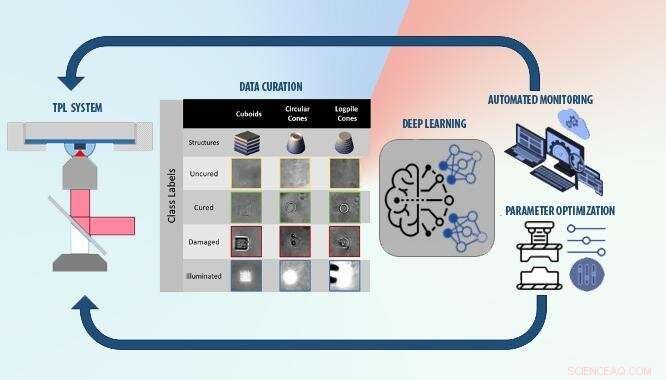
Gli scienziati e i collaboratori del Lawrence Livermore National Laboratory stanno utilizzando l'apprendimento automatico per affrontare due ostacoli chiave all'industrializzazione della litografia a due fotoni (TPL):il monitoraggio della qualità delle parti durante la stampa e la determinazione del giusto dosaggio di luce per un determinato materiale. Il team ha sviluppato un algoritmo di apprendimento automatico addestrato su migliaia di immagini video di build TPL per identificare i parametri ottimali per impostazioni come l'esposizione e l'intensità del laser e per rilevare automaticamente la qualità delle parti con elevata precisione. Credito:Lawrence Livermore National Laboratory
La litografia a due fotoni (TPL), una tecnica di nanostampa 3D ampiamente utilizzata che utilizza la luce laser per creare oggetti 3D, ha mostrato risultati promettenti nelle applicazioni di ricerca, ma deve ancora ottenere un'ampia accettazione nel settore a causa delle limitazioni alla produzione di parti su larga scala e configurazione che richiede molto tempo.
In grado di stampare caratteristiche su scala nanometrica ad una risoluzione molto elevata, TPL utilizza un raggio laser per costruire parti, focalizzando un intenso raggio di luce su un punto preciso all'interno di un materiale fotopolimero liquido. I pixel volumetrici, o "voxel, "indurire il liquido a solido in ogni punto in cui il raggio colpisce e il liquido non polimerizzato viene rimosso, lasciando dietro di sé una struttura 3-D. Costruire una parte di alta qualità con la tecnica richiede di percorrere una linea sottile:troppa poca luce e una parte non può formarsi, troppo e provoca danni. Per operatori e ingegneri, determinare il corretto dosaggio della luce può essere un processo manuale laborioso.
Gli scienziati e i collaboratori del Lawrence Livermore National Laboratory (LLNL) si sono rivolti all'apprendimento automatico per affrontare due ostacoli chiave all'industrializzazione del TPL:il monitoraggio della qualità delle parti durante la stampa e la determinazione del giusto dosaggio di luce per un determinato materiale. L'algoritmo di apprendimento automatico del team è stato addestrato su migliaia di immagini video di build etichettate come "non polimerizzate, " "curato, " e "danneggiato, " per identificare i parametri ottimali per impostazioni come l'esposizione e l'intensità del laser e per rilevare automaticamente la qualità delle parti con un'elevata precisione. Il lavoro è stato recentemente pubblicato sulla rivista Additive Manufacturing.
"Non si conoscono mai i parametri esatti per un dato materiale, quindi in genere attraversi questo terribile processo di caricamento del dispositivo, stampando centinaia di oggetti e ordinando manualmente i dati, " ha detto il ricercatore principale e ingegnere LLNL Brian Giera. "Ciò che abbiamo fatto è stato eseguire la serie di esperimenti di routine e creare un algoritmo che elabora automaticamente il video per identificare rapidamente cosa è buono e cosa è cattivo. E quello che ottieni gratuitamente da quel processo è un algoritmo che opera anche sul rilevamento della qualità in tempo reale".
Il team ha sviluppato l'algoritmo e lo ha addestrato sui dati sperimentali raccolti da Sourabh Saha, un ex ingegnere di ricerca LLNL che ora è assistente professore al Georgia Institute of Technology. Saha ha progettato gli esperimenti per mostrare chiaramente come i cambiamenti nel dosaggio della luce abbiano influenzato le transizioni tra i non polimerizzati, costruzioni curate e danneggiate, e ha stampato una serie di oggetti con due tipi di polimero fotopolimerizzabile utilizzando una stampante TPL disponibile in commercio.
"La popolarità di TPL risiede nella sua capacità di costruire una varietà di strutture 3-D arbitrariamente complesse, "Saha ha detto. "Tuttavia, ciò rappresenta una sfida per le tradizionali tecniche di monitoraggio dei processi automatizzati perché le strutture indurite possono apparire radicalmente diverse l'una dall'altra:gli esperti umani possono identificare intuitivamente le transizioni. Il nostro obiettivo qui era dimostrare che alle macchine si può insegnare questa abilità".
I ricercatori hanno raccolto più di 1, 000 video di parti di vario genere realizzate in diverse condizioni di dosaggio della luce. Xian Lee, uno studente laureato alla Iowa State University, setacciato manualmente attraverso ogni fotogramma dei video, esaminando decine di migliaia di immagini per analizzare ciascuna regione di transizione.
Utilizzando l'algoritmo di deep learning, i ricercatori hanno scoperto di poter rilevare la qualità delle parti con una precisione superiore al 95% in pochi millisecondi, creando una capacità di monitoraggio senza precedenti per il processo TPL. Giera ha affermato che gli operatori potrebbero applicare l'algoritmo a una serie iniziale di esperimenti e creare un modello preaddestrato per accelerare l'ottimizzazione dei parametri e fornire loro un modo per supervisionare il processo di costruzione e anticipare problemi come un'eccessiva polimerizzazione imprevista nel dispositivo.
"Ciò che ciò consente è un effettivo monitoraggio qualitativo dei processi dove prima non c'era la capacità di farlo, "Gera ha detto, "Un'altra caratteristica interessante è che fondamentalmente utilizza solo dati di immagine. Se avessi un'area molto ampia e sto costruendo in più posizioni di costruzione per poi assemblare una parte principale, Potrei effettivamente registrare video di tutte quelle aree, inserisci queste immagini secondarie in un algoritmo e monitora in parallelo".
Nello spirito della trasparenza, il team ha anche descritto i casi in cui l'algoritmo ha commesso errori nelle previsioni, mostrando un'opportunità per migliorare il modello per riconoscere meglio le particelle di polvere e altro particolato che potrebbe influire sulla qualità della costruzione. Il team ha rilasciato l'intero set di dati al pubblico, compreso il modello, pesi di allenamento e dati reali per un'ulteriore innovazione da parte della comunità scientifica.
"Poiché l'apprendimento automatico è un campo così evolutivo, se mettiamo i dati là fuori, questo problema può trarre beneficio da altre persone che lo risolvono. Abbiamo creato questo set di dati di partenza per il campo, e ora tutti possono andare avanti, " ha detto Giera. "Questo ci consente di beneficiare della più ampia comunità di machine learning, che potrebbe non sapere tanto sulla produzione additiva quanto noi, ma ne sa di più sulle nuove tecniche che stanno sviluppando".
Il lavoro derivava da un precedente progetto di ricerca e sviluppo diretto da laboratorio (LDRD) sulla litografia a due fotoni ed è stato completato nell'ambito di un attuale LDRD intitolato "Accelerated Multi-Modal Manufacturing Optimization (AMMO)".