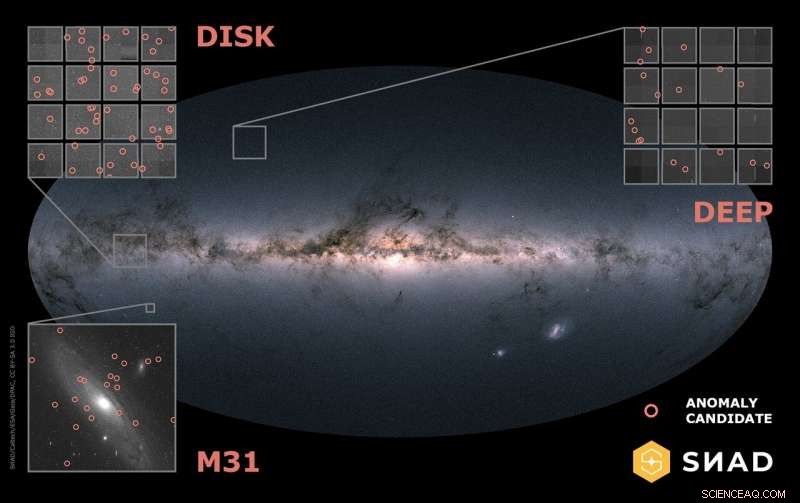
Localizzazione di tre campi ZTF analizzati in questo lavoro con candidati ad anomalia marcati. Attestazione:Maria Pruzhinskaya (2020)
Il team SNAD, una rete internazionale formata da ricercatori russi, Francia e Stati Uniti, ha sviluppato una pipeline per trovare oggetti rari ed esotici tra i pagliai di dati provenienti da rilievi astronomici.
Data la dimensione sempre crescente dei set di dati astronomici, anche se i nostri telescopi rilevano fenomeni astronomici interessanti inaspettati, è molto improbabile che saremo in grado di riconoscerli nel mezzo di milioni o addirittura miliardi di osservazioni. La soluzione risiede in strumenti automatici appositamente progettati per riconoscere comportamenti insoliti nascosti tra miliardi di misurazioni. Alcuni di questi strumenti esistono già e vengono utilizzati, Per esempio, per identificare le attività fraudolente della carta di credito tra milioni di transazioni ogni giorno. Però, il loro adattamento ai dati scientifici non è semplice a causa delle complicazioni derivanti dalla natura delle osservazioni in astronomia. Il team SNAD ha lavorato per 3 anni nello sviluppo e nell'adattamento di tali soluzioni al contesto dell'astronomia.
Durante il loro ultimo incontro annuale, il gruppo ha concentrato i propri sforzi su oggetti la cui luminosità varia nel tempo. La pipeline combina i punti di forza degli algoritmi di apprendimento automatico e la conoscenza insostituibile di esperti umani per creare un robusto strumento di rilevamento delle anomalie. L'articolo descrive i risultati dell'applicazione di questo framework alla terza versione di dati della Zwicky Transient Facility. Il suo processo in tre fasi prevedeva l'estrazione delle caratteristiche sulle curve di luce (che traccia la luminosità degli oggetti nel tempo), ricerca di candidati con anomalia utilizzando diversi algoritmi di apprendimento automatico e filtrando manualmente i candidati da parte di un esperto umano. Quest'ultima fase includeva anche l'esecuzione di osservazioni con altri telescopi, quando possibile. In questo studio, Sono stati utilizzati 4 algoritmi di apprendimento automatico per contrassegnare 277 anomalie candidate per l'indagine umana, su un set di dati iniziale di 2,25 milioni di oggetti.
Il gruppo ha anche sviluppato un'interfaccia web appositamente progettata che ha permesso la visualizzazione immediata e il cross-match di ciascun candidato con i cataloghi astronomici esistenti. Questo è stato costruito per facilitare il lavoro degli esperti che hanno bisogno di correlare i candidati all'anomalia con qualsiasi altra informazione pubblicamente disponibile sulle coordinate celesti oggetto di indagine.
Dei 277 oggetti considerati anomali dalla macchina, 188 (68%) hanno mostrato caratteristiche insolite dovute a effetti non astrofisici (inclusi difetti dovuti alla pipeline di sottrazione dell'immagine di ZTF), 66 (24%) erano oggetti già catalogati in precedenza e 23 (8%) erano oggetti precedentemente sconosciuti. La prima categoria comprende alcune curiosità divertenti e gli ultimi due casi di interesse scientifico. Per esempio, un oggetto segnalato come anomalia dalla macchina era in realtà l'occultazione di una stella sullo sfondo da parte dell'asteroide di Barcellona, che dal punto di vista di un osservatore dalla Terra è stata rilevata come una sorgente puntiforme variabile quando in realtà né la stella né l'asteroide hanno effettivamente cambiato luminosità. Gli autori hanno anche caratterizzato artefatti di sottrazione di immagini ricorrenti ed esotici che interferiscono con l'analisi della curva di luce e possono indurre una pipeline di rilevamento di anomalie a pensare che sia reale, oggetto anomalo. Al fine di aiutare a classificare rapidamente la prima classe dai restanti candidati, sono stati in grado di identificare una semplice relazione bidimensionale che può essere utilizzata per aiutare a filtrare curve di luce potenzialmente fasulle negli studi futuri.
Tra la seconda e la terza categoria, gli autori hanno trovato quattro supernovae candidate, sei binarie ad eclisse precedentemente non classificati, quattro candidati pre-sequenza principale, un possibile bagliore della nana rossa, e ha confermato spettroscopicamente una stella RS Canum Venaticorum, tra gli altri candidati anomali.
La separazione rapida e senza sforzo di artefatti da interessanti candidati ad anomalie è cruciale per gli osservatori attuali e di prossima generazione, come il Vera Rubin Observatory Legacy Survey of Space and Time (LSST). LSST genererà circa 10 milioni di sorgenti transitorie per notte:saranno necessari algoritmi sofisticati e robusti per vagliare tutti quei dati in modo da non perdere oggetti inaspettati e interessanti, e gli scienziati possono comprendere meglio queste stranezze spaziali.
L'autore principale Konstantin Malanchev, ricercatore presso l'Università dell'Illinois a Urbana-Champaign (USA) e l'istituto astronomico Sternberg del Lomonosov Mosca (Russia), dice, "Progettare strumenti specificamente dedicati alla ricerca di anomalie astrofisiche interessanti è la nostra unica opzione per garantire il pieno sfruttamento dei set di dati che abbiamo lottato così duramente per acquisire. Il team SNAD è pienamente impegnato ad aiutare la comunità astronomica ad esplorare il pieno potenziale dei futuri set di dati. ."
L'articolo è stato accettato per la pubblicazione in Avvisi mensili della Royal Astronomical Society ed è anche pubblicamente disponibile come prestampa. Il codice sorgente e i risultati, compreso un elenco completo di oggetti con potenziale applicazione scientifica, così come le tecniche di pipeline, sono aperti al pubblico a beneficio e verifica da parte della comunità astronomica.