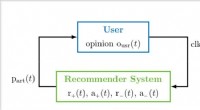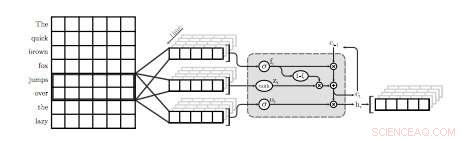
Un'illustrazione del primo strato QRNN per la modellazione del linguaggio. In questa visualizzazione, uno strato QRNN con una dimensione della finestra di due convoluzioni e piscine utilizzando gli embedding dall'input. Si noti l'assenza di pesi ricorrenti. Credito:Tang &Lin.
Un team di ricercatori dell'Università di Waterloo in Canada ha recentemente condotto uno studio che esplora i compromessi tra precisione ed efficienza dei modelli di linguaggio neurale (NLM) specificamente applicati ai dispositivi mobili. Nella loro carta, che è stato pre-pubblicato su arXiv, i ricercatori hanno proposto anche una semplice tecnica per recuperare qualche perplessità, una misura delle prestazioni di un modello linguistico, utilizzando una quantità trascurabile di memoria.
Gli NLM sono modelli linguistici basati su reti neurali attraverso i quali gli algoritmi possono apprendere la distribuzione tipica di sequenze di parole e fare previsioni sulla parola successiva in una frase. Questi modelli hanno una serie di applicazioni utili, ad esempio, abilitare tastiere software più intelligenti per telefoni cellulari o altri dispositivi.
"I modelli del linguaggio neurale (NLM) esistono in uno spazio di compromesso tra precisione ed efficienza in cui una migliore perplessità viene in genere a scapito di una maggiore complessità di calcolo, " hanno scritto i ricercatori nel loro articolo. "In un'applicazione di tastiera software su dispositivi mobili, questo si traduce in un maggiore consumo energetico e una durata della batteria più breve."
Se applicato alle tastiere software, Gli NLM possono portare a una previsione della parola successiva più accurata, consentendo agli utenti di inserire la parola successiva in una determinata frase con un solo tocco. Due applicazioni esistenti che utilizzano le reti neurali per fornire questa funzionalità sono SwiftKey1 e Swype2. Però, queste applicazioni spesso richiedono molta potenza per funzionare, scaricando rapidamente le batterie dei dispositivi mobili.
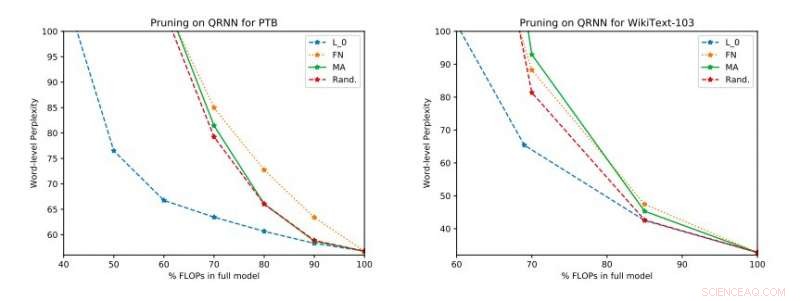
Risultati sperimentali completi su Penn Treebank e WikiText-103. Illustriamo lo spazio del compromesso perplessità-efficienza sul set di test ottenuto prima di applicare l'aggiornamento a livello singolo. Credito:Tang &Lin.
"Sulla base di metriche standard come perplessità, le tecniche neurali rappresentano un progresso nella modellazione del linguaggio allo stato dell'arte, " hanno spiegato i ricercatori nel loro articolo. "Modelli migliori, però, comportare un costo in termini di complessità computazionale, che si traduce in un maggiore consumo di energia. Nel contesto dei dispositivi mobili, l'efficienza energetica è Certo, un importante obiettivo di ottimizzazione."
Secondo i ricercatori, Gli NLM finora sono stati valutati principalmente nel contesto del riconoscimento delle immagini e dell'individuazione delle parole chiave, mentre il loro compromesso tra precisione ed efficienza nelle applicazioni di elaborazione del linguaggio naturale (NLP) non è stato ancora studiato a fondo. Il loro studio si concentra su questa area di ricerca inesplorata, effettuare una valutazione degli NLM e dei loro compromessi tra precisione ed efficienza su un Raspberry Pi.
"Le nostre valutazioni empiriche considerano sia le perplessità che il consumo di energia su un Raspberry Pi, dove dimostriamo quali metodi forniscono il miglior punto operativo perplessità-consumo energetico, " hanno detto i ricercatori. "A un certo punto operativo, una delle tecniche è in grado di fornire un risparmio energetico del 40 percento rispetto ai [metodi] all'avanguardia con solo un aumento relativo della perplessità del 17 percento."
Nel loro studio, i ricercatori hanno anche valutato una serie di tecniche di potatura del tempo di inferenza su reti neurali quasi ricorrenti (QRNN). Estendere l'usabilità dei metodi di potatura del tempo di formazione esistenti ai QRNN in fase di esecuzione, hanno raggiunto diversi punti operativi all'interno dello spazio di compromesso tra precisione ed efficienza. Per migliorare le prestazioni utilizzando una piccola quantità di memoria, hanno suggerito la formazione e la memorizzazione di aggiornamenti di peso a livello singolo nei punti operativi desiderati.
© 2018 Tech Xplore