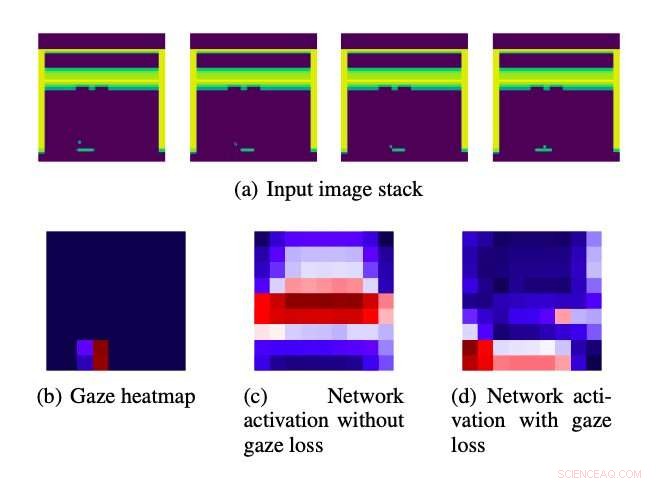
Stack di immagini in ingresso alimentato agli algoritmi. Credito:Sara et al.
Studi di psicologia del passato suggeriscono che lo sguardo umano può codificare le intenzioni degli umani mentre svolgono le attività quotidiane, come fare un panino o una bevanda calda. Allo stesso modo, è stato scoperto che lo sguardo umano migliora le prestazioni dei metodi di apprendimento per imitazione, che consentono ai robot di imparare a completare le attività imitando i dimostratori umani.
Ispirato da questi risultati precedenti, i ricercatori dell'Università del Texas ad Austin e della Tufts University hanno recentemente ideato una nuova strategia per migliorare gli algoritmi di apprendimento dell'imitazione utilizzando i dati relativi allo sguardo umano. Il metodo che hanno sviluppato, delineato in un documento pre-pubblicato su arXiv, usa lo sguardo di un dimostratore umano per dirigere l'attenzione degli algoritmi di apprendimento dell'imitazione verso aree che ritengono importanti, in base al fatto che gli utenti umani si sono occupati di loro.
"Gli algoritmi di deep learning devono imparare a identificare le caratteristiche importanti nelle scene visive, ad esempio, un personaggio di un videogioco o un nemico, imparando anche a utilizzare queste funzionalità per prendere decisioni, " Il prof. Scott Niekum dell'Università del Texas ad Austin ha dichiarato a TechXplore. "Il nostro approccio lo rende più semplice, usando lo sguardo umano come spunto che indica quali elementi visivi della scena sono più importanti per il processo decisionale".
L'approccio ideato dai ricercatori prevede l'uso di informazioni relative allo sguardo umano come guida, indirizzare l'attenzione di un modello di deep learning su caratteristiche particolarmente importanti dei dati che sta analizzando. Questa guida relativa allo sguardo è codificata nella funzione di perdita applicata ai modelli di deep learning durante l'addestramento.
"La ricerca precedente che esplorava l'uso dei dati dello sguardo per migliorare gli approcci di apprendimento dell'imitazione in genere integrava i dati dello sguardo addestrando algoritmi con parametri più apprendibili, rendendo l'apprendimento computazionalmente costoso e richiedendo informazioni sullo sguardo sia durante il treno che durante il test, "Akanksha Saran, un dottorato di ricerca studente dell'Università del Texas ad Austin che è stato coinvolto nello studio, ha detto a TechXplore. "Volevamo esplorare strade alternative per aumentare facilmente gli approcci di apprendimento per imitazione esistenti con i dati dello sguardo umano, senza aumentare i parametri apprendibili."
La strategia sviluppata da Niekum, Saran e i suoi colleghi possono essere applicati alla maggior parte delle architetture basate su reti neurali convoluzionali (CNN) esistenti. Utilizzando un componente ausiliario di perdita dello sguardo che guida le architetture verso politiche più efficaci, il loro approccio può in definitiva migliorare le prestazioni di una varietà di algoritmi di deep learning.
Il nuovo approccio presenta diversi vantaggi rispetto ad altre strategie che utilizzano dati relativi allo sguardo per guidare modelli di deep learning. I due più importanti sono che non richiede l'accesso ai dati dello sguardo al momento del test e l'aggiunta di parametri apprendibili supplementari.
I ricercatori hanno valutato il loro approccio in una serie di esperimenti, usandolo per migliorare diverse architetture di deep learning e poi testare le loro prestazioni sui giochi Atari. Hanno scoperto che ha migliorato significativamente le prestazioni di tre diversi algoritmi di apprendimento dell'imitazione, superando un metodo di base che utilizza i dati dello sguardo umano. Inoltre, l'approccio dei ricercatori ha abbinato le prestazioni di un'altra strategia che utilizza i dati relativi allo sguardo sia durante l'allenamento che durante il test, ma ciò comporta l'aumento del numero di parametri apprendibili.
"I nostri risultati suggeriscono che i vantaggi di alcuni approcci precedentemente proposti derivano da un aumento del numero di parametri apprendibili stessi, non dall'uso dei soli dati dello sguardo, " Saran ha detto. "Il nostro metodo mostra miglioramenti comparabili senza aggiungere parametri alle tecniche di apprendimento imitazione esistenti".
Mentre conducevano i loro esperimenti, i ricercatori hanno anche osservato che il movimento degli oggetti in una data scena da solo non spiega completamente le informazioni codificate dallo sguardo. Nel futuro, la strategia che hanno sviluppato potrebbe essere utilizzata per migliorare le prestazioni degli algoritmi di apprendimento per imitazione su una varietà di compiti diversi. I ricercatori sperano che il loro lavoro possa fornire informazioni anche su ulteriori studi volti a utilizzare i dati relativi allo sguardo umano per far progredire le tecniche computazionali.
"Mentre il nostro metodo riduce le esigenze di calcolo durante il tempo di test, richiede la messa a punto degli iperparametri durante l'allenamento per ottenere buone prestazioni, "Ha detto Saran. "Alleviare questo fardello durante l'allenamento codificando altre intuizioni del comportamento dello sguardo umano sarà un aspetto del lavoro futuro".
L'approccio sviluppato da Saran e dai suoi colleghi si è finora dimostrato molto promettente, tuttavia ci sono diversi modi in cui potrebbe essere ulteriormente migliorato. Ad esempio, attualmente non modella tutti gli aspetti dei dati relativi allo sguardo umano che potrebbero essere utili per le applicazioni di apprendimento dell'imitazione. I ricercatori sperano di concentrarsi su alcuni di questi altri aspetti nei loro studi futuri.
"Finalmente, le connessioni temporali di sguardo e azione non sono ancora state esplorate e potrebbero essere fondamentali per ottenere maggiori benefici nelle prestazioni, " ha detto Saran. "Stiamo anche lavorando sull'utilizzo di altri spunti da insegnanti umani per migliorare l'apprendimento dell'imitazione, come dimostrazioni di accompagnamento con audio umano."
© 2020 Scienza X Rete