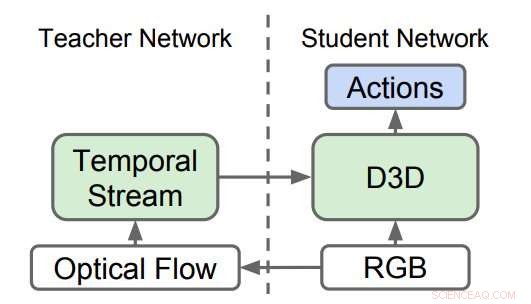
Reti 3D distillate (D3D). I ricercatori hanno addestrato una CNN 3D a riconoscere le azioni da video RGB mentre distillano la conoscenza da una rete che riconosce le azioni da sequenze di flusso ottico. Durante l'inferenza, viene utilizzato solo D3D. Credito:Stroud et al.
Un team di ricercatori di Google, l'Università del Michigan e l'Università di Princeton hanno recentemente sviluppato un nuovo metodo per il riconoscimento delle azioni video. Il riconoscimento delle azioni video comporta l'identificazione di particolari azioni eseguite nelle riprese video, come aprire una porta, chiudere una porta, eccetera.
Da anni i ricercatori cercano di insegnare ai computer a riconoscere le azioni umane e non umane in video. La maggior parte degli strumenti di riconoscimento delle azioni video all'avanguardia impiega un insieme di due reti neurali:il flusso spaziale e il flusso temporale.
In questi approcci, una rete neurale è addestrata a riconoscere le azioni in un flusso di immagini regolari in base all'aspetto (cioè il "flusso spaziale") e la seconda rete è addestrata a riconoscere le azioni in un flusso di dati di movimento (cioè il "flusso temporale"). I risultati ottenuti da queste due reti vengono quindi combinati per ottenere il riconoscimento dell'azione video.
Sebbene i risultati empirici ottenuti utilizzando approcci "a due flussi" siano ottimi, questi metodi si basano su due reti distinte, piuttosto che uno solo. L'obiettivo dello studio condotto dai ricercatori di Google, l'Università del Michigan e Princeton doveva studiare modi per migliorare questo, al fine di sostituire i due flussi della maggior parte degli approcci esistenti con un'unica rete che apprende direttamente dai dati.
Negli studi più recenti, entrambi i flussi spaziali e temporali sono costituiti da reti neurali convoluzionali 3D (CNN), che applicano filtri spaziotemporali al video clip prima di tentare la classificazione. Teoricamente, questi filtri temporali applicati dovrebbero consentire al flusso spaziale di apprendere le rappresentazioni del movimento, quindi il flusso temporale non dovrebbe essere necessario.
In pratica, però, le prestazioni degli strumenti di riconoscimento delle azioni video migliorano quando viene incluso un flusso temporale completamente separato. Ciò suggerisce che il flusso spaziale da solo non è in grado di rilevare alcuni dei segnali catturati dal flusso temporale.
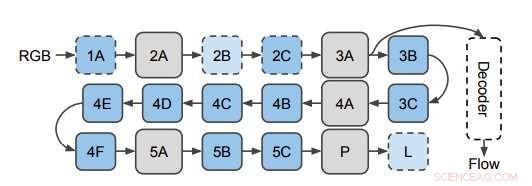
La rete utilizzata per prevedere il flusso ottico dalle funzionalità CNN 3D. I ricercatori applicano il decodificatore a livelli nascosti nella CNN 3D (raffigurata qui al livello 3A). Questo diagramma mostra la struttura di I3D/S3D-G, dove le caselle blu rappresentano la convoluzione (linee tratteggiate) o i blocchi Inception (linee continue), e le caselle grigie rappresentano i blocchi di pooling. I nomi dei livelli sono gli stessi utilizzati in Inception. Credito:Stroud et al.
Per esaminare ulteriormente questa osservazione, i ricercatori hanno studiato se il flusso spaziale delle CNN 3D per il riconoscimento dell'azione video sia effettivamente privo di rappresentazioni del movimento. Successivamente, hanno dimostrato che queste rappresentazioni del movimento possono essere migliorate usando la distillazione, una tecnica per comprimere la conoscenza in un insieme in un unico modello.
