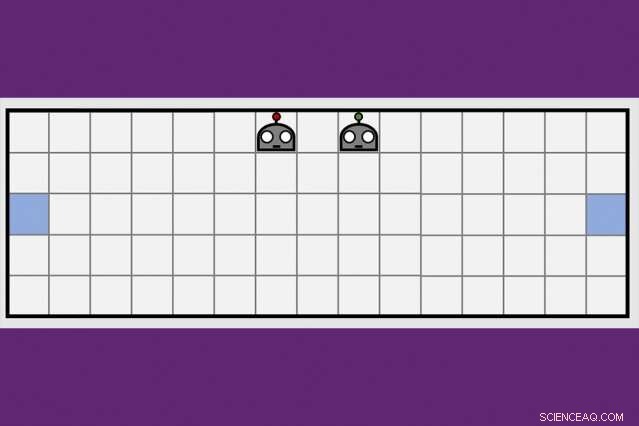
Utilizzando una nuova tecnica di apprendimento cooperativo, I ricercatori del Watson AI Lab del MIT-IBM hanno ridotto della metà il tempo impiegato da una coppia di agenti robot per imparare a manovrare ai lati opposti di una stanza virtuale. Credito:Dong-ki Kim
I primi programmi di intelligenza artificiale per sconfiggere i migliori giocatori del mondo a scacchi e il gioco Go hanno ricevuto almeno alcune istruzioni dagli umani, e alla fine, non si dimostrerebbe all'altezza di una nuova generazione di programmi di intelligenza artificiale che apprendono completamente da soli, attraverso tentativi ed errori.
Una combinazione di algoritmi di apprendimento profondo e apprendimento per rinforzo è responsabile del raggiungimento del dominio dei computer in giochi da tavolo impegnativi come scacchi e Go, un numero crescente di videogiochi, inclusa la signora Pac-Man, e alcuni giochi di carte, compreso il poker. Ma per tutti i progressi, i computer continuano a bloccarsi quanto più un gioco assomiglia alla vita reale, con informazioni nascoste, più giocatori, gioco continuo, e un mix di ricompense a breve e lungo termine che rendono il calcolo la mossa ottimale irrimediabilmente complessa.
Per superare questi ostacoli, I ricercatori di intelligenza artificiale stanno esplorando tecniche complementari per aiutare gli agenti robot ad apprendere, modellato sul modo in cui gli umani raccolgono nuove informazioni non solo da soli, ma dalle persone intorno a noi, e dai giornali, libri, e altri mezzi di comunicazione. Una strategia di apprendimento collettivo sviluppata dal MIT-IBM Watson AI Lab offre una nuova direzione promettente. I ricercatori mostrano che una coppia di agenti robot può ridurre del 50% o più il tempo necessario per apprendere una semplice attività di navigazione quando gli agenti imparano a sfruttare il crescente corpo di conoscenze dell'altro.
L'algoritmo insegna agli agenti quando chiedere aiuto, e come adattare i loro consigli a ciò che è stato appreso fino a quel momento. L'algoritmo è unico in quanto nessuno dei due agenti è un esperto; ognuno è libero di agire come studente-insegnante per richiedere e offrire maggiori informazioni. I ricercatori presenteranno il loro lavoro questa settimana alla Conferenza AAAI sull'intelligenza artificiale alle Hawaii.
Coautori del documento, che ha ricevuto una menzione d'onore per il miglior articolo studentesco all'AAAI, sono Jonathan Come, un professore nel Dipartimento di Aeronautica e Astronautica del MIT; Shayegan Omidshafiei, un ex studente laureato del MIT ora presso DeepMind di Alphabet; Dong-ki Kim del MIT; Miao Liu, Gerald Tesauro, Matteo Riemer, e Murray Campbell di IBM; e Christopher Amato della Northeastern University.
