Brookhaven Lab ha collaborato con la Columbia University, Università di Edimburgo, e Intel per ottimizzare le prestazioni di un computer parallelo a 144 nodi costruito con processori Xeon Phi di Intel e rete di comunicazione ad alta velocità Omni-Path. Il computer è installato presso lo Scientific Data and Computing Center di Brookhaven, come visto sopra con l'ingegnere tecnologico Costin Caramarcu. Credito:Brookhaven National Laboratory
Il calcolo ad alte prestazioni (HPC), l'uso di supercomputer e tecniche di elaborazione parallela per risolvere grandi problemi computazionali, è di grande utilità nella comunità scientifica. Per esempio, gli scienziati del Brookhaven National Laboratory del Dipartimento dell'Energia degli Stati Uniti (DOE) si affidano all'HPC per analizzare i dati che raccolgono presso le strutture sperimentali su larga scala in loco e per modellare processi complessi che sarebbero troppo costosi o impossibili da dimostrare sperimentalmente.
Applicazioni della scienza moderna, come simulare interazioni tra particelle, spesso richiedono una combinazione di potenza di calcolo aggregata, reti ad alta velocità per il trasferimento dei dati, grandi quantità di memoria, e capacità di archiviazione ad alta capacità. Per soddisfare questi requisiti sono necessari progressi nell'hardware e nel software HPC. Gli scienziati informatici e computazionali e i matematici della Computational Science Initiative (CSI) del Brookhaven Lab stanno collaborando con fisici, biologi, e altri scienziati del settore per comprendere le loro esigenze di analisi dei dati e fornire soluzioni per accelerare il processo di scoperta scientifica.
Un leader del settore HPC
Per decenni, Intel Corporation è stata uno dei leader nello sviluppo di tecnologie HPC. Nel 2016, la società ha rilasciato i processori Intel Xeon PhiTM (precedentemente nome in codice "Knights Landing"), la sua architettura HPC di seconda generazione che integra molte unità di elaborazione (core) per chip. Lo stesso anno, Intel ha rilasciato la rete di comunicazione ad alta velocità Intel Omni-Path Architecture. Affinché il 5, da 000 a 100, 000 singoli computer, o nodi, nei moderni supercomputer per lavorare insieme per risolvere un problema, devono essere in grado di comunicare rapidamente tra loro riducendo al minimo i ritardi di rete.
Subito dopo questi rilasci, Brookhaven Lab e RIKEN, Il più grande istituto di ricerca globale del Giappone, hanno unito le loro risorse per acquistare un piccolo computer parallelo a 144 nodi costruito con processori Xeon Phi e due connessioni di rete indipendenti, o binari, utilizzando l'architettura Omni-Path di Intel. Il computer è stato installato presso lo Scientific Data and Computing Center di Brookhaven Lab, che fa parte del CSI.
Un'immagine del die del processore Xeon Phi Knights Landing. Un die è un modello su un wafer di materiale semiconduttore che contiene i circuiti elettronici per eseguire una particolare funzione. Credito:Intel
Con l'installazione completata, il fisico Chulwoo Jung e lo scienziato computazionale CSI Meifeng Lin del Brookhaven Lab; fisico teorico Christoph Lehner, un incaricato congiunto al Brookhaven Lab e all'Università di Regensburg in Germania; Cristo normanno, l'Ephraim Gildor Professor di Fisica Teorica Computazionale alla Columbia University; e il fisico teorico delle particelle Peter Boyle dell'Università di Edimburgo ha lavorato in stretta collaborazione con gli ingegneri del software di Intel per ottimizzare il software di rete per due applicazioni scientifiche:fisica delle particelle e apprendimento automatico.
"CSI era molto interessato all'architettura Intel Omni-Path da quando è stata annunciata nel 2015, " ha affermato Lin. "L'esperienza degli ingegneri Intel è stata fondamentale per implementare le ottimizzazioni software che ci hanno permesso di sfruttare appieno questa rete di comunicazione ad alte prestazioni per le nostre specifiche esigenze applicative".
Requisiti di rete per applicazioni scientifiche
Per molte applicazioni scientifiche, l'esecuzione di un rango (un valore che distingue un processo da un altro) o eventualmente di alcuni ranghi per nodo su un computer parallelo è molto più efficiente rispetto all'esecuzione di più ranghi per nodo. Ogni rango viene in genere eseguito come un processo indipendente che comunica con gli altri ranghi utilizzando un protocollo standard noto come Message Passing Interface (MPI).
Per esempio, i fisici che cercano di capire come si è formato l'universo primordiale eseguono complesse simulazioni numeriche delle interazioni tra particelle basate sulla teoria della cromodinamica quantistica (QCD). Questa teoria spiega come le particelle elementari chiamate quark e gluoni interagiscono per formare le particelle che osserviamo direttamente, come protoni e neutroni. I fisici modellano queste interazioni utilizzando supercomputer che rappresentano le tre dimensioni dello spazio e la dimensione del tempo in un reticolo quadridimensionale (4-D) di punti equidistanti, simile a quello di un cristallo. Il reticolo è suddiviso in sottovolumi identici più piccoli. Per i calcoli QCD reticolari, i dati devono essere scambiati ai confini tra i diversi sottovolumi. Se ci sono più ranghi per nodo, ogni rango ospita un diverso sotto-volume 4-D. Così, la suddivisione dei sotto-volumi crea più confini in cui i dati devono essere scambiati e quindi trasferimenti di dati non necessari che rallentano i calcoli.
