccolta di strumenti sposterà l'attuale paradigma nella metabolomica, e nel prossimo futuro ci saranno alcune applicazioni davvero valide per mostrare alla comunità di ricerca i vantaggi di questo nuovo approccio".
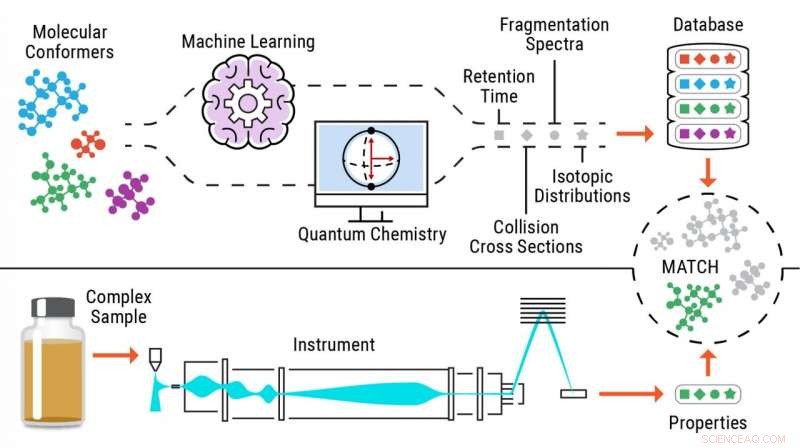
Illustrazione del processo di identificazione dei metaboliti senza standard. Credito:Pacific Northwest National Laboratory
Non dovendo fare affidamento su dati provenienti da analisi di standard puri per identificare piccole molecole, l'approccio privo di standard consente di identificare fino al 90% in più di sostanze chimiche nei campioni e rende questi strumenti di calcolo estremamente utili in diverse aree di applicazione, compresa la scoperta di nuovi farmaci, chimica forense, e la ricerca ambientale e biomedica.
"Per esempio, nella progettazione di nuovi farmaci un utente sarebbe in grado di dire, 'Ho un certo numero di proprietà con questi determinati farmaci, ma capita che siano tossici. Possiamo prevedere un composto che avrebbe proprietà simili ma potrebbe non essere tossico?'", ha detto Metz. "Se si potessero fornire i dati di addestramento corretti al programma DarkChem, DarkChem potrebbe quindi eseguire quella previsione".
Suite di programmi personalizzabile
Il nuovo approccio all'identificazione della metabolomica senza standard utilizza quattro strumenti chiave per generare nelle librerie di riferimento dei metaboliti derivati dal silico, e per estrarre e abbinare i dati sperimentali per ottenere identificazioni di composti:
Gli strumenti sono stati progettati per lavorare insieme, ma possono essere utilizzati anche separatamente. I ricercatori possono personalizzare le diverse applicazioni in base alle esigenze del cliente o alle aree di ricerca, creando un approccio completamente modulare.
Avanzare un campo di ricerca
Proprio adesso, nella comunità della metabolomica, tutti i ricercatori identificano lo stesso insieme di molecole in ogni campione. Il motivo è che hanno tutti gli stessi composti puri che hanno acquistato per costruire le loro librerie di riferimento.
"La nostra visione è che utilizzando l'approccio privo di standard non sarai mai limitato dalla distesa di piccole molecole che possono essere identificate in un campione, " ha detto Metz. "Questo è davvero un punto di svolta per la metabolomica. Ed è molto eccitante vedere cosa ha in serbo il prossimo anno o giù di lì".