
Oier Mees dimostra come funziona il nuovo approccio. Credito:Mees et al.
Con più robot che ora si fanno strada in una serie di impostazioni, i ricercatori stanno cercando di rendere le loro interazioni con gli umani il più fluide e naturali possibile. Addestrare i robot a rispondere immediatamente alle istruzioni vocali, come "prendi il bicchiere, spostalo a destra, " eccetera., sarebbe l'ideale in molte situazioni, in quanto alla fine consentirebbe interazioni uomo-robot più dirette e intuitive. Però, non è sempre facile, poiché richiede che il robot comprenda le istruzioni dell'utente, ma anche saper muovere gli oggetti secondo specifiche relazioni spaziali.
I ricercatori dell'Università di Friburgo in Germania hanno recentemente ideato un nuovo approccio per insegnare ai robot come spostare gli oggetti secondo le istruzioni degli utenti umani, che funziona classificando rappresentazioni di scene "allucinate". La loro carta, pre-pubblicato su arXiv, sarà presentato alla IEEE International Conference on Robotics and Automation (ICRA) a Parigi, questo giugno.
"Nel nostro lavoro, ci concentriamo sulle istruzioni di posizionamento degli oggetti relazionali, come "metti la tazza a destra della scatola" o "metti il giocattolo giallo sopra la scatola, '" Oier Mees, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Fare così, il robot ha bisogno di ragionare su dove posizionare la tazza rispetto alla scatola o a qualsiasi altro oggetto di riferimento per riprodurre la relazione spaziale descritta da un utente."
Addestrare i robot a dare un senso alle relazioni spaziali e a spostare gli oggetti di conseguenza può essere molto difficile, poiché le istruzioni dell'utente in genere non delineano una posizione specifica all'interno di una scena più ampia osservata dal robot. In altre parole, se un utente umano dice "posiziona la tazza a sinistra dell'orologio, " quanto lontano dall'orologio il robot dovrebbe posizionare la tazza e dov'è il confine esatto tra le diverse direzioni (ad es. Giusto, sinistra, davanti, dietro a, eccetera.)?
"A causa di questa intrinseca ambiguità, non ci sono nemmeno dati veritieri o "corretti" che possono essere usati per imparare a modellare le relazioni spaziali, " Ha detto Mees. " Affrontiamo il problema dell'indisponibilità di annotazioni pixel per pixel delle relazioni spaziali dal punto di vista dell'apprendimento ausiliario ".
L'idea principale alla base dell'approccio ideato da Mees e dai suoi colleghi è che quando vengono dati due oggetti e un'immagine che rappresenta il contesto in cui si trovano, è più facile determinare la relazione spaziale tra loro. Ciò consente ai robot di rilevare se un oggetto è alla sinistra dell'altro, sopra, davanti ad esso, eccetera.
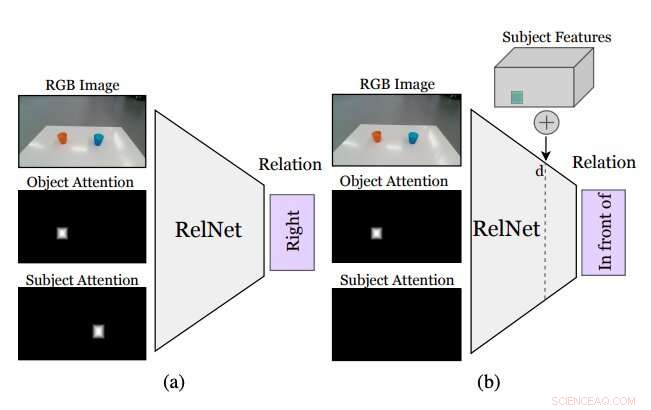
Figura che riassume come funziona l'approccio ideato dai ricercatori. Una CNN ausiliaria, chiamato RelNet, è addestrato a prevedere le relazioni spaziali data l'immagine di input e due maschere di attenzione che si riferiscono a due oggetti che formano una relazione. (a) dopo l'addestramento, la rete può essere "ingannata" per classificare scene allucinate (b) implementando caratteristiche di alto livello di oggetti in diverse posizioni spaziali. Credito:Mees et al.
Sebbene l'identificazione di una relazione spaziale tra due oggetti non specifichi dove dovrebbero essere collocati gli oggetti per riprodurre tale relazione, l'inserimento di altri oggetti all'interno della scena potrebbe consentire al robot di inferire una distribuzione su più relazioni spaziali. Aggiungendo questi inesistenti (cioè, allucinato) oggetti rispetto a ciò che il robot sta vedendo dovrebbero consentirgli di valutare come apparirebbe la scena se eseguisse una determinata azione (cioè, posizionare uno degli oggetti in una posizione specifica sul tavolo o sulla superficie di fronte ad esso).