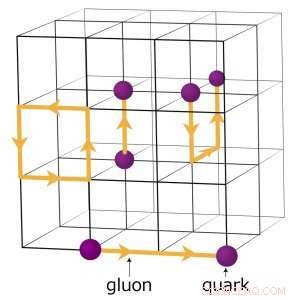
Uno schema del reticolo per i calcoli della cromodinamica quantistica. I punti di intersezione sulla griglia rappresentano i valori dei quark, mentre le linee tra di loro rappresentano i valori dei gluoni. Credito:Brookhaven National Laboratory
Ottimizzazioni del software per far progredire la scienza
Per ottimizzare il software di rete per un'applicazione scientifica ad alta intensità di calcolo, il team si è concentrato sul miglioramento della velocità di un singolo grado.
"Abbiamo reso più veloce il codice per un singolo rank MPI in modo che non fosse necessaria una proliferazione di rank MPI per gestire il grande carico di comunicazione presente per ciascun nodo, "ha spiegato Cristo.
Il software all'interno del rank MPI sfrutta il parallelismo a thread disponibile sui nodi Xeon Phi. Il parallelismo threaded si riferisce all'esecuzione simultanea di più processi, o fili, che seguono le stesse istruzioni condividendo alcune risorse informatiche. Con il software ottimizzato, il team è stato in grado di creare più canali di comunicazione su un singolo rango e di guidare questi canali utilizzando thread diversi.
Il software MPI è stato ora configurato per consentire alle applicazioni scientifiche di funzionare più rapidamente e sfruttare appieno l'hardware di comunicazione Intel Omni-Path. Ma dopo aver implementato il software, i membri del team hanno affrontato un'altra sfida:in ogni run, alcuni nodi avrebbero inevitabilmente comunicato lentamente e trattenuto gli altri.
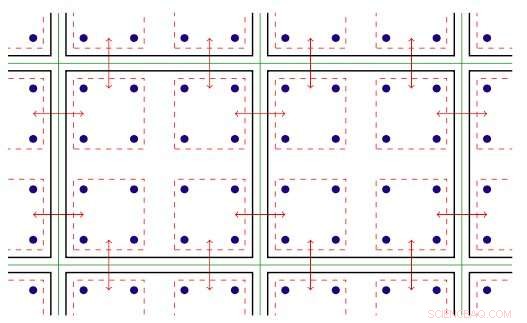
Illustrazione bidimensionale del parallelismo filettato. Chiave:le linee verdi separano i nodi di calcolo fisici; le linee nere separano i ranghi MPI; le linee rosse sono i contesti di comunicazione, con le frecce che indicano la comunicazione tra i nodi o la copia della memoria all'interno di un nodo tramite l'hardware Intel Omni-Path. Credito:Brookhaven National Laboratory
Hanno fatto risalire questo problema al modo in cui Linux, il sistema operativo utilizzato dalla maggior parte delle piattaforme HPC, gestisce la memoria. Nella sua modalità predefinita, Linux divide la memoria in piccoli blocchi chiamati pagine. Riconfigurando Linux per utilizzare pagine di memoria grandi ("enormi"), hanno risolto il problema. L'aumento delle dimensioni della pagina significa che sono necessarie meno pagine per mappare lo spazio di indirizzi virtuali utilizzato da un'applicazione. Di conseguenza, è possibile accedere alla memoria molto più rapidamente.
Con i miglioramenti del software, i membri del team hanno analizzato le prestazioni dell'architettura Intel Omni-Path e dei nodi di elaborazione del processore Intel Xeon Phi installati sul cluster "Diamond" dual-rail di Intel e sul cluster single-rail DiRAC (Distributed Research Using Advanced Computing) nel Regno Unito. Per la loro analisi, hanno usato due diverse classi di applicazioni scientifiche:fisica delle particelle e apprendimento automatico. Per entrambi i codici applicazione, hanno raggiunto prestazioni simili alla velocità del cavo, la velocità massima teorica di trasferimento dei dati. Questo miglioramento rappresenta un aumento delle prestazioni di rete che è tra quattro e dieci volte quello dei codici originali.
"Grazie alla stretta collaborazione tra Brookhaven, Edimburgo, e Intel, queste ottimizzazioni sono state rese disponibili in tutto il mondo in una nuova versione dell'implementazione Intel Omni-Path MPI e un protocollo di best practice per configurare la gestione della memoria di Linux, " disse Christ. "Il fattore cinque di velocità nell'esecuzione del codice di fisica sul computer Xeon Phi del Brookhaven Lab e sul nuovo, un computer "ipercubo" Hewlett Packard Enterprise da 800 nodi ancora più grande viene ora utilizzato per studi in corso su questioni fondamentali nella fisica delle particelle".