Data Center del CERN. Credito:Robert Hradil, Monika Majer/ProStudio22.ch
Il 29 giugno 2017, il CERN DC ha superato il traguardo di 200 petabyte di dati archiviati in modo permanente nelle sue librerie a nastro. Da dove provengono questi dati? Le particelle si scontrano nei rivelatori Large Hadron Collider (LHC) circa 1 miliardo di volte al secondo, generando circa un petabyte di dati di collisione al secondo. Però, tali quantità di dati sono impossibili da registrare per gli attuali sistemi informatici e vengono quindi filtrate dagli esperimenti, mantenendo solo quelli più "interessanti". I dati LHC filtrati vengono poi aggregati nel Data Center (DC) del CERN, dove viene eseguita la ricostruzione iniziale dei dati, e dove una copia viene archiviata in un archivio su nastro a lungo termine. Anche dopo la drastica riduzione dei dati operata dagli esperimenti, il CERN DC elabora in media un petabyte di dati al giorno. Così il 29 giugno è stato raggiunto il traguardo dei 200 petabyte di dati archiviati permanentemente nelle sue tape library.
I quattro grandi esperimenti di LHC hanno prodotto volumi di dati senza precedenti negli ultimi due anni. Ciò è dovuto in gran parte alle eccezionali prestazioni e alla disponibilità dell'LHC stesso. Infatti, nel 2016, le aspettative erano inizialmente per circa 5 milioni di secondi di acquisizione dei dati, mentre il totale finale è stato di circa 7,5 milioni di secondi, un graditissimo aumento del 50%. Il 2017 sta seguendo una tendenza simile.
Ulteriore, poiché la luminosità è maggiore rispetto al 2016, molte collisioni si sovrappongono e gli eventi sono più complessi, richiedono ricostruzioni e analisi sempre più sofisticate. Questo ha un forte impatto sui requisiti di elaborazione. Di conseguenza, record vengono rotti in molti aspetti dell'acquisizione dei dati, velocità e volumi di dati, con eccezionali livelli di utilizzo delle risorse di elaborazione e archiviazione.
Per affrontare queste sfide, l'infrastruttura informatica in generale, e in particolare i sistemi di stoccaggio, ha subito importanti aggiornamenti e consolidamenti durante i due anni di Long Shutdown 1. Questi aggiornamenti hanno permesso al data center di far fronte ai 73 petabyte di dati ricevuti nel 2016 (49 dei quali erano dati LHC) e al flusso di dati consegnato finora in 2017. Questi aggiornamenti hanno anche permesso al sistema CERN Advanced STORage (CASTOR) di superare l'impegnativo traguardo di 200 petabyte di dati archiviati in modo permanente. Questi dati archiviati in modo permanente rappresentano una frazione importante della quantità totale di dati ricevuti nel data center del CERN, il resto sono dati temporanei che vengono periodicamente ripuliti.
Un'altra conseguenza dei maggiori volumi di dati è una maggiore richiesta di trasferimento dati e quindi la necessità di una maggiore capacità di rete. Dall'inizio di febbraio, un terzo circuito in fibra ottica da 100 Gb/s (gigabit al secondo) collega il CERN DC alla sua estensione remota ospitata presso il Wigner Research Center for Physics (RCP) in Ungheria, 1800 km di distanza. La larghezza di banda aggiuntiva e la ridondanza fornite da questo terzo collegamento aiutano il CERN a trarre vantaggio in modo affidabile dalla potenza di elaborazione e dall'archiviazione presso l'interno remoto. Un must-have nel contesto delle crescenti esigenze informatiche!
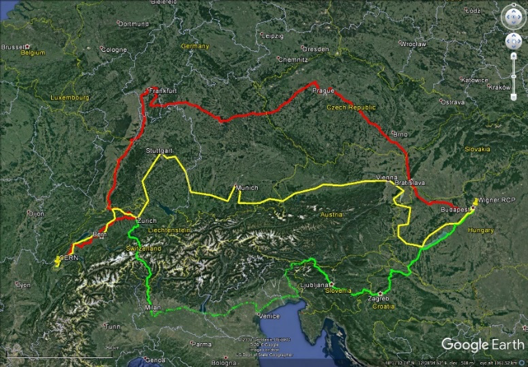
Questa mappa mostra i percorsi per i tre collegamenti in fibra a 100 Gbit/s tra il CERN e il Wigner RCP. I percorsi sono stati scelti con cura per garantire il mantenimento della connettività in caso di incidenti. (Immagine:Google)