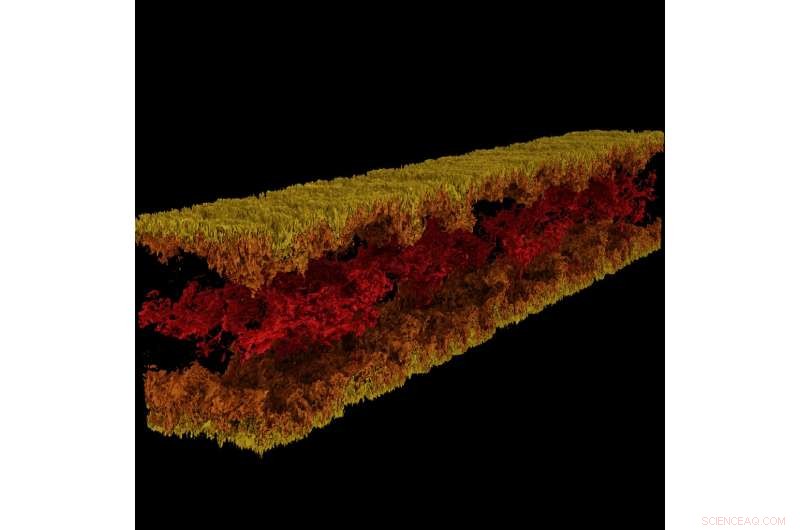
Visualizzazione del flusso del canale turbolento prodotta utilizzando GraviT. Credito:Visualizzazione:Texas Advanced Computing Center. Dati:CIEM, L'Università del Texas ad Austin.
Grande, la scienza di impatto richiede un intero ecosistema tecnologico per progredire. Ciò include sistemi informatici all'avanguardia, archiviazione ad alta capacità, reti ad alta velocità, potenza, raffreddamento... l'elenco potrebbe continuare all'infinito.
criticamente, richiede anche software all'avanguardia:programmi che lavorano insieme senza soluzione di continuità per consentire a scienziati e ingegneri di rispondere a domande difficili, condividere le loro soluzioni, e condurre ricerche con la massima efficienza e il minimo dolore.
Per alimentare questa modalità critica di progresso scientifico, nel 2012 NSF ha istituito il programma Software Infrastructure for Sustained Innovation (SI2), con l'obiettivo di trasformare le innovazioni nella ricerca e nell'istruzione in risorse software sostenute che sono parte integrante della cyberinfrastruttura.
"La scoperta scientifica e l'innovazione stanno avanzando lungo percorsi fondamentalmente nuovi aperti dallo sviluppo di software sempre più sofisticati, " La National Science Foundation (NSF) ha scritto nella sollecitazione del programma SI2. "Il software è anche direttamente responsabile dell'aumento della produttività scientifica e del significativo miglioramento delle capacità dei ricercatori".
Con cinque attuali premi SI2, e ruoli collaborativi su molti altri, il Texas Advanced Computing Center (TACC) è tra i leader nazionali nello sviluppo di software per l'informatica scientifica. I principali investigatori di TACC presenteranno il loro lavoro dal 30 aprile al 2 maggio alla riunione dei principali investigatori NSF SI2 2018 a Washington, D.C.
"Parte della missione di TACC è migliorare la produttività dei ricercatori che utilizzano i nostri sistemi, "ha detto Bill Barth, Direttore TACC del calcolo ad alte prestazioni e un passato beneficiario di sovvenzioni SI2. "Il programma SI2 ci ha aiutato a farlo supportando gli sforzi per sviluppare nuovi strumenti ed estendendo gli strumenti esistenti con prestazioni aggiuntive e funzionalità di usabilità".
Dai framework per la visualizzazione su larga scala agli strumenti di parallelizzazione automatica e altro ancora, Il software sviluppato da TACC sta cambiando il modo in cui i ricercatori elaborano in futuro.
Strumento di parallelizzazione interattivo
La potenza dei supercomputer risiede principalmente nella loro capacità di risolvere equazioni matematiche in parallelo. Prendi un problema difficile, dividerlo nelle sue parti costitutive, risolvere ogni parte individualmente e riunire di nuovo le risposte:questo è il calcolo parallelo nella sua essenza. Però, il compito di organizzare il proprio problema in modo che possa essere affrontato da un supercomputer non è facile, anche per scienziati computazionali esperti.
