'Théâtre D'Opéra Spatial' Crediti:Jason Allen / Midjourney
Un premio artistico alla Colorado State Fair è stato assegnato il mese scorso a un'opera che, all'insaputa dei giudici, è stata generata da un sistema di intelligenza artificiale (AI).
I social media hanno anche assistito a un'esplosione di immagini strane generate dall'intelligenza artificiale da descrizioni di testo, come "il volto di uno shiba inu confuso con il lato di una pagnotta su una panca da cucina, arte digitale".

O forse "Una lontra marina nello stile di 'Ragazza con l'orecchino di perla' di Johannes Vermeer":

'Una lontra marina nello stile di 'Ragazza con l'orecchino di perla' di Johannes Vermeer.' Credit:OpenAI
Ti starai chiedendo cosa sta succedendo qui. Come persona che ricerca collaborazioni creative tra umani e IA, posso dirti che dietro i titoli dei giornali e i meme è in corso una rivoluzione fondamentale, con profonde implicazioni sociali, artistiche, economiche e tecnologiche.
Come siamo arrivati qui
Si potrebbe dire che questa rivoluzione è iniziata nel giugno 2020, quando un'azienda chiamata OpenAI ha ottenuto una grande svolta nell'IA con la creazione di GPT-3, un sistema in grado di elaborare e generare linguaggio in modi molto più complessi rispetto ai precedenti sforzi. Puoi conversare con lui su qualsiasi argomento, chiedergli di scrivere un articolo di ricerca o una storia, riassumere un testo, scrivere una barzelletta e svolgere quasi tutte le attività linguistiche immaginabili.
Nel 2021, alcuni sviluppatori di GPT-3 si sono dedicati alle immagini. Hanno addestrato un modello su miliardi di coppie di immagini e descrizioni di testo, quindi lo hanno utilizzato per generare nuove immagini da nuove descrizioni. Hanno chiamato questo sistema DALL-E e nel luglio 2022 hanno rilasciato una nuova versione molto migliorata, DALL-E 2.

