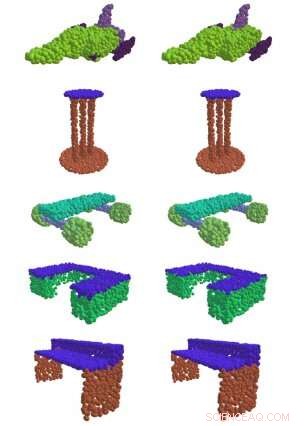
A sinistra, EdgeConv, un metodo sviluppato al MIT, trova con successo parti significative di forme 3D, come la superficie di un tavolo, ali di aeroplano, e le ruote di uno skateboard. A destra c'è il confronto della verità di base. Credito:Massachusetts Institute of Technology
Se hai mai visto un'auto a guida autonoma allo stato brado, potresti chiederti di quel cilindro rotante sopra di esso.
È un "sensore lidar, " ed è ciò che consente all'auto di navigare nel mondo. Inviando impulsi di luce infrarossa e misurando il tempo necessario per rimbalzare sugli oggetti, il sensore crea una "nuvola di punti" che crea un'istantanea 3D dei dintorni dell'auto.
È difficile dare un senso ai dati grezzi della nuvola di punti, e prima dell'era dell'apprendimento automatico, tradizionalmente richiedeva ingegneri altamente qualificati per specificare noiosamente quali qualità volevano catturare a mano. Ma in una nuova serie di articoli del Computer Science and Artificial Intelligence Laboratory (CSAIL) del MIT, i ricercatori dimostrano di poter utilizzare il deep learning per elaborare automaticamente le nuvole di punti per un'ampia gamma di applicazioni di imaging 3D.
"Nella visione artificiale e nell'apprendimento automatico di oggi, Il 90 percento dei progressi riguarda solo immagini bidimensionali, "dice il professor Justin Solomon del MIT, che è stato autore senior della nuova serie di articoli guidati da Ph.D. studente Yue Wang. "Il nostro lavoro mira a rispondere a un'esigenza fondamentale per rappresentare al meglio il mondo 3D, con applicazione non solo nella guida autonoma, ma qualsiasi campo che richieda la comprensione delle forme 3D."
La maggior parte degli approcci precedenti non ha avuto particolare successo nel catturare i modelli dai dati necessari per ottenere informazioni significative da un gruppo di punti 3D nello spazio. Ma in uno dei documenti della squadra, hanno dimostrato che il loro metodo "EdgeConv" di analizzare le nuvole di punti utilizzando un tipo di rete neurale chiamata rete neurale convoluzionale a grafo dinamico ha permesso loro di classificare e segmentare i singoli oggetti.
"Costruendo 'grafici' di punti vicini, l'algoritmo può catturare modelli gerarchici e quindi dedurre più tipi di informazioni generiche che possono essere utilizzate da una miriade di attività a valle, "dice Wadim Kehl, uno scienziato dell'apprendimento automatico presso il Toyota Research Institute che non era coinvolto nel lavoro.
Oltre a sviluppare EdgeConv, il team ha anche esplorato altri aspetti specifici dell'elaborazione delle nuvole di punti. Per esempio, una sfida è che la maggior parte dei sensori cambia prospettiva mentre si sposta nel mondo 3D; ogni volta che eseguiamo una nuova scansione dello stesso oggetto, la sua posizione potrebbe essere diversa dall'ultima volta che l'abbiamo vista. Per unire più nuvole di punti in un'unica vista dettagliata del mondo, è necessario allineare più punti 3D in un processo chiamato "registrazione".
La registrazione è vitale per molte forme di imaging, dai dati satellitari alle procedure mediche. Per esempio, quando un medico deve eseguire più scansioni di risonanza magnetica di un paziente nel tempo, la registrazione è ciò che rende possibile allineare le scansioni per vedere cosa è cambiato.
"La registrazione è ciò che ci consente di integrare dati 3D da diverse fonti in un sistema di coordinate comune, " dice Wang. "Senza di essa, non saremmo effettivamente in grado di ottenere informazioni altrettanto significative da tutti questi metodi che sono stati sviluppati".
Il secondo articolo di Solomon e Wang dimostra un nuovo algoritmo di registrazione chiamato "Deep Closest Point" (DCP) che ha dimostrato di trovare meglio i modelli distintivi di una nuvola di punti, punti, e bordi (noti come "caratteristiche locali") per allinearlo con altre nuvole di punti. Ciò è particolarmente importante per compiti come consentire alle auto a guida autonoma di situarsi in una scena ("localizzazione"), così come per mani robotiche per individuare e afferrare singoli oggetti.
Una limitazione di DCP è che presuppone che possiamo vedere un'intera forma invece di un solo lato. Ciò significa che non può gestire il compito più difficile di allineare le viste parziali delle forme (noto come "registrazione da parziale a parziale"). Di conseguenza, in un terzo articolo i ricercatori hanno presentato un algoritmo migliorato per questo compito che chiamano Partial Registration Network (PRNet).
Solomon afferma che i dati 3-D esistenti tendono ad essere "abbastanza disordinati e non strutturati rispetto alle immagini e alle fotografie 2-D". Il suo team ha cercato di capire come ottenere informazioni significative da tutti quei dati 3D disorganizzati senza l'ambiente controllato che molte tecnologie di apprendimento automatico ora richiedono.
Un'osservazione chiave alla base del successo di DCP e PRNet è l'idea che un aspetto critico dell'elaborazione della nuvola di punti sia il contesto. Le caratteristiche geometriche sulla nuvola di punti A che suggeriscono i modi migliori per allinearla alla nuvola di punti B possono essere diverse dalle caratteristiche necessarie per allinearla alla nuvola di punti C. Ad esempio, in registrazione parziale, una parte interessante di una forma in una nuvola di punti potrebbe non essere visibile nell'altra, rendendola inutile per la registrazione.
Wang afferma che gli strumenti del team sono già stati implementati da molti ricercatori nella comunità della visione artificiale e oltre. Anche i fisici li stanno usando per un'applicazione che il team CSAIL non aveva mai considerato:la fisica delle particelle.
Andando avanti, i ricercatori sperano di utilizzare gli algoritmi su dati del mondo reale, compresi i dati raccolti dalle auto a guida autonoma. Wang afferma che hanno anche in programma di esplorare il potenziale dell'addestramento dei loro sistemi utilizzando l'apprendimento auto-supervisionato, per ridurre al minimo la quantità di annotazioni umane necessarie.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.














