Il robot raccoglie dati di interazione casuali da utilizzare per addestrare una rappresentazione e come dati fuori policy per RL. Credito:Nair et al.
L'apprendimento per rinforzo (RL) si è finora dimostrato una tecnica efficace per addestrare agenti artificiali su compiti individuali. Però, quando si tratta di addestrare robot multiuso, che dovrebbe essere in grado di completare una varietà di compiti che richiedono abilità diverse, la maggior parte degli approcci RL esistenti è tutt'altro che ideale.
Con questo in testa, un team di ricercatori dell'UC Berkeley ha recentemente sviluppato un nuovo approccio RL che potrebbe essere utilizzato per insegnare ai robot ad adattare il proprio comportamento in base al compito che gli viene presentato. Questo approccio, delineato in un documento pre-pubblicato su arXiv e presentato alla Conferenza di quest'anno sull'apprendimento dei robot, consente ai robot di elaborare automaticamente comportamenti e metterli in pratica nel tempo, imparare quali possono essere eseguiti in un dato ambiente. I robot possono quindi riutilizzare le conoscenze acquisite e applicarle a nuove attività che gli utenti umani chiedono loro di completare.
"Siamo convinti che i dati siano la chiave per la manipolazione robotica e per ottenere dati sufficienti per risolvere la manipolazione in modo generale, i robot dovranno raccogliere i dati da soli, "Ashvin Nair, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Questo è ciò che chiamiamo apprendimento robotico autogestito:un robot che può raccogliere attivamente dati di esplorazione coerenti e capire da solo se ha avuto successo o meno in compiti per apprendere nuove abilità".
Il nuovo approccio sviluppato da Nair e dai suoi colleghi si basa su una struttura RL condizionata agli obiettivi presentata nel loro lavoro precedente. In questo precedente studio, i ricercatori hanno introdotto la definizione di obiettivi in uno spazio latente come tecnica per addestrare i robot su abilità come spingere oggetti o aprire porte direttamente dai pixel, senza la necessità di una funzione di ricompensa esterna o di una stima dello stato.
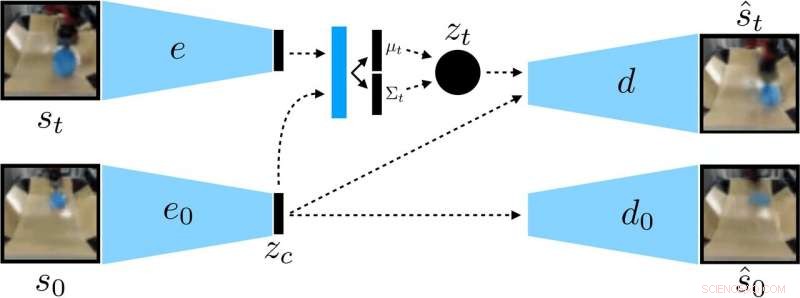
I ricercatori hanno addestrato un VAE condizionato dal contesto sui dati, che districa il contesto che rimane costante durante un'implementazione. Credito:Nair et al.
"Nel nostro nuovo lavoro, ci concentriamo sulla generalizzazione:come possiamo fare l'apprendimento auto-supervisionato non solo per apprendere una singola abilità, ma anche essere in grado di generalizzare alla diversità visiva durante l'esecuzione di tale abilità?" Ha detto Nair. "Crediamo che la capacità di generalizzare a nuove situazioni sarà la chiave per una migliore manipolazione robotica".
Piuttosto che addestrare un robot su molte abilità individualmente, il modello condizionale di definizione degli obiettivi proposto da Nair e dai suoi colleghi è progettato per fissare obiettivi specifici che sono fattibili per il robot e sono allineati con il suo stato attuale. Essenzialmente, l'algoritmo che hanno sviluppato apprende un tipo specifico di rappresentazione che separa le cose che il robot può controllare dalle cose che non può controllare.
Quando si utilizza il loro metodo di apprendimento autocontrollato, il robot inizialmente raccoglie dati (cioè un insieme di immagini e azioni) interagendo in modo casuale con l'ambiente circostante. Successivamente, addestra una rappresentazione compressa di questi dati che converte le immagini in vettori a bassa dimensionalità che contengono implicitamente informazioni come la posizione degli oggetti. Invece di essere detto esplicitamente cosa imparare, questa rappresentazione comprende automaticamente i concetti tramite il suo obiettivo di compressione.
"Utilizzando la rappresentazione appresa, il robot pratica il raggiungimento di obiettivi diversi e forma una politica utilizzando l'apprendimento per rinforzo, " Ha spiegato Nair. "La rappresentazione compressa è fondamentale per questa fase pratica:viene utilizzata per misurare quanto sono vicine due immagini in modo che il robot sappia quando ha avuto successo o ha fallito, ed è usato per campionare gli obiettivi che il robot deve praticare. Al momento della prova, può quindi abbinare un'immagine di obiettivo specificata da un essere umano eseguendo la sua politica appresa."
I ricercatori hanno valutato l'efficacia del loro approccio in una serie di esperimenti in cui un agente artificiale ha manipolato oggetti inediti in un ambiente creato utilizzando la piattaforma di simulazione MuJuCo. interessante, il loro metodo di addestramento ha permesso all'agente robotico di acquisire automaticamente abilità che potrebbe poi applicare a nuove situazioni. Più specificamente, il robot era in grado di manipolare una varietà di oggetti, generalizzando le strategie di manipolazione acquisite in precedenza a nuovi oggetti che non aveva incontrato durante l'addestramento.
"Siamo molto entusiasti di due risultati di questo lavoro, " Nair ha detto. "In primo luogo, abbiamo scoperto che possiamo addestrare una politica per spingere gli oggetti nel mondo reale su circa 20 oggetti, ma la policy appresa può effettivamente spingere anche altri oggetti. Questo tipo di generalizzazione è la principale promessa dei metodi di deep learning, e speriamo che questo sia l'inizio di forme di generalizzazione molto più impressionanti a venire".
Sorprendentemente, nei loro esperimenti, Nair e i suoi colleghi sono stati in grado di addestrare una politica da un set di dati fisso di interazioni senza dover raccogliere una grande quantità di dati online. Questo è un traguardo importante, poiché la raccolta di dati per la ricerca sulla robotica è generalmente molto costosa, ed essere in grado di apprendere abilità da set di dati fissi rende il loro approccio molto più pratico.
Nel futuro, il modello per l'apprendimento auto-supervisionato sviluppato dai ricercatori potrebbe aiutare lo sviluppo di robot in grado di affrontare una più ampia varietà di compiti senza formazione individuale su un ampio set di abilità. Intanto, Nair e i suoi colleghi intendono continuare a testare il loro approccio in ambienti simulati, mentre studiando anche i modi in cui potrebbe essere ulteriormente migliorato.
"Ora stiamo perseguendo alcune diverse linee di ricerca, compresa la risoluzione di compiti con una quantità molto maggiore di diversità visiva, oltre a risolvere una vasta serie di attività contemporaneamente e vedere se siamo in grado di utilizzare la soluzione su un'attività per accelerare la risoluzione dell'attività successiva, " ha detto Nair.
© 2019 Scienza X Rete