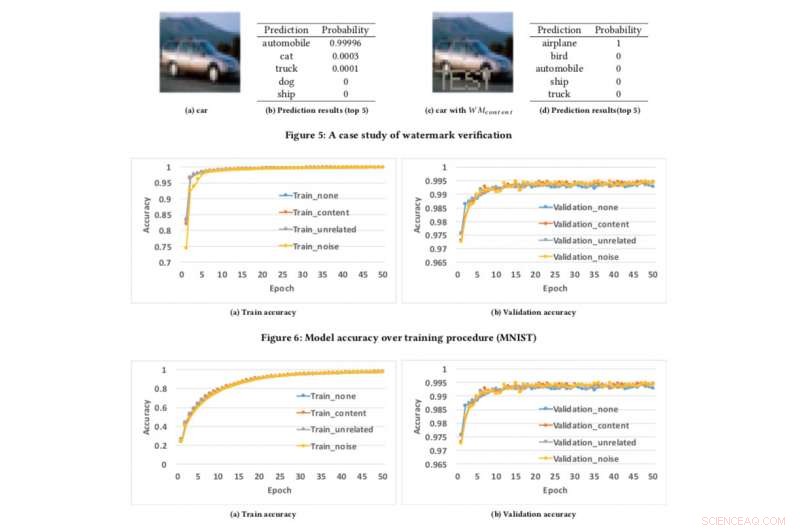
Precisione del modello rispetto alla procedura di addestramento. Credito:CIFAR10
Se possiamo proteggere i video, audio e foto con filigrana digitale, perché non i modelli di intelligenza artificiale?
Questa è la domanda che io e i miei colleghi ci siamo posti mentre cercavamo di sviluppare una tecnica per assicurare agli sviluppatori che il loro duro lavoro nella costruzione dell'IA, come modelli di deep learning, può essere protetto. potresti pensare, "Protetto da cosa?" Bene, Per esempio, cosa succede se il tuo modello di intelligenza artificiale viene rubato o utilizzato in modo improprio per scopi nefasti, come offrire un servizio plagiato costruito su un modello rubato? Questa è una preoccupazione, in particolare per i leader dell'IA come IBM.
All'inizio di questo mese abbiamo presentato la nostra ricerca alla conferenza AsiaCCS '18 a Incheon, Repubblica di Corea, e siamo orgogliosi di affermare che la nostra tecnica di valutazione completa per affrontare questa sfida si è dimostrata altamente efficace e robusta. La nostra innovazione chiave è che il nostro concetto può verificare in remoto la proprietà dei servizi di rete neurale profonda (DNN) utilizzando semplici query API.
Man mano che i modelli di deep learning vengono distribuiti più ampiamente e diventano più preziosi, sono sempre più presi di mira dagli avversari. La nostra idea, che è in attesa di brevetto, prende ispirazione dalle popolari tecniche di watermarking utilizzate per i contenuti multimediali, come video e foto.
Quando si filigrana una foto ci sono due fasi:incorporamento e rilevamento. Nella fase di inclusione, i proprietari possono sovrapporre la parola "COPYRIGHT" sulla foto (o filigrane invisibili alla percezione umana) e se viene rubata e utilizzata da altri lo confermiamo in fase di rilevamento, per cui i proprietari possono estrarre le filigrane come prove legali per dimostrare la proprietà. La stessa idea può essere applicata a DNN.
Incorporando filigrane nei modelli DNN, se vengono rubati, possiamo verificarne la titolarità estraendo filigrane dai modelli. Però, diverso dalla filigrana digitale, che incorpora filigrane nei contenuti multimediali, avevamo bisogno di progettare un nuovo metodo per incorporare filigrane nei modelli DNN.
Nel nostro giornale, descriviamo un approccio per infondere filigrane nei modelli DNN, e progettare un meccanismo di verifica remota per determinare la proprietà dei modelli DNN utilizzando le chiamate API.
Abbiamo sviluppato tre algoritmi di generazione di filigrane per generare diversi tipi di filigrane per i modelli DNN:
Per testare il nostro framework di watermarking, abbiamo usato due set di dati pubblici:MNIST, un set di dati di riconoscimento delle cifre scritto a mano che ha 60, 000 immagini di formazione e 10, 000 immagini di prova e CIFAR10, un set di dati di classificazione degli oggetti con 50, 000 immagini di formazione e 10, 000 immagini di prova.
L'esecuzione dell'esperimento è piuttosto semplice:forniamo semplicemente al DNN un'immagine appositamente predisposta, che attiva una risposta inaspettata ma controllata se il modello è stato contrassegnato con filigrana. Non è la prima volta che viene presa in considerazione la filigrana, ma i concetti precedenti erano limitati richiedendo l'accesso ai parametri del modello. Però, nel mondo reale, i modelli rubati vengono solitamente distribuiti in remoto, e il servizio plagiato non pubblicizzerebbe i parametri dei modelli rubati. Inoltre, le filigrane incorporate nei modelli DNN sono robuste e resilienti a diversi meccanismi di contro-filigrana, come la messa a punto, potatura parametrica, e attacchi di inversione del modello.
ahimè, il nostro framework ha alcune limitazioni. Se il modello trapelato non viene distribuito come servizio online ma utilizzato come servizio interno, quindi non possiamo rilevare alcun furto, ma poi ovviamente il plagiatore non può monetizzare direttamente i modelli rubati.
Inoltre, il nostro attuale framework di watermarking non può proteggere i modelli DNN dal furto tramite API di previsione, per cui gli aggressori possono sfruttare la tensione tra l'accesso alle query e la riservatezza nei risultati per apprendere i parametri dei modelli di apprendimento automatico. Però, tali attacchi hanno dimostrato di funzionare bene nella pratica solo per algoritmi di machine learning convenzionali con meno parametri del modello come alberi decisionali e regressioni logistiche.
Attualmente stiamo cercando di implementarlo all'interno di IBM ed esplorare come la tecnologia può essere fornita come servizio per i clienti.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.