Attestazione:arXiv:1905.09773 [cs.CV]
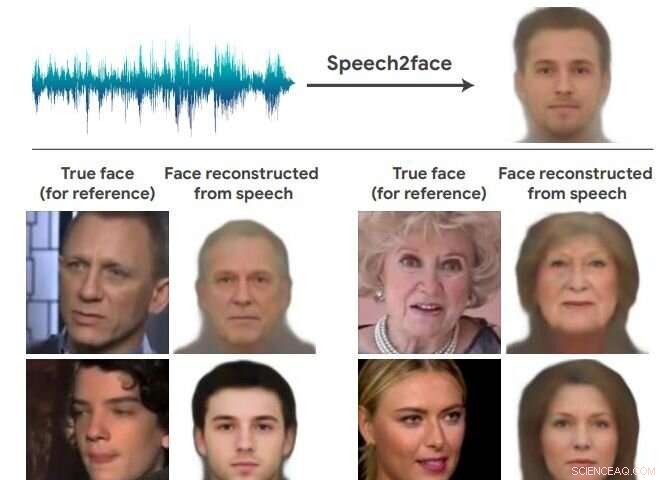
Di nuovo, I team di intelligenza artificiale prendono in giro il regno dell'impossibile e forniscono risultati sorprendenti. Questa squadra delle notizie ha capito come potrebbe apparire il viso di una persona solo in base alla voce. Benvenuto in Speech2Face. Il team di ricerca ha trovato un modo per ricostruire la somiglianza molto approssimativa di alcune persone sulla base di brevi clip audio.
Il documento che descrive il loro lavoro è su arXiv, ed è intitolato "Speech2Face:Imparare il volto dietro una voce". Gli autori sono Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William Freemany, Michael Rubinstein e Wojciech Matusiky. "Il nostro obiettivo in questo lavoro è studiare fino a che punto possiamo dedurre l'aspetto di una persona dal modo in cui parla".
Valutano e quantificano numericamente come, e in che modo, le loro ricostruzioni Speech2Face dall'audio assomigliano alle vere immagini del viso degli oratori.
Gli autori apparentemente volevano assicurarsi che il loro intento fosse chiaro, non come un tentativo di collegare le voci con le immagini delle persone specifiche che hanno effettivamente parlato, come "il nostro obiettivo non è quello di prevedere un'immagine riconoscibile del volto esatto, ma piuttosto per catturare tratti facciali dominanti della persona che sono correlati con il discorso in ingresso."
Gli autori di GitHub hanno affermato di ritenere importante anche discutere nel documento considerazioni etiche "a causa della potenziale sensibilità delle informazioni facciali".
Hanno detto nel loro articolo che il loro metodo "non può recuperare la vera identità di una persona dalla sua voce (cioè, un'immagine esatta del loro volto). Questo perché il nostro modello è addestrato a catturare le caratteristiche visive (correlate all'età, Genere, ecc.) comuni a molti individui, e solo nei casi in cui ci sono prove abbastanza forti per collegare quelle caratteristiche visive con attributi vocali / vocali nei dati".
Hanno anche affermato che il modello produrrà volti dall'aspetto medio, solo volti dall'aspetto medio, con caratteristiche visive caratteristiche correlate al discorso di input.
Jackie Snow, Azienda veloce , scritto sul loro metodo. Snow ha detto che il set di dati che hanno preso era composto da clip di YouTube. Speech2Face è stato addestrato da scienziati su video da Internet che mostravano persone che parlavano. Hanno creato un modello basato su rete neurale che "apprende gli attributi vocali associati alle caratteristiche del viso dai video".
Neve ha aggiunto, "Ora, quando il sistema sente un nuovo morso sonoro, l'intelligenza artificiale può usare ciò che ha imparato per indovinare come potrebbe essere il viso."
neuroalveare hanno discusso del loro lavoro:"Dai video, estraggono coppie discorso-faccia, che sono alimentati in due rami dell'architettura. Le immagini sono codificate in un vettore latente utilizzando il modello di riconoscimento facciale pre-addestrato, mentre la forma d'onda viene immessa in un codificatore vocale sotto forma di spettrogramma, per sfruttare la potenza delle architetture convoluzionali. Il vettore codificato dal codificatore vocale viene immesso nel decodificatore del viso per ottenere la ricostruzione finale del viso".
Si può anche ottenere un resoconto preciso sul loro metodo e su come hanno testato con un articolo su pacchetto :
"Hanno detto di aver ulteriormente valutato e quantificato numericamente come ricostruisce il loro Speech2Face, ottiene risultati direttamente dall'audio, e come assomiglia alle vere immagini del viso degli altoparlanti. Per questo, hanno testato il loro modello sia qualitativamente che quantitativamente sul set di dati AVSpeech e sul set di dati VoxCeleb."
In che modo le loro scoperte potrebbero aiutare le applicazioni del mondo reale? Loro hanno detto, "crediamo che la previsione delle immagini dei volti direttamente dalla voce possa supportare applicazioni utili, come allegare un volto rappresentativo alle telefonate/videochiamate in base alla voce dell'oratore."
Perché il loro lavoro è importante:Pensa ai modelli. "La ricerca precedente ha esplorato metodi per prevedere l'età e il sesso dal discorso, " disse Neve, "ma in questo caso i ricercatori affermano di aver anche rilevato correlazioni con alcuni modelli facciali".
© 2019 Scienza X Rete