"Più comunemente, "incollare" oggetti realisticamente in un'immagine richiede l'accesso a modelli e sagome 3D o un'attenta progettazione della procedura di ottimizzazione delle reti generative avversarie (GAN), "Mees ha detto. "Inoltre, "incollare" ingenuamente maschere di oggetti nelle immagini crea sottili artefatti di pixel che portano a caratteristiche notevolmente diverse e all'addestramento che si concentra erroneamente su queste discrepanze. Adottiamo un approccio diverso e impiantiamo caratteristiche di alto livello degli oggetti nelle mappe delle caratteristiche della scena generate da una rete neurale convoluzionale per allucinare le rappresentazioni della scena, che vengono poi classificati come attività ausiliaria per ottenere il segnale di apprendimento."
Prima di addestrare una rete neurale convoluzionale (CNN) per apprendere le relazioni spaziali basate su oggetti allucinati, i ricercatori hanno dovuto assicurarsi che fosse in grado di classificare le relazioni tra singole coppie di oggetti sulla base di una singola immagine. Successivamente, hanno "ingannato" la loro rete, soprannominato RelNet, classificando scene "allucinate" impiantando caratteristiche di alto livello di oggetti in diverse posizioni spaziali.
"Il nostro approccio consente a un robot di seguire le istruzioni di posizionamento del linguaggio naturale fornite dagli utenti umani con una raccolta di dati o euristica minima, " Mees ha detto. "Tutti vorrebbero avere un robot di servizio a casa in grado di eseguire compiti comprendendo le istruzioni del linguaggio naturale. Questo è un primo passo per consentire a un robot di comprendere meglio il significato delle preposizioni spaziali di uso comune".
La maggior parte dei metodi esistenti per addestrare i robot a spostare gli oggetti utilizza le informazioni relative alle forme 3D degli oggetti per modellare le relazioni spaziali a coppie. Una limitazione fondamentale di queste tecniche è che spesso richiedono componenti tecnologici aggiuntivi, come i sistemi di tracciamento in grado di tracciare i movimenti di oggetti diversi. L'approccio proposto da Mees e dai suoi colleghi, d'altra parte, non richiede strumenti aggiuntivi, poiché non si basa su tecniche di visione 3D.
I ricercatori hanno valutato il loro metodo in una serie di esperimenti che coinvolgono utenti umani e robot reali. I risultati di questi test sono stati molto promettenti, poiché il loro metodo ha permesso ai robot di identificare efficacemente le migliori strategie per posizionare gli oggetti su un tavolo in conformità con le relazioni spaziali delineate dalle istruzioni vocali dell'utente umano.
"Il nostro nuovo approccio alle rappresentazioni di scene allucinanti può anche avere molteplici applicazioni nelle comunità della robotica e della visione artificiale, poiché spesso i robot hanno bisogno di essere in grado di stimare quanto buono potrebbe essere uno stato futuro per ragionare sulle azioni che devono intraprendere, " Ha detto Mees. "Potrebbe anche essere usato per migliorare le prestazioni di molte reti neurali, come reti di rilevamento di oggetti, utilizzando rappresentazioni di scene allucinate come una forma di aumento dei dati".
Mees e i suoi colleghi siamo in grado di modellare un insieme di preposizioni spaziali del linguaggio naturale (ad es. sinistra, sopra, ecc.) in modo affidabile e senza l'utilizzo di strumenti di visione 3D. Nel futuro, l'approccio presentato nel loro studio potrebbe essere utilizzato per migliorare le capacità dei robot esistenti, consentendo loro di completare semplici attività di spostamento degli oggetti in modo più efficace seguendo le istruzioni vocali di un utente umano.
Nel frattempo, il loro documento potrebbe informare lo sviluppo di tecniche simili per migliorare le interazioni tra umani e robot durante altre attività di manipolazione di oggetti. Se abbinato a metodi di apprendimento ausiliari, l'approccio sviluppato da Mees e dai suoi colleghi può anche ridurre i costi e gli sforzi associati alla compilazione di set di dati per la ricerca sulla robotica, in quanto consente la previsione delle probabilità pixel per pixel senza richiedere grandi set di dati annotati.
"Riteniamo che questo sia un primo passo promettente per consentire una comprensione condivisa tra umani e robot, " Mees ha concluso. "In futuro, vogliamo estendere il nostro approccio per incorporare una comprensione delle espressioni di riferimento, al fine di sviluppare un sistema pick-and-place che segua le istruzioni del linguaggio naturale."
© 2020 Scienza X Rete














