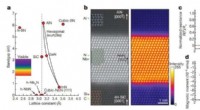
I ricercatori hanno utilizzato un processo di stima dell'errore e approssimazione matematica per dimostrare che il loro kernel approssimativo rimane coerente con il kernel accurato. Credito:2020 Ding et al.
Utilizzando una funzione "kernel" approssimativa piuttosto che esplicita per estrarre relazioni in insiemi di dati molto grandi, I ricercatori KAUST sono stati in grado di accelerare notevolmente la velocità dell'apprendimento automatico. L'approccio promette di migliorare notevolmente la velocità dell'intelligenza artificiale (AI) nell'era dei big data.
Quando l'intelligenza artificiale è esposta a un grande set di dati sconosciuto, ha bisogno di analizzare i dati e sviluppare un modello o una funzione che descriva le relazioni nell'insieme. Il calcolo di questa funzione, o nocciolo, è un compito computazionalmente intensivo che aumenta di complessità in modo cubico (alla potenza di tre) con la dimensione del set di dati. Nell'era dei big data e della crescente dipendenza dall'intelligenza artificiale per l'analisi, questo presenta un problema reale in cui la selezione del kernel può diventare impraticabile in termini di tempo.
Con la supervisione di Xin Gao, Lizhong Ding e i suoi colleghi hanno lavorato su metodi per accelerare la selezione del kernel utilizzando le statistiche.
"La complessità computazionale di un'accurata selezione del kernel è solitamente cubica con il numero di campioni, " dice Ding. "Questo tipo di ridimensionamento cubico è proibitivo per i big data. Abbiamo invece proposto un approccio di approssimazione per la selezione del kernel, che migliora significativamente l'efficienza della selezione del kernel senza sacrificare le prestazioni predittive."
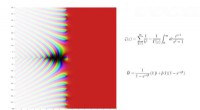
Il kernel vero o accurato fornisce una descrizione letterale delle relazioni nel set di dati. Ciò che i ricercatori hanno scoperto è che le statistiche possono essere utilizzate per derivare un kernel approssimativo che è buono quasi quanto la versione accurata, ma può essere calcolato molte volte più velocemente, scalare linearmente, piuttosto che cubicamente, con la dimensione del set di dati.
Per sviluppare l'approccio, il team ha dovuto costruire matrici kernel appositamente progettate, o array matematici, che potrebbe essere calcolato rapidamente. Dovevano anche stabilire le regole ei limiti teorici per la selezione del nucleo approssimativo che garantisse comunque le prestazioni di apprendimento.
"La sfida principale era che avevamo bisogno di progettare nuovi algoritmi che soddisfacessero questi due punti allo stesso tempo, "dice Ding.
Combinando un processo di stima dell'errore e approssimazione matematica, i ricercatori sono stati in grado di dimostrare che il loro kernel approssimativo rimane coerente con il kernel accurato e quindi hanno dimostrato le sue prestazioni in esempi reali.
"Abbiamo dimostrato che i metodi approssimati, come il nostro framework informatico, fornire una precisione sufficiente per risolvere un metodo di apprendimento basato sul kernel, senza l'impratico onere computazionale di metodi accurati, " afferma Ding. "Questo fornisce una soluzione efficace ed efficiente per i problemi di data mining e bioinformatica che richiedono scalabilità".