Richiesta mostrata ai medici per le annotazioni. Credito:IBM
I tempi recenti hanno assistito a progressi significativi nella comprensione del linguaggio naturale da parte dell'IA, come la traduzione automatica e la risposta alle domande. Una ragione fondamentale alla base di questi sviluppi è la creazione di set di dati, che utilizzano modelli di machine learning per apprendere ed eseguire un compito specifico. La costruzione di tali set di dati nel dominio aperto spesso consiste in testo proveniente da articoli di notizie. Questo è in genere seguito dalla raccolta di annotazioni umane da piattaforme di crowdsourcing come Crowdflower, o Amazon Mechanical Turk.
Però, il linguaggio utilizzato in ambiti specializzati come la medicina è completamente diverso. Il vocabolario usato da un medico mentre scrive una nota clinica è abbastanza diverso dalle parole di un articolo di notizie. Così, le attività linguistiche in questi domini ad alta intensità di conoscenza non possono essere crowd-sourced poiché tali annotazioni richiedono competenze di dominio. Però, anche la raccolta di annotazioni da esperti di dominio è molto costosa. Inoltre, i dati clinici sono sensibili alla privacy e quindi non possono essere condivisi facilmente. Questi ostacoli hanno inibito il contributo dei dataset linguistici nel dominio medico. A causa di queste sfide, la convalida di algoritmi ad alte prestazioni dal dominio aperto sui dati clinici rimane non indagata.
Per colmare queste lacune, abbiamo lavorato con il Massachusetts Institute of Technology per costruire MedNLI, un set di dati annotato dai medici, svolgere un compito di inferenza del linguaggio naturale (NLI) e radicato nella storia medica dei pazienti. Più importante, lo rendiamo pubblicamente disponibile per i ricercatori per far progredire l'elaborazione del linguaggio naturale in medicina.
Abbiamo lavorato con i laboratori di ricerca del MIT Critical Data per costruire un set di dati per l'inferenza del linguaggio naturale in medicina. Abbiamo usato le note cliniche dal loro database "Medical Information Mart for Intensive Care" (MIMIC), che è probabilmente il più grande database pubblicamente disponibile di cartelle cliniche. I medici del nostro team hanno suggerito che la storia medica passata di un paziente contiene informazioni vitali da cui si possono trarre utili deduzioni. Perciò, abbiamo estratto la storia medica passata dalle note cliniche in MIMIC e presentato una frase da questa storia come premessa a un clinico. È stato quindi chiesto loro di utilizzare la loro competenza medica e generare tre frasi:una frase che fosse decisamente vera per il paziente, data la premessa; una frase decisamente falsa, e infine una frase che potrebbe essere vera.
Nel giro di pochi mesi, abbiamo campionato casualmente 4, 683 tali premesse e ha lavorato con quattro medici per costruire MedNLI, un set di dati di 14, 049 coppie premessa-ipotesi. Nel dominio aperto, altri esempi di set di dati costruiti in modo simile includono il set di dati di Stanford Natural Language Inference, che è stato curato con l'aiuto di 2, 500 lavoratori su Amazon Mechanical Turk ed è composto da 0,5 milioni di coppie premessa-ipotesi in cui le frasi premesse sono state tratte dalle didascalie delle foto di Flickr. MultiNLI è un altro e consiste in premesse di generi specifici come narrativa, blog, conversazioni telefoniche, eccetera.
Il Dr. Leo Anthony Celi (Principal Scientist per MIMIC) e il Dr. Alistair Johnson (Research Scientist) del MIT Critical Data hanno lavorato con noi per rendere MedNLI pubblicamente disponibile. Hanno creato il repository di dati derivati MIMIC, a cui MedNLI ha agito come il primo contributo al set di dati di elaborazione del linguaggio naturale. Qualsiasi ricercatore con accesso a MIMIC può anche scaricare MedNLI da questo repository.
Sebbene di dimensioni modeste rispetto ai set di dati a dominio aperto, MedNLI è abbastanza grande da informare i ricercatori mentre sviluppano nuovi modelli di apprendimento automatico per l'inferenza linguistica in medicina. Più importante, presenta sfide interessanti che richiedono idee innovative. Considera alcuni esempi da MedNLI:
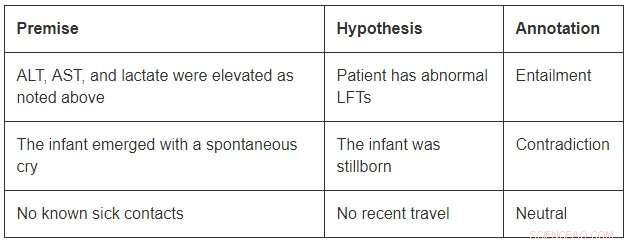
Per concludere l'implicazione nel primo esempio, si dovrebbe essere in grado di espandere le abbreviazioni ALT, AST, e LFT; capire che sono correlati; e concludere inoltre che una misurazione elevata è anormale. Il secondo esempio descrive una sottile inferenza di concludere che l'emergere di un bambino è una descrizione della sua nascita. Finalmente, l'ultimo esempio mostra come la conoscenza del mondo comune viene utilizzata per derivare inferenze.
Gli algoritmi di deep learning all'avanguardia possono svolgere molto bene le attività linguistiche perché hanno il potenziale per diventare molto bravi nell'apprendere una mappatura accurata dagli input agli output. Così, la formazione su un set di dati di grandi dimensioni annotato utilizzando annotazioni di crowdsourcing è spesso una ricetta per il successo. Però, mancano ancora di capacità di generalizzazione in condizioni diverse da quelle incontrate durante l'addestramento. Questo è ancora più difficile in settori specializzati e ad alta intensità di conoscenza come la medicina, dove i dati di formazione sono limitati e la lingua è molto più sfumata.
Finalmente, sebbene siano stati fatti grandi passi avanti nell'apprendimento di un compito linguistico end-to-end, c'è ancora bisogno di tecniche aggiuntive che possano incorporare basi di conoscenza curate da esperti in questi modelli. Per esempio, SNOMED-CT è una terminologia medica curata da esperti con oltre 300K concetti e relazioni tra i termini nel suo set di dati. All'interno di MedNLI, abbiamo apportato semplici modifiche alle architetture di reti neurali profonde esistenti per infondere conoscenza da basi di conoscenza come SNOMED-CT. Però, una grande quantità di conoscenza rimane ancora inutilizzata.
Speriamo che MedNLI apra nuove direzioni di ricerca nella comunità di elaborazione del linguaggio naturale.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.