Ritu Arora, un ricercatore presso TACC, ha lavorato per abbassare l'asticella del calcolo parallelo sviluppando uno strumento in grado di trasformare un codice seriale, che può utilizzare un solo processore alla volta, in un codice parallelo che può utilizzare da decine a migliaia di processori. Lo strumento analizza un'applicazione seriale, sollecita ulteriori informazioni da parte dell'utente, applica l'euristica incorporata, e genera una versione parallela dell'applicazione seriale di input.
Arora e i suoi collaboratori hanno distribuito l'attuale versione di IPT nel cloud in modo che i ricercatori possano utilizzarla comodamente tramite un browser web. I ricercatori possono generare versioni parallele del loro codice in modo semiautomatico e testare il codice parallelo per verificarne l'accuratezza e le prestazioni su risorse TACC e XSEDE, compreso Stampede2, stella solitaria5, e Cometa.
"L'entità dell'impatto sociale dell'IPT è una funzione diretta dell'importanza dell'HPC nelle STEM e nei domini non tradizionali emergenti, e le ripide sfide che gli esperti di dominio e gli studenti affrontano nel salire la curva di apprendimento per la programmazione parallela, " ha detto Arora. "Oltre a ridurre il time-to-development e il tempo di esecuzione delle applicazioni su piattaforme HPC, IPT ridurrà il consumo di energia e massimizzerà le prestazioni fornite dalle piattaforme HPC attraverso la sua capacità di generare codice ibrido".

GraviT ha consentito ai ricercatori di produrre visualizzazioni di ray tracing utilizzando i dati prodotti da Enzo, un codice di simulazione progettato per ricchi, calcoli astrofisici idrodinamici multifisici. Credito:Università del Texas ad Austin
Come esempio delle capacità di IPT, Arora indica un recente tentativo di parallelizzare un'applicazione di dinamica molecolare (MD). Parallelizzando l'applicazione seriale utilizzando OpenMP a un alto livello di astrazione, ovvero senza che l'utente conoscesse la sintassi di basso livello di OpenMP, hanno ottenuto un'accelerazione dell'88% nel codice.
Hanno anche quantificato l'impatto dell'IPT in termini di produttività dell'utente misurando il numero di righe di codice che un ricercatore deve scrivere durante il processo di parallelizzazione manuale di un'applicazione rispetto all'utilizzo dell'IPT.
"Nei nostri casi di prova, IPT ha migliorato la produttività degli utenti di oltre il 90%, rispetto alla scrittura manuale del codice, e ha generato il codice parallelo che rientra nel 10% delle prestazioni del miglior codice parallelo scritto a mano disponibile per tali applicazioni, " ha detto Arora. "Siamo molto contenti del suo successo finora."
TACC sta estendendo l'IPT per supportare ulteriori tipi di applicazioni seriali e applicazioni che mostrano modelli di comunicazione e calcolo irregolari.
(Guarda un video dimostrativo di IPT in cui TACC mostra il processo di parallelizzazione di un'applicazione di dinamica molecolare con il modello di programmazione OpenMP.)
GraviT
La visualizzazione scientifica, il processo di trasformazione dei dati grezzi in immagini interpretabili, è un aspetto chiave della ricerca. Però, può essere difficile quando si tenta di visualizzare set di dati su scala petabyte distribuiti tra molti nodi di un cluster di elaborazione. Ancora di più quando si tenta di utilizzare metodi di visualizzazione avanzati come il ray tracing, una tecnica per generare un'immagine tracciando il percorso della luce come pixel in un piano dell'immagine e simulando gli effetti dei suoi incontri con oggetti virtuali.
Per affrontare questo problema, Paolo Navratil, direttore della visualizzazione presso TACC, ha condotto uno sforzo per creare GraviT, uno scalabile, framework di ray tracing a memoria distribuita e libreria software per applicazioni che comprendono dati così grandi da non poter risiedere nella memoria di un singolo nodo di calcolo. I collaboratori del progetto includono Hank Childs (Università dell'Oregon), Chuck Hansen (University of Utah), Matt Turk (National Center for Supercomputing Applications) and Allen Malony (ParaTools).
