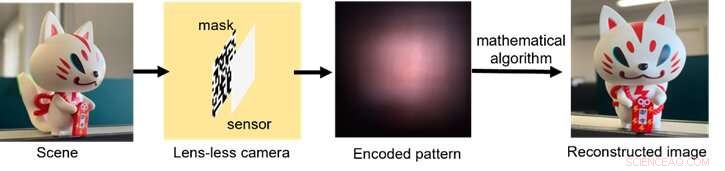
Uno schema di come funziona il processo di imaging senza lenti, dalla raccolta della luce alla codifica del segnale alla post-elaborazione con algoritmi di calcolo. Credito:Xiuxi Pan di Tokyo Tech
Una fotocamera di solito richiede un sistema di obiettivi per acquisire un'immagine focalizzata e la fotocamera con obiettivo è stata la soluzione di imaging dominante per secoli. Una fotocamera con obiettivo richiede un sistema di obiettivi complesso per ottenere immagini di alta qualità, luminose e prive di aberrazioni. Gli ultimi decenni hanno visto un aumento della domanda di fotocamere più piccole, leggere ed economiche. C'è una chiara necessità di telecamere di nuova generazione con funzionalità elevate, abbastanza compatte da poter essere installate ovunque. Tuttavia, la miniaturizzazione della fotocamera con obiettivo è limitata dal sistema di obiettivi e dalla distanza di messa a fuoco richiesta dagli obiettivi rifrattivi.
I recenti progressi nella tecnologia informatica possono semplificare il sistema di lenti sostituendo l'informatica per alcune parti del sistema ottico. L'intero obiettivo può essere abbandonato grazie all'uso del calcolo della ricostruzione dell'immagine, consentendo una fotocamera senza obiettivo, che è ultrasottile, leggera ed economica. La fotocamera senza obiettivo ha guadagnato terreno di recente. Ma finora, la tecnica di ricostruzione dell'immagine non è stata stabilita, con conseguente qualità dell'immagine inadeguata e tempo di calcolo noioso per la fotocamera senza obiettivo.
Di recente, i ricercatori hanno sviluppato un nuovo metodo di ricostruzione delle immagini che migliora i tempi di calcolo e fornisce immagini di alta qualità. Descrivendo la motivazione iniziale alla base della ricerca, un membro centrale del team di ricerca, il Prof. Masahiro Yamaguchi della Tokyo Tech, afferma:"Senza i limiti di un obiettivo, la fotocamera senza obiettivo potrebbe essere ultraminiaturizzata, il che potrebbe consentire nuove applicazioni che sono oltre la nostra immaginazione". Il loro lavoro è stato pubblicato su Optics Letters .
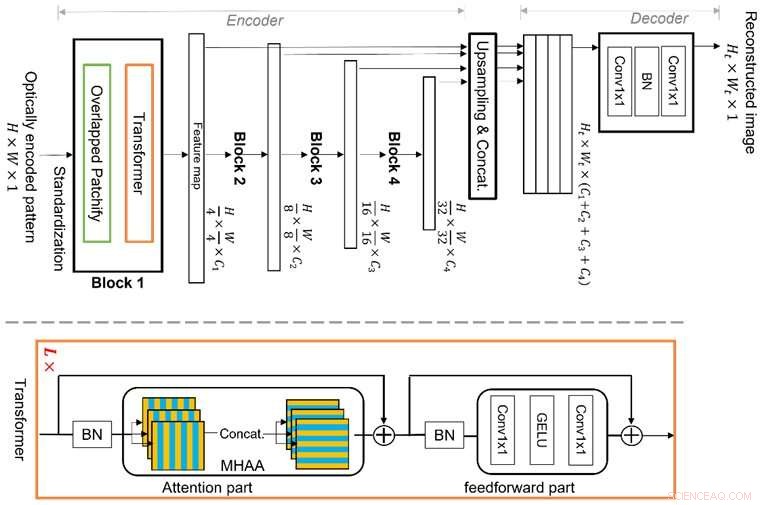
Vision Transformer (ViT) è una tecnica di apprendimento automatico all'avanguardia, che è migliore nel ragionamento delle funzionalità globali grazie alla sua nuova struttura dei blocchi trasformatore multistadio con moduli "patchify" sovrapposti. Ciò gli consente di apprendere in modo efficiente le caratteristiche dell'immagine in una rappresentazione gerarchica, rendendolo in grado di affrontare la proprietà di multiplexing ed evitare i limiti del deep learning convenzionale basato sulla CNN, consentendo così una migliore ricostruzione dell'immagine. Credito:Xiuxi Pan di Tokyo Tech
