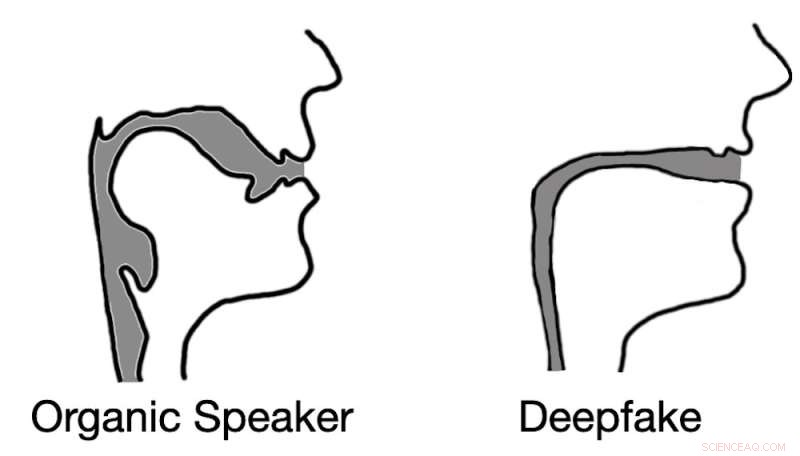
L'audio deepfak spesso si traduce in ricostruzioni del tratto vocale che assomigliano a cannucce piuttosto che a tratti vocali biologici. Credito:Logan Blue et al., CC BY-ND
Immagina il seguente scenario. Un telefono squilla. Un impiegato risponde e sente il suo capo, in preda al panico, dirgli che si è dimenticata di trasferire i soldi al nuovo appaltatore prima di partire per la giornata e ha bisogno che lui lo faccia. Gli dà le informazioni sul bonifico bancario e, con il trasferimento di denaro, la crisi è stata scongiurata.
L'operaio si siede sulla sedia, fa un respiro profondo e osserva il suo capo che entra dalla porta. La voce all'altro capo della chiamata non era il suo capo. In realtà, non era nemmeno un essere umano. La voce che ha sentito era quella di un deepfake audio, un campione audio generato dalla macchina progettato per suonare esattamente come il suo capo.
Attacchi come questo utilizzando l'audio registrato si sono già verificati e i deepfake audio conversazionali potrebbero non essere lontani.
I deepfake, sia audio che video, sono stati possibili solo con lo sviluppo di sofisticate tecnologie di apprendimento automatico negli ultimi anni. I deepfake hanno portato con sé un nuovo livello di incertezza sui media digitali. Per rilevare i deepfake, molti ricercatori si sono rivolti all'analisi degli artefatti visivi, piccoli difetti e incongruenze, che si trovano nei video deepfake.
I deepfake audio rappresentano potenzialmente una minaccia ancora maggiore, perché le persone spesso comunicano verbalmente senza video, ad esempio tramite telefonate, radio e registrazioni vocali. Queste comunicazioni solo vocali ampliano notevolmente le possibilità per gli aggressori di utilizzare i deepfake.
Per rilevare i deepfake audio, noi e i nostri colleghi di ricerca dell'Università della Florida abbiamo sviluppato una tecnica che misura le differenze acustiche e fluidodinamiche tra i campioni vocali creati organicamente da parlanti umani e quelli generati sinteticamente dai computer.
Voci organiche e sintetiche
Gli esseri umani vocalizzano forzando l'aria sulle varie strutture del tratto vocale, comprese le corde vocali, la lingua e le labbra. Riorganizzando queste strutture, alteri le proprietà acustiche del tuo tratto vocale, permettendoti di creare oltre 200 suoni distinti, o fonemi. Tuttavia, l'anatomia umana limita fondamentalmente il comportamento acustico di questi diversi fonemi, risultando in una gamma relativamente piccola di suoni corretti per ciascuno.
Al contrario, i deepfake audio vengono creati consentendo prima a un computer di ascoltare le registrazioni audio di un oratore vittima mirato. A seconda delle tecniche esatte utilizzate, il computer potrebbe dover ascoltare da 10 a 20 secondi di audio. Questo audio viene utilizzato per estrarre informazioni chiave sugli aspetti unici della voce della vittima.
L'attaccante seleziona una frase che il deepfake deve pronunciare e quindi, utilizzando un algoritmo di sintesi vocale modificato, genera un campione audio che suona come la vittima che dice la frase selezionata. Questo processo di creazione di un singolo campione audio deepfake può essere eseguito in pochi secondi, consentendo potenzialmente agli aggressori una flessibilità sufficiente per utilizzare la voce deepfake in una conversazione.
Rilevamento dei deepfake audio
Il primo passo per differenziare il discorso prodotto dagli esseri umani dal discorso generato dai deepfake è capire come modellare acusticamente il tratto vocale. Fortunatamente gli scienziati hanno tecniche per stimare come suonerebbe qualcuno, o alcuni esseri come un dinosauro, sulla base di misurazioni anatomiche del suo tratto vocale.
Abbiamo fatto il contrario. Invertendo molte di queste stesse tecniche, siamo stati in grado di estrarre un'approssimazione del tratto vocale di un parlante durante un segmento del discorso. Questo ci ha permesso di scrutare efficacemente l'anatomia dell'altoparlante che ha creato il campione audio.
Da qui, abbiamo ipotizzato che i campioni audio deepfake non sarebbero stati vincolati dalle stesse limitazioni anatomiche che hanno gli esseri umani. In altre parole, l'analisi di campioni audio falsi simulava forme del tratto vocale che non esistono nelle persone.
I risultati dei nostri test non solo hanno confermato la nostra ipotesi, ma hanno rivelato qualcosa di interessante. Quando si estraggono le stime del tratto vocale dall'audio deepfake, abbiamo scoperto che le stime erano spesso comicamente errate. Ad esempio, era comune che l'audio deepfake producesse tratti vocali con lo stesso diametro relativo e consistenza di una cannuccia, in contrasto con i tratti vocali umani, che sono molto più ampi e di forma più variabile.
Questa realizzazione dimostra che l'audio deepfake, anche se convincente per gli ascoltatori umani, è tutt'altro che indistinguibile dal parlato generato dall'uomo. Stimando l'anatomia responsabile della creazione del discorso osservato, è possibile identificare se l'audio è stato generato da una persona o da un computer.
Perché è importante
Il mondo di oggi è definito dallo scambio digitale di media e informazioni. Tutto, dalle notizie all'intrattenimento alle conversazioni con i propri cari, avviene in genere tramite scambi digitali. Anche nella loro infanzia, video e audio deepfake minano la fiducia che le persone hanno in questi scambi, limitando di fatto la loro utilità.
Se il mondo digitale deve rimanere una risorsa fondamentale per l'informazione nella vita delle persone, sono fondamentali tecniche efficaci e sicure per determinare la fonte di un campione audio. + Esplora ulteriormente
Questo articolo è stato ripubblicato da The Conversation con licenza Creative Commons. Leggi l'articolo originale.