"Questa idea di fornire azioni per migliorare maggiormente l'apprendimento dello studente, piuttosto che dirgli semplicemente cosa fare, è potenzialmente abbastanza potente, " dice Matthew E. Taylor, un direttore di ricerca presso Borealis AI, il braccio di ricerca della Royal Bank of Canada, che non è stato coinvolto nella ricerca. "Mentre il documento si concentra su scenari relativamente semplici, Credo che il framework studente/insegnante potrebbe essere ampliato e utile nei videogiochi multiplayer come Dota 2, calcio robot, o scenari di ripristino di emergenza".
Per adesso, i professionisti hanno ancora il vantaggio in Dota2, e altri giochi virtuali che favoriscono il lavoro di squadra e la rapidità, pensiero strategico. (Sebbene il braccio di ricerca sull'intelligenza artificiale di Alphabet, mente profonda, ha recentemente fatto notizia dopo aver sconfitto un giocatore professionista nel gioco di strategia in tempo reale, Starcraft.) Ma poiché le macchine migliorano nel manovrare ambienti dinamici, potrebbero presto essere pronti per compiti del mondo reale come la gestione del traffico in una grande città o il coordinamento di squadre di ricerca e soccorso a terra e in aria.
"Le macchine mancano della conoscenza del buon senso che sviluppiamo da bambini, "dice Liu, un ex postdoc del MIT ora al laboratorio MIT-IBM. "Ecco perché hanno bisogno di guardare milioni di fotogrammi video, e dedicare molto tempo di calcolo, imparare a giocare bene. Anche allora, non hanno modi efficienti per trasferire le loro conoscenze al team, o generalizzare le proprie abilità in un nuovo gioco. Se possiamo addestrare i robot ad imparare dagli altri, e generalizzare il loro apprendimento ad altri compiti, possiamo iniziare a coordinare meglio le loro interazioni tra loro, e con gli umani".
L'intuizione chiave del team MIT-IBM è stata che un team che divide e vince per imparare un nuovo compito, in questo caso, manovrando alle estremità opposte di una stanza e toccando il muro allo stesso tempo, imparerai più velocemente.
Il loro algoritmo di insegnamento alterna due fasi. Nel primo, sia lo studente che l'insegnante decidono con ogni rispettivo passaggio se chiedere, o dare, consigli basati sulla loro fiducia che la prossima mossa, o il consiglio che stanno per dare, li avvicinerà al loro obiettivo. Così, lo studente chiede solo consigli, e l'insegnante lo dà solo, quando è probabile che le informazioni aggiunte migliorino le loro prestazioni. Ad ogni passo, gli agenti aggiornano le rispettive policy di attività e il processo continua fino a quando non raggiungono il loro obiettivo o fino allo scadere del tempo.
Ad ogni iterazione, l'algoritmo registra le decisioni dello studente, il consiglio dell'insegnante, e il loro progresso di apprendimento misurato dal punteggio finale del gioco. Nella seconda fase, una tecnica di apprendimento per rinforzo profondo utilizza i dati di insegnamento precedentemente registrati per aggiornare entrambe le politiche di consulenza. "Con ogni aggiornamento l'insegnante migliora nel dare i consigli giusti al momento giusto, "dice Kim, uno studente laureato al MIT.
In un documento di follow-up da discutere in un workshop presso AAAI, i ricercatori migliorano la capacità dell'algoritmo di tracciare quanto bene gli agenti stanno imparando il compito sottostante, in questo caso, un compito impegnativo, per migliorare la capacità degli agenti di dare e ricevere consigli. È un altro passo che avvicina la squadra al suo obiettivo a lungo termine di entrare nella RoboCup, una competizione annuale di robotica avviata da ricercatori accademici di intelligenza artificiale.
"Dovremmo passare a 11 agenti prima di poter giocare una partita di calcio, "dice Tesauro, un ricercatore IBM che ha sviluppato il primo programma di intelligenza artificiale per padroneggiare il gioco del backgammon. "Ci vorrà ancora un po' di lavoro, ma siamo fiduciosi".
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.