L'hardware ottico tipico della fotocamera senza obiettivo consiste semplicemente in una maschera sottile e un sensore di immagine. L'immagine viene quindi ricostruita utilizzando un algoritmo matematico. La maschera e il sensore possono essere fabbricati insieme in processi di produzione di semiconduttori consolidati per la produzione futura. La maschera codifica otticamente la luce incidente e proietta modelli sul sensore. Sebbene i modelli fusi siano completamente non interpretabili dall'occhio umano, possono essere decodificati con una conoscenza esplicita del sistema ottico.
Tuttavia, il processo di decodifica, basato sulla tecnologia di ricostruzione delle immagini, rimane impegnativo. I metodi di decodifica tradizionali basati su modelli approssimano il processo fisico dell'ottica senza lenti e ricostruiscono l'immagine risolvendo un problema di ottimizzazione "convesso". Ciò significa che il risultato della ricostruzione è suscettibile alle approssimazioni imperfette del modello fisico. Inoltre, il calcolo necessario per risolvere il problema di ottimizzazione richiede tempo perché richiede un calcolo iterativo. Il deep learning potrebbe aiutare a evitare i limiti della decodifica basata su modello, poiché può invece apprendere il modello e decodificare l'immagine mediante un processo diretto non iterativo. Tuttavia, i metodi di deep learning esistenti per l'imaging senza lenti, che utilizzano una rete neurale convoluzionale (CNN), non possono produrre immagini di alta qualità. Sono inefficienti perché la CNN elabora l'immagine in base alle relazioni dei pixel "locali" vicini, mentre l'ottica lensless trasforma le informazioni locali nella scena in informazioni "globali" sovrapposte su tutti i pixel del sensore di immagine, attraverso una proprietà chiamata "multiplexing". "

La fotocamera senza obiettivo è composta da una maschera e un sensore di immagine con una distanza di separazione di 2,5 mm. La maschera è fabbricata mediante deposizione di cromo in una lastra di silice sintetica con una dimensione dell'apertura di 40 × 40 μm. Credito:Xiuxi Pan di Tokyo Tech
Il team di ricerca di Tokyo Tech sta studiando questa proprietà multiplexing e ora ha proposto un nuovo algoritmo di apprendimento automatico dedicato per la ricostruzione delle immagini. L'algoritmo proposto si basa su una tecnica di apprendimento automatico all'avanguardia chiamata Vision Transformer (ViT), che è migliore nel ragionamento delle funzionalità globali. La novità dell'algoritmo sta nella struttura dei blocchi trasformatore multistadio con moduli "patchify" sovrapposti. Ciò consente di apprendere in modo efficiente le caratteristiche dell'immagine in una rappresentazione gerarchica. Di conseguenza, il metodo proposto può affrontare bene la proprietà multiplexing ed evitare i limiti del deep learning convenzionale basato sulla CNN, consentendo una migliore ricostruzione dell'immagine.