Un'immagine generata da DALL-E dal prompt "Mind in Bloom" che combina gli stili di Salvador Dali, Henri Matisse e Brett Whiteley'. Credito:Rodolfo Ocampo / DALL-E
Come GPT-3, DALL-E 2 è stato un importante passo avanti. Può generare immagini altamente dettagliate da input di testo in formato libero, comprese informazioni sullo stile e altri concetti astratti.
Ad esempio, qui le ho chiesto di illustrare la frase "Mind in Bloom" che unisce gli stili di Salvador Dalí, Henri Matisse e Brett Whiteley.
Entrano in scena i concorrenti
Dal lancio di DALL-E 2, sono emersi alcuni concorrenti. Uno è il DALL-E Mini gratuito ma di qualità inferiore (sviluppato in modo indipendente e ora ribattezzato Craiyon), che era una popolare fonte di contenuti di meme.
Più o meno nello stesso periodo, una società più piccola chiamata Midjourney ha rilasciato un modello che si avvicinava di più alle capacità di DALL-E 2. Sebbene sia ancora un po' meno capace di DALL-E 2, Midjourney si è prestato a interessanti esplorazioni artistiche. È stato con Midjourney che Jason Allen ha generato l'opera d'arte che ha vinto il concorso Colorado State Art Fair.
Anche Google ha un modello da testo a immagine, chiamato Imagen, che presumibilmente produce risultati molto migliori rispetto a DALL-E e altri. Tuttavia, Imagen non è stato ancora rilasciato per un uso più ampio, quindi è difficile valutare le affermazioni di Google.
Nel luglio 2022, OpenAI ha iniziato a capitalizzare l'interesse in DALL-E, annunciando che a 1 milione di utenti sarebbe stato concesso l'accesso a pagamento.
Tuttavia, nell'agosto 2022 è arrivato un nuovo contendente:Stable Diffusion.
Stable Diffusion non solo rivaleggia con DALL-E 2 nelle sue capacità, ma soprattutto è open source. Chiunque può utilizzare, adattare e modificare il codice a proprio piacimento.
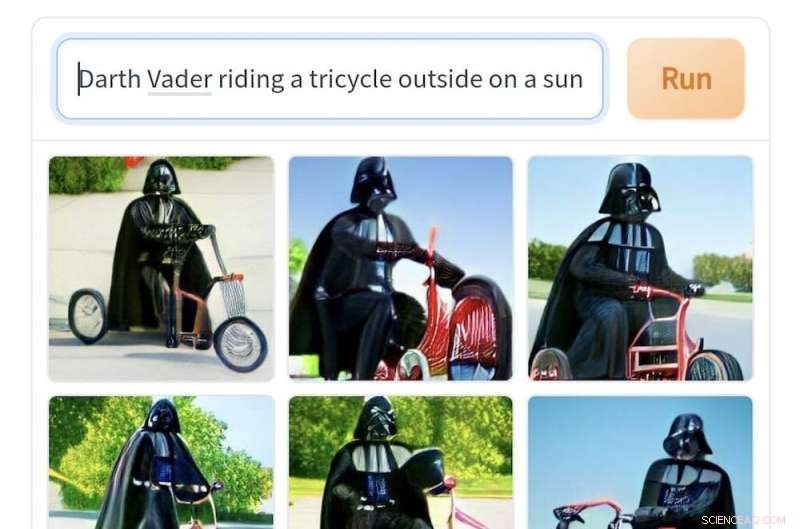
Immagini generate da Craiyon dal messaggio "Darth Vader in sella a un triciclo fuori in una giornata di sole". Credito:Pastello
Già nelle settimane successive al rilascio di Stable Diffusion, le persone hanno spinto il codice al limite di ciò che può fare.
Per fare un esempio:le persone si sono subito rese conto che, poiché un video è una sequenza di immagini, potevano modificare il codice di Stable Diffusion per generare video dal testo.
@StableDiffusion Img2Img x #ebsynth x @koe_recast TEST#stablediffusion #AIart pic.twitter.com/aZgZZBRjWM
— Scott Lighthiser (@LighthiserScott), 7 settembre 2022
Un altro strumento affascinante creato con il codice di Stable Diffusion è Diffuse the Rest, che ti consente di disegnare un semplice schizzo, fornire un prompt di testo e generare un'immagine da esso.
La fine della creatività?
Cosa significa che puoi generare qualsiasi tipo di contenuto visivo, immagine o video, con poche righe di testo e un clic di un pulsante? Che ne dici di quando puoi generare un copione di film con GPT-3 e un'animazione di film con DALL-E 2?
E guardando più avanti, cosa significherà quando gli algoritmi dei social media non solo cureranno i contenuti per il tuo feed, ma li genereranno? E quando questa tendenza incontra il metaverso in pochi anni e i mondi di realtà virtuale vengono generati in tempo reale, solo per te?
Queste sono tutte domande importanti da considerare.
Alcuni ipotizzano che, a breve termine, ciò significhi che la creatività e l'arte umane sono profondamente minacciate.
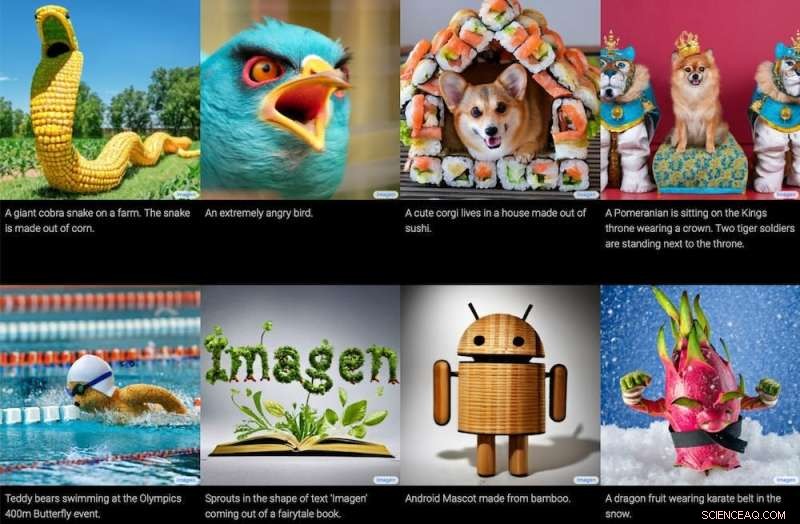
Images generated by the Imagen text-to-image model, together with the text that produced them. Google / Imagen
Perhaps in a world where anyone can generate any images, graphic designers as we know them today will be redundant. However, history shows human creativity finds a way. The electronic synthesizer did not kill music, and photography did not kill painting. Instead, they catalyzed new art forms.
I believe something similar will happen with AI generation. People are experimenting with including models like Stable Diffusion as a part of their creative process.
Or using DALL-E 2 to generate fashion-design prototypes:
Want to use @StableDiffusion right from #Photoshop? Now you can!https://t.co/gqFWpABQLY pic.twitter.com/LbgSWZz31L
— Christian Cantrell (@cantrell) September 8, 2022
A new type of artist is even emerging in what some call "promptology," or "prompt engineering". The art is not in crafting pixels by hand, but in crafting the words that prompt the computer to generate the image:a kind of AI whispering.
Collaborating with AI
The impacts of AI technologies will be multidimensional:we cannot reduce them to good or bad on a single axis.
New artforms will arise, as will new avenues for creative expression. However, I believe there are risks as well.
We live in an attention economy that thrives on extracting screen time from users; in an economy where automation drives corporate profit but not necessarily higher wages, and where art is commodified as content; in a social context where it is increasingly hard to distinguish real from fake; in sociotechnical structures that too easily encode biases in the AI models we train. In these circumstances, AI can easily do harm.
How can we steer these new AI technologies in a direction that benefits people? I believe one way to do this is to design AI that collaborates with, rather than replaces, humans. + Esplora ulteriormente
Questo articolo è stato ripubblicato da The Conversation con licenza Creative Commons. Leggi l'articolo originale.