Credito:Massachusetts Institute of Technology
Per tutti i progressi che i ricercatori hanno fatto con l'apprendimento automatico nell'aiutarci a fare cose come numeri crunch, guidare auto e rilevare il cancro, raramente pensiamo a quanto sia dispendioso in termini di energia mantenere gli enormi data center che rendono possibile tale lavoro. Infatti, uno studio del 2017 ha previsto che, entro il 2025, i dispositivi connessi a Internet utilizzerebbero il 20% dell'elettricità mondiale.
L'inefficienza dell'apprendimento automatico è in parte una funzione di come vengono creati tali sistemi. Le reti neurali sono tipicamente sviluppate generando un modello iniziale, modificando alcuni parametri, riprovando, e poi risciacquare e ripetere. Ma questo approccio significa che un tempo significativo, l'energia e le risorse informatiche vengono spese per un progetto prima che qualcuno sappia se funzionerà effettivamente.
Lo studente laureato del MIT Jonathan Rosenfeld lo paragona agli scienziati del 17° secolo che cercano di capire la gravità e il movimento dei pianeti. Dice che il modo in cui sviluppiamo oggi i sistemi di apprendimento automatico, in assenza di tali comprensioni, ha un potere predittivo limitato ed è quindi molto inefficiente.
"Non esiste ancora un modo unificato per prevedere le prestazioni di una rete neurale dati determinati fattori come la forma del modello o la quantità di dati su cui è stata addestrata, "dice Rosenfeld, che ha recentemente sviluppato un nuovo framework sull'argomento con i colleghi del Computer Science and Artificial Intelligence Lab (CSAIL) del MIT. "Volevamo esplorare se potevamo far progredire l'apprendimento automatico cercando di comprendere le diverse relazioni che influenzano l'accuratezza di una rete".
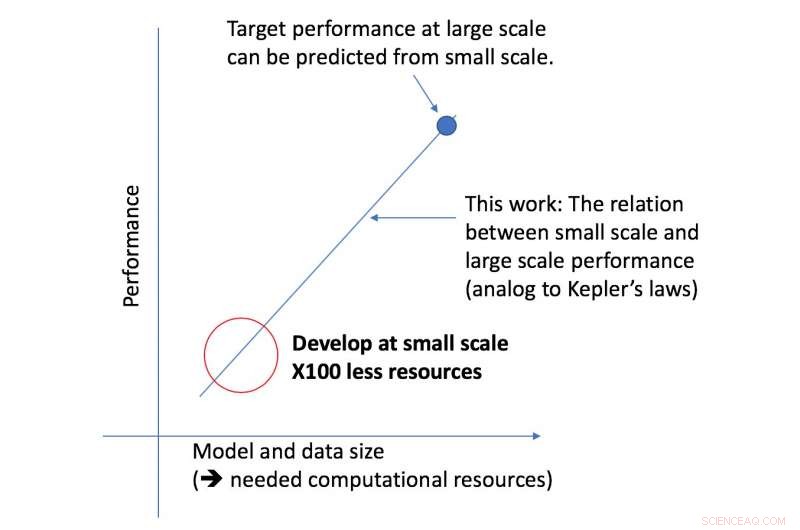
Il nuovo framework del team CSAIL esamina un determinato algoritmo su scala ridotta, e, in base a fattori come la sua forma, può prevedere come funzionerà su una scala più ampia. Ciò consente a un data scientist di determinare se vale la pena continuare a dedicare più risorse per addestrare ulteriormente il sistema.
"Il nostro approccio ci dice cose come la quantità di dati necessari a un'architettura per fornire prestazioni target specifiche, o il compromesso più efficiente dal punto di vista computazionale tra dati e dimensioni del modello, " dice il professore del MIT Nir Shavit, che ha co-scritto il nuovo articolo con Rosenfeld, ex dottorando Yonatan Belinkov e Amir Rosenfeld della York University. "Riteniamo che questi risultati abbiano implicazioni di vasta portata nel campo, consentendo ai ricercatori del mondo accademico e industriale di comprendere meglio le relazioni tra i diversi fattori che devono essere soppesati durante lo sviluppo di modelli di apprendimento profondo, e farlo con le limitate risorse computazionali a disposizione degli accademici".
Il framework ha consentito ai ricercatori di prevedere con precisione le prestazioni su modelli e scale di dati di grandi dimensioni utilizzando una potenza di calcolo cinquanta volte inferiore.
L'aspetto delle prestazioni di apprendimento profondo su cui si è concentrato il team è il cosiddetto "errore di generalizzazione, " che si riferisce all'errore generato quando un algoritmo viene testato su dati del mondo reale. Il team ha utilizzato il concetto di ridimensionamento del modello, che comporta la modifica della forma del modello in modi specifici per vedere il suo effetto sull'errore.
Come passo successivo, il team prevede di esplorare le teorie alla base di ciò che determina il successo o il fallimento delle prestazioni di uno specifico algoritmo. Ciò include la sperimentazione di altri fattori che possono influire sulla formazione dei modelli di deep learning.