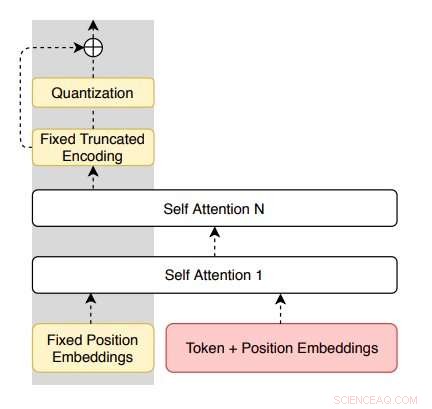
Architettura dell'encoder proposta dai ricercatori. Credito:Roy &Grangier.
Negli ultimi anni, i ricercatori hanno cercato di sviluppare metodi per la parafrasi automatica, che essenzialmente comporta l'astrazione automatizzata del contenuto semantico dal testo. Finora, gli approcci che si basano su tecniche di traduzione automatica (MT) si sono dimostrati particolarmente popolari a causa della mancanza di set di dati etichettati disponibili di coppie parafrasate.
Teoricamente, le tecniche di traduzione potrebbero apparire come soluzioni efficaci per la parafrasi automatica, in quanto astraggono il contenuto semantico dalla sua realizzazione linguistica. Ad esempio, assegnare la stessa frase a traduttori diversi potrebbe comportare traduzioni diverse e un ricco insieme di interpretazioni, che potrebbe essere utile nei compiti di parafrasi.
Sebbene molti ricercatori abbiano sviluppato metodi basati sulla traduzione per la parafrasi automatizzata, gli esseri umani non hanno necessariamente bisogno di essere bilingue per parafrasare le frasi. Sulla base di questa osservazione, due ricercatori di Google Research hanno recentemente proposto una nuova tecnica di parafrasi che non si basa su metodi di traduzione automatica. Nella loro carta, pre-pubblicato su arXiv, hanno confrontato il loro approccio monolingue con altre tecniche di parafrasi:una traduzione supervisionata e un approccio alla traduzione non supervisionata.
"Questo lavoro si propone di apprendere modelli di parafrasi solo da un corpus monolingue senza etichetta, "Aurko Roy e David Grangier, i due ricercatori che hanno condotto lo studio, hanno scritto nel loro giornale. "A quello scopo, proponiamo una variante residua dell'auto-encoder variazionale quantizzato vettoriale."
Il modello introdotto dai ricercatori si basa su auto-encoder a quantizzazione vettoriale (VQ-VAE) in grado di parafrasare frasi in un ambiente puramente monolingue. Ha anche una caratteristica unica (cioè connessioni residue parallele al collo di bottiglia quantizzato), che consente un migliore controllo sull'entropia del decodificatore e facilita l'ottimizzazione.
"Rispetto agli auto-encoder continui, il nostro metodo permette la generazione di diversi, ma chiudi semanticamente le frasi da una frase di input, " hanno spiegato i ricercatori nel loro articolo.
Nel loro studio, Roy e Grangier hanno confrontato le prestazioni del loro modello con quelle di altri approcci basati sulla MT sull'identificazione delle parafrasi, generazione e aumento della formazione. Lo hanno confrontato in modo specifico con un metodo di traduzione supervisionato addestrato su dati bilingue paralleli e un metodo di traduzione non supervisionato addestrato su testo non parallelo in due lingue diverse. Il loro modello, d'altra parte, richiede solo dati non etichettati in un'unica lingua, quello in cui sta parafrasando le frasi.
I ricercatori hanno scoperto che il loro approccio monolingue ha superato le tecniche di traduzione non supervisionata in tutte le attività. Confronti tra il loro modello e metodi di traduzione supervisionati, d'altra parte, ha prodotto risultati contrastanti:l'approccio monolingue ha ottenuto risultati migliori nelle attività di identificazione e aumento, mentre il metodo di traduzione supervisionato era superiore per la generazione di parafrasi.
"Globale, abbiamo dimostrato che i modelli monolingui possono superare quelli bilingue per l'identificazione della parafrasi e l'aumento dei dati attraverso la parafrasi, " hanno concluso i ricercatori. "Abbiamo anche riferito che la qualità della generazione da modelli monolingue può essere superiore rispetto ai modelli basati sulla traduzione non supervisionata, ma non traduzione controllata."
I risultati di Roy e Grangier suggeriscono che l'uso di dati paralleli bilingue (cioè testi e le loro possibili traduzioni in altre lingue) è particolarmente vantaggioso quando si generano parafrasi e porta a prestazioni notevoli. In situazioni in cui i dati bilingue non sono prontamente disponibili, però, il modello monolingue da loro proposto potrebbe essere una risorsa utile o una soluzione alternativa.
© 2019 Scienza X Rete