Credito:CC0 Dominio pubblico
Un team di ricercatori dell'UC Santa Cruz ha recentemente sviluppato un nuovo approccio di apprendimento automatico per caratterizzare la felicità, chiamato CruzAffect. Il loro approccio, presentato in un articolo pre-pubblicato su arXiv, può essere applicato a diversi modelli di classificazione dei contenuti affettivi, inclusi sia i classificatori tradizionali che le reti neurali convoluzionali di deep learning (CNN).
Questo recente studio si basa su ricerche precedenti che hanno esplorato il modo in cui le persone trasmettono l'affetto e la felicità in prima persona. In uno studio, gli stessi ricercatori hanno scoperto che le persone tendono a descrivere situazioni, come "il mio amico mi ha comprato dei fiori", o "Ho una multa per il parcheggio", da cui altri umani possono facilmente dedurre le loro reazioni affettive implicite. Hanno concluso che la semantica compositiva può fornire una forte evidenza del sentimento associato a un dato evento.

Credito:Wu et al.
In un altro studio, i ricercatori hanno cercato di basare le descrizioni linguistiche degli eventi delle persone sulle teorie del benessere e della felicità. Analizzando un corpus di micro-blog privati estratti da un'applicazione chiamata Echo, hanno esaminato la misura in cui diversi resoconti teorici potrebbero spiegare la varianza nei punteggi di felicità che gli utenti di Echo attribuivano agli eventi quotidiani della loro vita.
"È difficile generalizzare un evento affettivo e associarlo a teorie del benessere, "Jiaqi Wu, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Nella nostra ricerca passata, abbiamo notato che non esiste una sola teoria in grado di predire il sentimento di tutti gli eventi affettivi. Lo scopo del nostro recente lavoro era identificare semantiche compositive specifiche che caratterizzano il sentimento degli eventi e tentare di modellare la felicità a un livello più elevato di generalizzazione. Però, trovare caratteristiche generiche per modellare il benessere rimane difficile".
L'obiettivo principale del recente studio condotto da Wu e dai suoi colleghi era quello di indagare l'efficacia dei tradizionali metodi di apprendimento automatico ricchi di funzionalità e dei metodi di deep learning per la classificazione dei contenuti affettivi. Per realizzare questo, hanno identificato una serie di caratteristiche che caratterizzano la felicità nei contenuti affettivi e le hanno applicate a un classificatore tradizionale, XGbosco potenziato, e una CNN.
"Il nostro progetto, chiamato CruzAffect, include lo sviluppo di due diversi modelli:un metodo di machine learning tradizionale (ovvero XGBoosted forest) e una CNN di deep learning con incorporamento GloVe, " Wu ha detto. "Utilizziamo caratteristiche sintattiche, caratteristiche emotive, e caratteristiche del profilo, e le loro prestazioni sono stabili per diverse attività di classificazione dei contenuti affettivi."
Essenzialmente, i ricercatori hanno valutato le prestazioni di due diversi modelli di apprendimento automatico per la classificazione dei contenuti affettivi (foresta XGBoosted e CNN), entrambi i quali hanno analizzato il contenuto in base alle caratteristiche che avevano precedentemente identificato. Questi includono:
Queste caratteristiche hanno permesso ai ricercatori di scoprire indicatori essenziali di coinvolgimento sociale e controllo che diverse persone potrebbero esercitare durante i momenti felici. Nel loro studio, hanno addestrato sia il modello XGBoosted che quello della CNN con l'apprendimento supervisionato su un set di dati di 10, 000 frammenti di testo etichettati. Hanno anche addestrato i modelli a generare pseudo-etichette per 70, 000 frammenti non etichettati utilizzando un approccio semi-supervisionato bootstrap, in quanto ciò ha permesso loro di ampliare il proprio set di dati. Tutti questi frammenti di testo sono stati estratti dal database HappyDB.

Architettura della CNN. Credito:Wu et al.
"I risultati significativi del nostro studio includono gli interessanti modelli sintattici che si ripetono su diversi domini, " Wu ha detto. "È probabile che tali modelli linguistici siano associati alle teorie del benessere. Troviamo anche che le caratteristiche che includono la conoscenza di esperti, come il dizionario LIWC può migliorare le prestazioni del modello tradizionale e del modello di deep learning nelle attività di classificazione dei contenuti affettivi."
I ricercatori hanno valutato i modelli XGBoosted della foresta e della CNN sulla classificazione binaria di agenzie e etichette sociali, così come sulla previsione multiclasse delle etichette concettuali. Le loro valutazioni hanno prodotto risultati promettenti, suggerendo che le caratteristiche da loro individuate sono particolarmente efficaci per classificare i contenuti affettivi. Sebbene il modello basato sulla CNN abbia ottenuto risultati migliori su compiti di classificazione multiclasse, il modello tradizionale di machine learning ha ottenuto risultati comparabili utilizzando le caratteristiche che avevano precedentemente identificato.
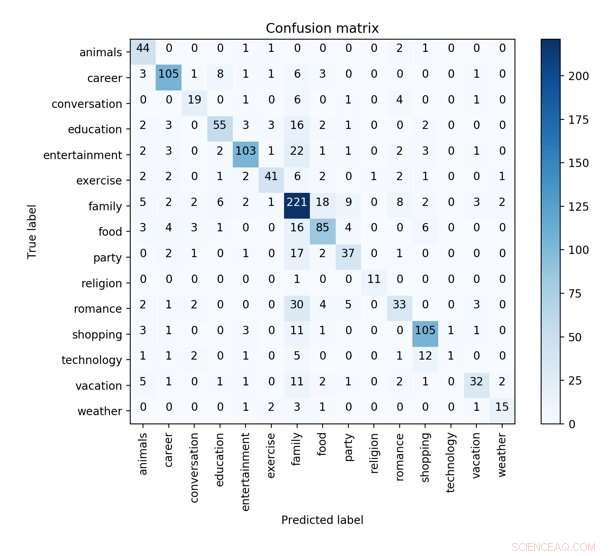
La matrice di confusione del miglior modello CNN con sintattica, caratteristiche emotive e di profilo nella convalida incrociata di 10 volte per prevedere la caratteristica dei concetti. Credito:Wu et al.
Lo studio condotto da Wu e dai suoi colleghi ha scoperto temi generali che sono ricorrenti nelle descrizioni dei momenti felici delle persone. Nel futuro, le loro scoperte potrebbero informare lo sviluppo di nuovi modelli per compiti di classificazione affettiva, consentendo ai ricercatori di prevedere efficacemente il benessere e la felicità analizzando il contenuto di frammenti di testo.
"Ora esplorerò l'analisi degli eventi affettivi interdominio, e indagare un modello migliore per radicare le descrizioni linguistiche degli eventi che gli utenti sperimentano nelle teorie del benessere e della felicità, " Wu ha detto. "Dopo aver compreso la relazione tra il contenuto affettivo e le teorie del benessere, potremmo essere in grado di raccogliere eventi affettivi generali che sono altamente legati al benessere".

Il team di ricercatori che ha condotto lo studio. Credito:Wu et al.
© 2019 Science X Network