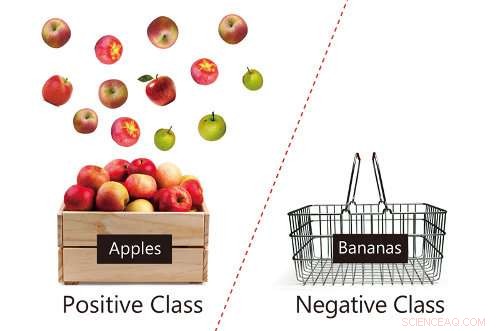
Schema che mostra dati positivi (mele) e una mancanza di dati negativi (banane), con un'illustrazione della confidenza dei dati Apple. Attestazione:RIKEN
Un team di ricerca del RIKEN Center for Advanced Intelligence Project (AIP) ha sviluppato con successo un nuovo metodo per l'apprendimento automatico che consente a un'intelligenza artificiale di effettuare classificazioni senza i cosiddetti "dati negativi, " una scoperta che potrebbe portare a un'applicazione più ampia a una varietà di compiti di classificazione.
Classificare le cose è fondamentale per la nostra vita quotidiana. Per esempio, dobbiamo rilevare la posta indesiderata, notizie politiche false, così come cose più banali come oggetti o volti. Quando si utilizza l'intelligenza artificiale, tali compiti si basano sulla "tecnologia di classificazione" nell'apprendimento automatico, facendo in modo che il computer impari utilizzando il confine che separa i dati positivi e negativi. Per esempio, i dati "positivi" sarebbero foto con una faccia felice, e foto di dati "negativi" che includono una faccia triste. Una volta appreso un confine di classificazione, il computer può determinare se un dato dato è positivo o negativo. La difficoltà con questa tecnologia è che richiede dati sia positivi che negativi per il processo di apprendimento, e i dati negativi non sono disponibili in molti casi (ad esempio, è difficile trovare foto con l'etichetta, "questa foto include una faccia triste, " poiché la maggior parte delle persone sorride davanti a una telecamera.)
In termini di programmi di vita reale, quando un rivenditore sta cercando di prevedere chi effettuerà un acquisto, può facilmente trovare dati sui clienti che hanno acquistato da loro (dati positivi), ma è sostanzialmente impossibile ottenere dati su clienti che non hanno acquistato da loro (dati negativi), poiché non hanno accesso ai dati dei loro concorrenti. Un altro esempio è un'attività comune per gli sviluppatori di app:devono prevedere quali utenti continueranno a utilizzare l'app (positivo) o interromperanno (negativo). Però, quando un utente si disiscrive, gli sviluppatori perdono i dati dell'utente perché devono eliminare completamente i dati relativi a quell'utente in conformità con l'informativa sulla privacy per proteggere le informazioni personali.
Secondo l'autore principale Takashi Ishida di RIKEN AIP, "I metodi di classificazione precedenti non potevano far fronte alla situazione in cui non erano disponibili dati negativi, ma abbiamo reso possibile ai computer di apprendere solo con dati positivi, purché disponiamo di un punteggio di confidenza per i nostri dati positivi, costruito da informazioni come l'intenzione di acquisto o il tasso attivo degli utenti dell'app. Utilizzando il nostro nuovo metodo, possiamo lasciare che i computer imparino un classificatore solo da dati positivi dotati di fiducia."
Ishida ha proposto, insieme al ricercatore Gang Niu del suo gruppo e capogruppo Masashi Sugiyama, che consentono ai computer di apprendere bene aggiungendo il punteggio di confidenza, che matematicamente corrisponde alla probabilità che i dati appartengano o meno a una classe positiva. Sono riusciti a sviluppare un metodo che consente ai computer di apprendere un confine di classificazione solo da dati positivi e informazioni sulla sua fiducia (affidabilità positiva) contro i problemi di classificazione dell'apprendimento automatico che dividono i dati positivamente e negativamente.
Per vedere come funzionava il sistema, l'hanno usato su un set di foto che contiene varie etichette di articoli di moda. Per esempio, hanno scelto "T-shirt, " come la classe positiva e un altro elemento, per esempio., "sandalo", come classe negativa. Quindi hanno allegato un punteggio di fiducia alle foto della "t-shirt". Hanno scoperto che senza accedere ai dati negativi (ad es. foto "sandali"), in alcuni casi, il loro metodo era buono quanto un metodo che prevede l'utilizzo di dati positivi e negativi.
Secondo Ishida, "Questa scoperta potrebbe ampliare la gamma di applicazioni in cui è possibile utilizzare la tecnologia di classificazione. Anche nei campi in cui l'apprendimento automatico è stato utilizzato attivamente, la nostra tecnologia di classificazione potrebbe essere utilizzata in nuove situazioni in cui è possibile raccogliere solo dati positivi a causa della regolamentazione dei dati o dei vincoli aziendali. Nel futuro prossimo, speriamo di poter utilizzare la nostra tecnologia in vari campi di ricerca, come l'elaborazione del linguaggio naturale, visione computerizzata, robotica, e bioinformatica".