GraviT works across a variety of hardware platforms, including the Intel Xeon processors and NVIDIA GPUs. It can also function in heterogeneous computing environments, Per esempio, hybrid CPU and GPU systems. GraviT has been successfully integrated into the GLuRay OpenGL-based ray tracing interface, the VisIt visualization toolkit, the VTK visualization toolkit, and the yt visualization framework.
"High-fidelity rendering techniques like ray tracing improve visual analysis by providing the same spatial cues of light and shadow that we see in the world around us, but these are challenging to use in distributed contexts, " said Navratil. "GraviT enables these techniques to be used efficiently across distributed computing resources, unlocking their potential for large scale analysis and to be used in situ, where data is not written to disk prior to analysis."
(The GraviT source code is available at the TACC GitHub site ).
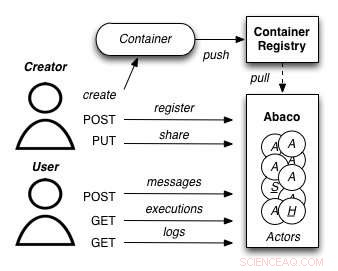
A diagram showing how the Abaco "Actor" model works. Credit:University of Texas at Austin
Abaco
The increased availability of data has enabled entirely new kinds of analyses to emerge, yielding answers to many important questions. Però, these analyses are complex and frequently require advanced computer science expertise to run correctly.
Joe Stubbs, who leads TACC's Cloud and Interactive Computing (CIC) group, is working on a project that simplifies how researchers create analysis tools that are reliable and scalable. Il progetto, known as Abaco, adapts the "Actor" model, whereby software systems are designed as a collection of simple functions, which can then be provided as a cloud-based capability on high performance computing environments.
"Abaco significantly simplifies the way scientific software is developed and used, " said Stubbs. "Scientific software developers will find it much easier to design and implement a system. Ulteriore, scientists and researchers that use software will be able to easily compose collections of actors with pre-determined functionality in order to get the computation and data they need."
The Abaco API (application programming interface) combines technologies and techniques from cloud computing, including Linux Containers and the "functions-as-a-service" paradigm, with the Actor model for concurrent computation. Investigators addressing grand challenge problems in synthetic biology, earthquake engineering and food safety are already using the tool to advance their work. Stubbs is working to extend Abaco's ability to do data federation and discoverability, so Abaco programs can be used to build federated datasets consisting of separate datasets from all over the internet.
"By reducing the barriers to developing and using such services, this project will boost the productivity of scientists and engineers working on the problems of today, and better prepare them to tackle the new problems of tomorrow, " Stubbs said.
Expanding volunteer computing
Volunteer computing uses donated computing time on consumer devices such as home computers and smartphones to conduct scientific investigations. Early successes from this approach include the discovery of the structure of an enzyme involved in reproduction of HIV by FoldIt participants; and the detection of pulsars using Einstein@Home.
Volunteer computing can provide greater computing power, at lower cost, than conventional approaches such as organizational computing centers and commercial clouds, but participation in volunteer computing efforts is yet to reach its full potential.
TACC is partnering with the University of California at Berkeley and Purdue University to build new capabilities for BOINC (the most common software framework used for volunteer computing) to grow this promising mode of distributed computing. The project involves two complementary development efforts. Primo, it adds BOINC-based volunteer computing conduits to two major high-performance computing providers:TACC and nanoHUB, a web portal for nano science that provides computing capabilities. In questo modo, the project benefits the thousands of scientists who use these facilities and creates technologies that make it easy for other HPC providers to add their own volunteer computing capability to their systems.
Secondo, the team will develop a unified interface for volunteer computing, tentatively called Science United, where donors can register to participate and scientists can market their volunteer computing projects to the public.
TACC is currently setting up a BOINC server on Jetstream and using containerization technologies, such as Docker and VirtualBox, to build and package popular applications that can run in high-throughput computing mode on the devices of volunteers. Initial applications being tested include AutoDock Vina, used for drug discovery, and OpenSees, used by the natural hazards community. Come passo successivo, TACC will develop the plumbing required for selecting and routing qualified jobs from TACC resources to the BOINC server.
"By creating a huge pool of low-cost computing power that will benefit thousands of scientists, and increasing public awareness of and interest in science, the project plans to establish volunteer computing as a central and long-term part of the U.S. scientific cyber infrastructure, " said David Anderson, the lead principal investigator on the project from UC Berkeley.