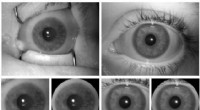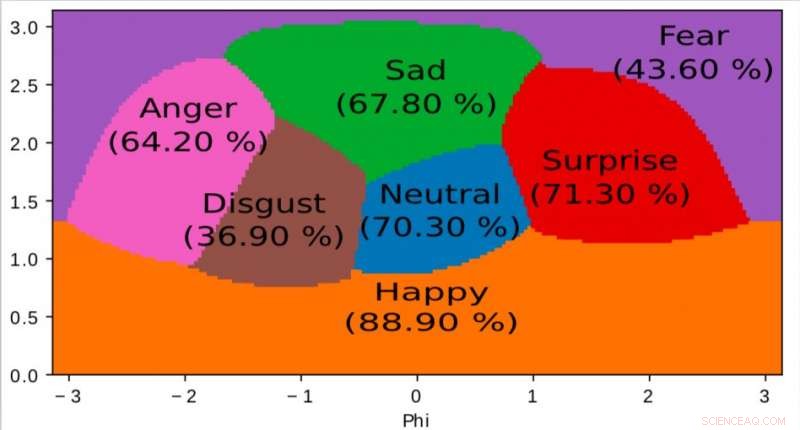
Una rappresentazione dello spazio interno appresa dal nostro algoritmo e utilizzata per mappare le emozioni in uno spazio continuo 2D. È interessante notare che anche se i dati di addestramento contengono solo etichette di emozioni discrete, la rete apprende uno spazio continuo, permettendo non solo di descrivere finemente lo stato emotivo delle persone ma anche di posizionare le emozioni in relazione tra loro. Questo spazio ha una forte somiglianza con lo spazio di valenza dell'eccitazione definito dalla psicologia moderna. Credito:Jurie et al.
I ricercatori dell'Orange Labs e della Normandie University hanno sviluppato un nuovo modello neurale profondo per il riconoscimento delle emozioni audiovisive che funziona bene con piccoli set di allenamento. Il loro studio, che è stato pre-pubblicato su arXiv , segue una filosofia di semplicità, limitando sostanzialmente i parametri che il modello acquisisce dai dataset e utilizzando semplici tecniche di apprendimento.
Le reti neurali per il riconoscimento delle emozioni hanno una serie di applicazioni utili nei contesti sanitari, analisi del cliente, sorveglianza, e anche animazione. Mentre gli algoritmi di deep learning all'avanguardia hanno raggiunto risultati notevoli, la maggior parte non è ancora in grado di raggiungere la stessa comprensione delle emozioni raggiunta dagli umani.
"Il nostro obiettivo generale è facilitare l'interazione uomo-computer rendendo i computer in grado di percepire vari dettagli sottili espressi dagli esseri umani, "Frédéric Jurie, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Percepire le emozioni contenute nelle immagini, video, voce e suono rientrano in questo contesto".
Recentemente, gli studi hanno messo insieme set di dati multimodali e temporali che contengono video annotati e clip audiovisive. Eppure questi set di dati contengono in genere un numero relativamente piccolo di campioni annotati, mentre per fare bene, la maggior parte degli algoritmi di deep learning esistenti richiedono set di dati più grandi.
I ricercatori hanno cercato di affrontare questo problema sviluppando un nuovo quadro per il riconoscimento delle emozioni audiovisive, che fonde l'analisi di filmati visivi e sonori, mantenendo un alto livello di precisione anche con set di dati di addestramento relativamente piccoli. Hanno addestrato il loro modello neurale su AFEW, un set di dati di 773 clip audiovisivi estratti da film e annotati con emozioni discrete.

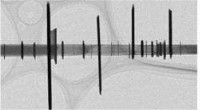
Illustrazione di come questo spazio 2D può essere utilizzato per controllare le emozioni espresse dai volti, in modo continuo, con l'ausilio di reti generative avversarie (GAN). Credito:Jurie et al.
"Si può vedere questo modello come una scatola nera che elabora il video e deduce automaticamente lo stato emotivo delle persone, " ha spiegato Jurie. "Un grande vantaggio di modelli neurali così profondi è che imparano da soli come elaborare il video analizzando esempi, e non richiedono esperti per fornire unità di elaborazione specifiche."
Il modello ideato dai ricercatori segue il principio filosofico del rasoio di Occam, il che suggerisce che tra due approcci o spiegazioni, quella più semplice è la scelta migliore. Contrariamente ad altri modelli di deep learning per il riconoscimento delle emozioni, perciò, il loro modello è mantenuto relativamente semplice. La rete neurale apprende un numero limitato di parametri dal set di dati e impiega strategie di apprendimento di base.
"La rete proposta è composta da livelli di elaborazione in cascata che astraggono le informazioni, dal segnale alla sua interpretazione, " ha detto Jurie. "Audio e video vengono elaborati da due diversi canali della rete e sono combinati ultimamente nel processo, quasi alla fine».
Quando testato, il loro modello di luce ha raggiunto una promettente precisione nel riconoscimento delle emozioni del 60,64 percento. Si è anche classificato quarto alla sfida 2018 Emotion Recognition in the Wild (EmotiW), tenutosi all'ACM International Conference on Multimodal Interaction (ICMI), in Colorado.

Illustrazione di come questo spazio 2D può essere utilizzato per controllare le emozioni espresse dai volti, in modo continuo, con l'ausilio di reti generative avversarie (GAN). Credito:Jurie et al.
"Il nostro modello è la prova che seguendo il principio del rasoio di Occam, cioè., scegliendo sempre le alternative più semplici per la progettazione di reti neurali, è possibile limitare le dimensioni dei modelli e ottenere reti neurali molto compatte ma all'avanguardia, che sono più facili da addestrare, " ha detto Jurie. "Questo contrasta con la tendenza della ricerca di rendere le reti neurali sempre più grandi".
I ricercatori continueranno ora a esplorare modi per ottenere un'elevata precisione nel riconoscimento delle emozioni analizzando simultaneamente i dati visivi e uditivi, utilizzando i set di dati di addestramento annotati limitati attualmente disponibili.
"Siamo interessati a diverse direzioni di ricerca, come come fondere al meglio le diverse modalità, come rappresentare l'emozione mediante descrittori completi semanticamente di significato compatto (e non solo etichette di classe) o come rendere i nostri algoritmi in grado di apprendere con meno, o anche senza, dati annotati, " ha detto Giuria.
© 2018 Tech Xplore