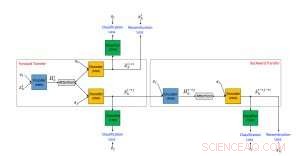
Framework proposto di un algoritmo di trasferimento di stile di testo neurale utilizzando dati non paralleli. Credito:IBM
I social media online sono diventati uno dei modi più importanti per comunicare e scambiare idee. Sfortunatamente, il discorso è spesso paralizzato da un linguaggio offensivo che può avere effetti dannosi sugli utenti dei social media. Ad esempio, un recente sondaggio di YouGov.uk ha scoperto che, tra le informazioni che i datori di lavoro possono trovare online sui candidati al lavoro, un linguaggio aggressivo o offensivo è l'attività sui social media più dannosa dal punto di vista professionale. Le reti di social media online normalmente affrontano il problema del linguaggio offensivo semplicemente filtrando un post quando è contrassegnato come offensivo.
Nel documento "Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer, " che è stato presentato nella 56a riunione annuale dell'Associazione per la linguistica computazionale (ACL 2018), introduciamo un approccio completamente nuovo per affrontare questo problema. Il nostro approccio utilizza il trasferimento di stile di testo non supervisionato per tradurre frasi offensive nelle corrispondenti forme non offensive. Al meglio delle nostre conoscenze, tutto il lavoro precedente che ha affrontato il problema del linguaggio offensivo sui social media si è concentrato solo sulla classificazione del testo. Tali metodi possono quindi essere utilizzati principalmente per segnalare e filtrare i contenuti offensivi, ma il nostro approccio proposto fa un passo avanti e produce una versione alternativa non offensiva del contenuto. Questo ha due potenziali vantaggi per gli utenti dei social media. Per quegli utenti che intendono pubblicare un messaggio offensivo, ricevere un avviso che il contenuto è offensivo e verrà bloccato, insieme a una versione più educata del messaggio che può essere postata, potrebbe incoraggiarli a cambiare idea ed evitare le parolacce. Inoltre, per gli utenti che consumano contenuti online, questo permette loro di vedere e capire ancora il messaggio ma in un tono non offensivo ed educato.
Un'architettura per sostituire il linguaggio offensivo
Il nostro metodo si basa sull'ormai popolare architettura di rete neurale codificatore-decodificatore, che è l'approccio più avanzato per la traduzione automatica. Nella traduzione automatica, l'addestramento della rete neurale codificatore-decodificatore presuppone l'esistenza di una "Rosetta Stone" in cui lo stesso testo è scritto sia nella lingua di partenza che in quella di destinazione. Questi dati accoppiati consentono agli sviluppatori di determinare facilmente se un sistema si traduce correttamente e quindi addestrare un sistema di codifica-decodificatore per funzionare bene. Sfortunatamente, a differenza della traduzione automatica, per quanto ne sappiamo, non esiste un dataset di dati accoppiati disponibili per il caso di condanne da offensive a non offensive. Inoltre, il testo trasferito deve utilizzare un vocabolario comune in un particolare dominio applicativo. Perciò, sono necessari metodi non supervisionati che non utilizzano dati accoppiati per eseguire questa attività.

Abbiamo proposto un approccio di trasferimento dello stile di testo non supervisionato composto da tre componenti principali, ciascuno assegnato un compito separato durante la formazione. Uno (un codificatore RNN) analizza una frase offensiva e comprime le informazioni più rilevanti in un vettore di valore reale. Questo viene letto da un altro componente (un decodificatore RNN), che genera una nuova frase che è la versione tradotta di quella originale. La frase tradotta viene quindi valutata dal terzo componente (un classificatore della CNN) per identificare se l'output è stato correttamente tradotto dallo stile offensivo a quello non offensivo. Inoltre, la frase generata viene anche "retrotradotta" da non offensiva ad offensiva e confrontata con la frase originale per verificare se il contenuto è stato preservato. Se i risultati di una delle suddette valutazioni contengono errori, il sistema viene regolato di conseguenza. L'encoder e il decoder sono anche, in parallelo, addestrato utilizzando un setup di autoencoding in cui l'obiettivo consiste nel ricostruire la frase di input. Usiamo anche il meccanismo di attenzione che aiuta a garantire la conservazione dei contenuti. Il nostro principale contributo in termini di architettura è l'uso combinato di un classificatore collaborativo, Attenzione, e retrocessione.
Tradurre un linguaggio offensivo
Abbiamo testato il nostro metodo proposto utilizzando i dati di due popolari reti di social media:Twitter e Reddit. Abbiamo creato set di dati di testi offensivi e non offensivi classificando circa 10 milioni di post utilizzando un classificatore di linguaggio offensivo proposto da Davidson et al. (2017). La tabella seguente mostra esempi di frasi offensive originali e traduzioni non offensive generate da un metodo di trasferimento dello stile di testo proposto da Shen et al. (2017) e dal nostro approccio. Il nostro sistema ha dimostrato prestazioni migliori nella traduzione di frasi offensive in non offensive, preservando il contenuto complessivo, ma a volte produce frasi strane.
Questo lavoro è un primo passo nella direzione di un nuovo approccio promettente per combattere i post offensivi sui social media. Il trasferimento di stile di testo non supervisionato è un'area di ricerca che ha appena iniziato a vedere alcuni risultati promettenti. Il nostro lavoro è una buona prova del concetto che gli attuali metodi di trasferimento dello stile di testo non supervisionato possono essere applicati a compiti utili. Però, è importante notare che gli attuali approcci al trasferimento dello stile di testo non supervisionato possono gestire bene solo i casi in cui il problema del linguaggio offensivo è lessicale (come gli esempi mostrati nella tabella) e può essere risolto modificando o rimuovendo alcune parole. I modelli che abbiamo utilizzato non saranno efficaci nei casi di pregiudizio implicito in cui le parole normalmente inoffensive vengono usate in modo offensivo.
Riteniamo che versioni migliorate del metodo proposto, insieme all'uso di volumi molto più grandi di dati di allenamento, sarà in grado di far fronte ad altri post offensivi come post contenenti incitamento all'odio, razzismo, e sessismo. Immaginiamo che il nostro metodo possa essere utilizzato per migliorare l'IA conversazionale, assicurando che i chatbot che apprendono interagendo con gli utenti online non riproducano in seguito un linguaggio offensivo e incitamento all'odio. Il controllo parentale è un altro potenziale utilizzo del sistema proposto.
Questa storia è stata ripubblicata per gentile concessione di IBM Research.