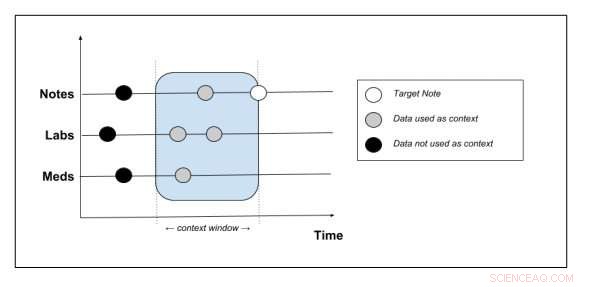
Schema che mostra quali dati di contesto vengono estratti dalla cartella del paziente. Credito:Peter Liu
I medici attualmente trascorrono molto tempo a scrivere note sui pazienti e a inserirle nei sistemi di cartelle cliniche elettroniche (EHR). Secondo uno studio del 2016, i medici dedicano circa due ore al lavoro amministrativo per ogni ora trascorsa con un paziente. Grazie a strumenti di intelligenza artificiale all'avanguardia, questo processo di scrittura delle note potrebbe presto diventare automatizzato, aiutando i medici a gestire meglio i loro turni e sollevandoli da questo noioso compito.
Pietro Liu, un ricercatore presso Google Brain, ha recentemente sviluppato un nuovo compito di modellazione del linguaggio in grado di prevedere il contenuto di nuove note analizzando le cartelle cliniche dei pazienti, che includono dati come dati demografici, misurazioni di laboratorio, farmaci e note precedenti. Nel suo studio, pre-pubblicato su arXiv, ha addestrato modelli generativi utilizzando il set di dati EHR MIMIC-III (Medical Information Mart for Intensive Care), e quindi confrontato le note generate dai modelli con le note reali del dataset.
I metodi comunemente adottati per ridurre il tempo che i medici trascorrono per prendere appunti includono l'uso di servizi di dettatura e l'impiego di assistenti che possono scrivere appunti per loro. Gli strumenti di intelligenza artificiale potrebbero aiutare ad affrontare questo problema, riducendo i costi spesi per personale e risorse aggiuntive.
"Funzioni di scrittura assistita per le note, come il completamento automatico o il controllo degli errori, beneficiare di modelli linguistici, " Liu scrive nel suo articolo. "Più forte è il modello, più efficaci sarebbero tali caratteristiche. Così, l'obiettivo di questo documento è la costruzione di modelli linguistici per le note cliniche".
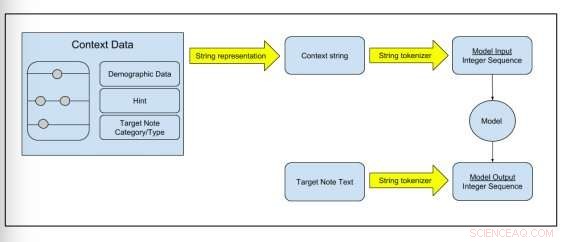
Figura 2:Schema che mostra come i dati grezzi vengono trasformati in dati di addestramento del modello. Credito:Peter Liu
Liu ha utilizzato due modelli linguistici:il primo è chiamato architettura del trasformatore, ed è stato introdotto in uno studio pubblicato lo scorso anno nel Progressi nei sistemi di elaborazione delle informazioni neurali rivista. Poiché questo modello offre prestazioni migliori con testi più brevi, come singole frasi, ha anche testato un modello basato su trasformatore di recente introduzione, chiamato trasformatore con attenzione compressa dalla memoria (T-DMCA), che è risultato essere più efficace per sequenze più lunghe.
Ha addestrato questi modelli sul set di dati MIMIC-III, contenente EHR non identificato di 39, 597 pazienti del reparto di terapia intensiva di un ospedale di cure terziarie. Questo è attualmente il set di dati EHR più completo disponibile pubblicamente e facilmente accessibile online.
"Abbiamo introdotto una nuova attività di modellazione del linguaggio per le note cliniche basata sui dati HER e mostrato come rappresentare il contesto dei dati multimodali nel modello, " Liu ha spiegato nel suo articolo. "Abbiamo proposto metriche di valutazione per l'attività e presentato risultati incoraggianti che mostrano il potere predittivo di tali modelli".
I modelli erano effettivamente in grado di prevedere molto del contenuto delle note dei medici. In futuro, potrebbero aiutare lo sviluppo di funzioni di controllo ortografico e di completamento automatico più sofisticate. Queste funzionalità potrebbero quindi essere integrate in strumenti che assistono i medici nel completamento del lavoro amministrativo. Sebbene i risultati di questo studio siano promettenti, alcune sfide devono ancora essere superate prima che i modelli possano essere impiegati su scala più ampia.
"In molti casi, il contesto massimo fornito dalla EHR è insufficiente per prevedere pienamente la nota, " Liu spiega nel suo articolo. "Il caso più evidente è la mancanza di dati di imaging in MIMIC-III per i rapporti di radiologia. Per le note non di imaging mancano anche informazioni sulle ultime interazioni paziente-fornitore. Il lavoro futuro potrebbe tentare di aumentare il contesto della nota con dati al di là dell'EHR, per esempio. dati di imaging, o trascrizioni delle interazioni medico-paziente. Sebbene abbiamo discusso della correzione degli errori e delle funzionalità di completamento automatico nel software EHR, i loro effetti sulla produttività degli utenti non sono stati misurati nel contesto clinico, che lasciamo come lavoro futuro."
© 2018 Tech Xplore