Sebbene i metodi convenzionali basati su modelli richiedano lunghi tempi di calcolo per l'elaborazione iterativa, il metodo proposto è più veloce perché la ricostruzione diretta è possibile con un algoritmo di elaborazione privo di iterativi progettato dall'apprendimento automatico. Anche l'influenza degli errori di approssimazione del modello è notevolmente ridotta perché il sistema di apprendimento automatico apprende il modello fisico. Inoltre, il metodo basato su ViT proposto utilizza caratteristiche globali nell'immagine ed è adatto per l'elaborazione di modelli cast su un'ampia area sul sensore di immagine, mentre i metodi di decodifica convenzionali basati sull'apprendimento automatico apprendono principalmente le relazioni locali dalla CNN.
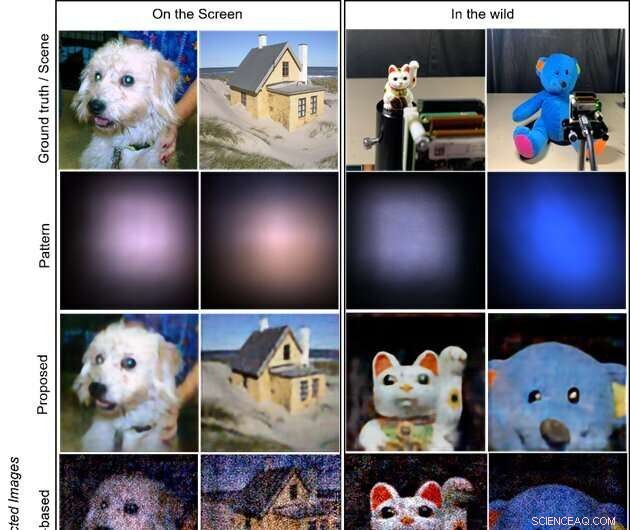
I bersagli sono rispettivamente le immagini visualizzate su uno schermo LCD (due colonne a sinistra) e gli oggetti in natura (due colonne a destra; bambola gatto che invita e orso di peluche). La prima riga mostra le immagini della verità sul terreno visualizzate sullo schermo e le scene di ripresa di oggetti in natura. La seconda riga mostra i modelli acquisiti sul sensore. Le ultime tre righe illustrano le immagini ricostruite rispettivamente con i metodi proposti, basati su modello e basati su CNN. Il metodo proposto produce immagini di altissima qualità e visivamente accattivanti. Credito:Xiuxi Pan di Tokyo Tech
In sintesi, il metodo proposto risolve i limiti dei metodi convenzionali come l'elaborazione iterativa basata sulla ricostruzione delle immagini e l'apprendimento automatico basato sulla CNN con l'architettura ViT, consentendo l'acquisizione di immagini di alta qualità in un breve lasso di tempo di calcolo. Il team di ricerca ha inoltre eseguito esperimenti ottici, come riportato nella loro ultima pubblicazione in, che suggeriscono che la fotocamera senza obiettivo con il metodo di ricostruzione proposto può produrre immagini di alta qualità e visivamente accattivanti mentre la velocità di calcolo della post-elaborazione è sufficientemente alta per il reale. cattura del tempo.
"Ci rendiamo conto che la miniaturizzazione non dovrebbe essere l'unico vantaggio della fotocamera senza obiettivo. La fotocamera senza obiettivo può essere applicata all'imaging con luce invisibile, in cui l'uso di un obiettivo è impraticabile o addirittura impossibile. Inoltre, la dimensionalità sottostante delle informazioni ottiche acquisite dalla fotocamera senza obiettivo è maggiore di due, il che rende possibile l'imaging 3D one-shot e la rifocalizzazione post-acquisizione. Stiamo esplorando più funzionalità della fotocamera senza obiettivo. L'obiettivo finale di una fotocamera senza obiettivo è essere in miniatura ma potente. Siamo entusiasta di essere all'avanguardia in questa nuova direzione per le soluzioni di imaging e rilevamento di prossima generazione", afferma l'autore principale dello studio, Xiuxi Pan di Tokyo Tech, parlando del loro lavoro futuro. + Esplora ulteriormente