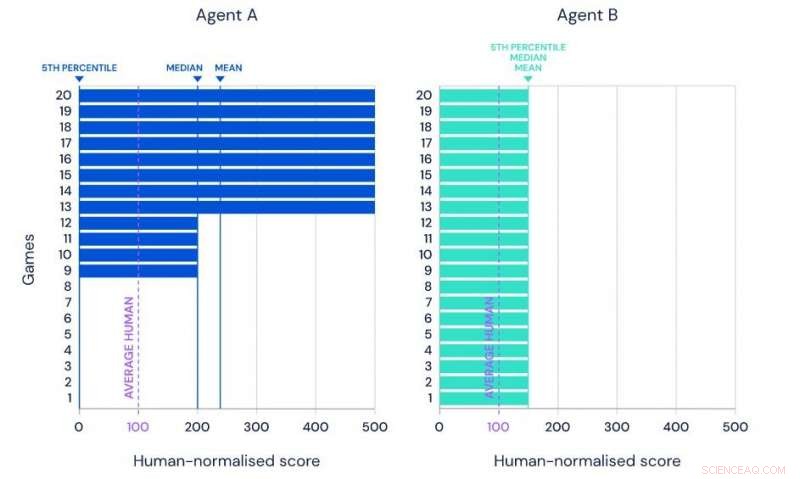
Illustrazione della media, performance mediana e del 5° percentile di due ipotetici agenti sullo stesso set di riferimento di 20 attività. Credito:Google
Al fine di risolvere al meglio sfide complesse all'alba del terzo decennio del 21° secolo, Alphabet Inc. ha attinto a cimeli risalenti agli anni '80:i videogiochi.
La società madre di Google ha riferito questa settimana che la sua unità di intelligenza artificiale DeepMind Technologies ha imparato con successo a giocare a 57 videogiochi Atari. E il sistema informatico funziona meglio di qualsiasi essere umano.
Atari, creatore di Pong, uno dei primi videogiochi di successo degli anni '70, ha continuato a diffondere molti dei primi grandi videogiochi classici negli anni '90. I videogiochi sono comunemente usati con i progetti di intelligenza artificiale perché sfidano gli algoritmi a navigare in percorsi e opzioni sempre più complessi, il tutto incontrando scenari mutevoli, minacce e ricompense.
Soprannominato AGENTE57, Il sistema di intelligenza artificiale di Alphabet ha sondato 57 giochi Atari leader che coprono una vasta gamma di livelli di difficoltà e diverse strategie di successo.
"I giochi sono un eccellente banco di prova per costruire algoritmi adattivi, " hanno detto i ricercatori in un rapporto sulla pagina del blog DeepMind. " Forniscono una ricca suite di compiti che i giocatori devono sviluppare strategie comportamentali sofisticate per padroneggiare, ma forniscono anche una metrica di avanzamento facile, il punteggio di gioco, per l'ottimizzazione.
"L'obiettivo finale non è sviluppare sistemi che eccellono nei giochi, ma piuttosto usare i giochi come trampolino di lancio per lo sviluppo di sistemi che imparano ad eccellere in un'ampia serie di sfide, "diceva il rapporto.
Il sistema AlphaGo di DeepMind ha ottenuto un ampio riconoscimento nel 2016 quando ha battuto il campione del mondo Lee Sedol nel gioco strategico di Go.
Tra l'attuale raccolto di 57 giochi Atari, quattro sono considerati particolarmente difficili da padroneggiare per i progetti di intelligenza artificiale:Montezuma's Revenge, trappola, Solaris e Sci. I primi due giochi pongono quello che DeepMind chiama lo sconcertante "problema esplorazione-sfruttamento".
"Se si continua a mettere in atto comportamenti che si sa funzionano (exploit), o si dovrebbe provare qualcosa di nuovo (esplorare) per scoprire nuove strategie che potrebbero avere ancora più successo?" chiede DeepMind. "Ad esempio, se si ordina sempre lo stesso piatto preferito in un ristorante locale, o provare qualcosa di nuovo che potrebbe superare il vecchio preferito? L'esplorazione implica l'adozione di molte azioni subottimali per raccogliere le informazioni necessarie per scoprire un comportamento in definitiva più forte".
Gli altri due avvincenti giochi impongono lunghi tempi di attesa tra sfide e ricompense, rendendo più difficile l'analisi riuscita dei sistemi di intelligenza artificiale.
Gli sforzi precedenti per padroneggiare i quattro giochi con l'intelligenza artificiale sono falliti.
Il rapporto dice che ci sono ancora margini di miglioramento. Per uno, i lunghi tempi di calcolo rimangono un problema. Anche, pur riconoscendo che "più a lungo si è allenato, più alto è il suo punteggio, " I ricercatori di DeepMind vogliono che Agent57 funzioni meglio. Vogliono che gestisca più giochi contemporaneamente; attualmente, può imparare solo un gioco alla volta e deve passare attraverso l'allenamento ogni volta che ricomincia un gioco.
In definitiva, I ricercatori di DeepMind prevedono un programma in grado di applicare scelte decisionali simili a quelle umane affrontando sfide in continua evoluzione e mai viste prima.
"Vera versatilità, che viene così facilmente a un bambino umano, è ancora ben oltre la portata delle IA, " concludeva il rapporto.
© 2020 Scienza X Rete