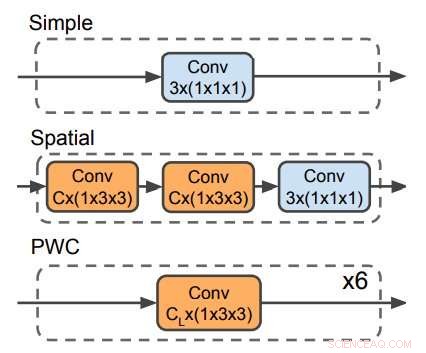
Tre decodificatori utilizzati per prevedere il flusso ottico. Il decodificatore PWC assomiglia alla rete di previsione del flusso ottico di PWC-net. Nessun decoder fa uso di filtri temporali. Credito:Stroud et al.
I ricercatori hanno formato una rete di "insegnanti" per riconoscere le azioni in base all'input del movimento. Quindi, hanno formato una seconda rete di "studenti", che viene alimentato solo dal flusso di immagini regolari, con un duplice obiettivo:svolgere bene il compito di riconoscimento dell'azione e imitare l'output della rete di insegnanti. Essenzialmente, la rete studentesca impara a riconoscere in base sia all'aspetto che al movimento, meglio dell'insegnante e così come i modelli a due flussi più grandi e ingombranti.
Recentemente, una serie di studi ha anche testato un approccio alternativo per il riconoscimento delle azioni video, che comporta l'addestramento di una singola rete con due obiettivi diversi:eseguire bene l'attività di riconoscimento dell'azione e prevedere direttamente i segnali di movimento di basso livello (cioè il flusso ottico) nel video. I ricercatori hanno scoperto che il loro metodo di distillazione ha superato questo approccio. Ciò suggerisce che è meno importante per una rete riconoscere efficacemente il flusso ottico di basso livello in un video rispetto a riprodurre la conoscenza di alto livello che la rete di insegnanti ha appreso sul riconoscimento delle azioni dal movimento.
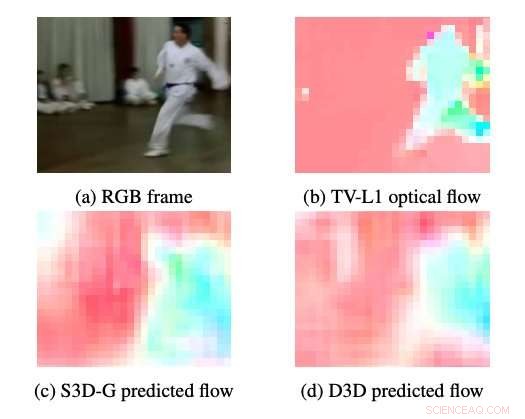
Esempi di flusso ottico prodotto da S3DG e D3D (senza messa a punto) utilizzando il decoder PWC applicato allo strato 3A. Il colore e la saturazione di ciascun pixel corrispondono all'angolo e all'ampiezza del movimento, rispettivamente. Il flusso ottico TV-L1 viene visualizzato a 28 × 28 px, la risoluzione di uscita del decoder. Credito:Stroud et al.
I ricercatori hanno dimostrato che è possibile addestrare una rete neurale a flusso singolo che si comporta così come approcci a due flussi. I loro risultati suggeriscono che le prestazioni degli attuali metodi all'avanguardia per il riconoscimento delle azioni video potrebbero essere ottenute utilizzando circa 1/3 del calcolo. Ciò semplificherebbe l'esecuzione di questi modelli su dispositivi con vincoli di elaborazione, come smartphone, e su scala più ampia (ad esempio per identificare azioni, come "schiacciate", nei video di YouTube).
Globale, questo recente studio mette in evidenza alcune delle carenze dei metodi di riconoscimento delle azioni video esistenti, proponendo un nuovo approccio che prevede la formazione di un docente e di una rete di studenti. Ricerca futura, però, potrebbe cercare di ottenere prestazioni all'avanguardia senza la necessità di una rete di insegnanti, fornendo i dati di formazione direttamente alla rete degli studenti.
© 2019 Science X Network