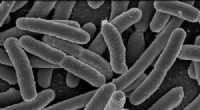
I ricercatori del MIT hanno sviluppato un sistema che raccoglie dati di allenamento molto più etichettati da dati non etichettati, che potrebbe aiutare i modelli di apprendimento automatico a rilevare meglio i modelli strutturali nelle scansioni cerebrali associate a malattie neurologiche. Il sistema apprende le variazioni strutturali e di aspetto nelle scansioni senza etichetta, e utilizza tali informazioni per modellare e modellare una scansione etichettata in migliaia di nuove, scansioni etichettate distinte. Credito:Amy Zhao/MIT
I ricercatori del MIT hanno ideato un nuovo metodo per raccogliere più informazioni dalle immagini utilizzate per addestrare modelli di apprendimento automatico, compresi quelli che possono analizzare le scansioni mediche per aiutare a diagnosticare e trattare le condizioni cerebrali.
Una nuova area attiva in medicina prevede la formazione di modelli di apprendimento profondo per rilevare modelli strutturali nelle scansioni cerebrali associati a malattie e disturbi neurologici, come il morbo di Alzheimer e la sclerosi multipla. Ma raccogliere i dati di allenamento è laborioso:tutte le strutture anatomiche in ogni scansione devono essere delineate separatamente o etichettate a mano da esperti neurologici. E, in alcuni casi, come per rare condizioni cerebrali nei bambini, in primo luogo potrebbero essere disponibili solo poche scansioni.
In un articolo presentato alla recente Conferenza su Computer Vision and Pattern Recognition, i ricercatori del MIT descrivono un sistema che utilizza una singola scansione etichettata, insieme a scansioni senza etichetta, per sintetizzare automaticamente un enorme set di dati di esempi di addestramento distinti. Il set di dati può essere utilizzato per addestrare meglio i modelli di apprendimento automatico per trovare strutture anatomiche in nuove scansioni:più dati di addestramento, migliori sono queste previsioni.
Il punto cruciale del lavoro è la generazione automatica dei dati per il processo di "segmentazione dell'immagine", che suddivide un'immagine in regioni di pixel più significative e più facili da analizzare. Fare così, il sistema utilizza una rete neurale convoluzionale (CNN), un modello di apprendimento automatico che è diventato una centrale elettrica per le attività di elaborazione delle immagini. La rete analizza molte scansioni non etichettate di diversi pazienti e diverse apparecchiature per "imparare" l'anatomia, luminosità, e variazioni di contrasto. Quindi, applica una combinazione casuale di quelle variazioni apprese a una singola scansione etichettata per sintetizzare nuove scansioni che siano sia realistiche che etichettate accuratamente. Queste scansioni appena sintetizzate vengono quindi inviate a una CNN diversa che impara a segmentare nuove immagini.
"Speriamo che questo renda la segmentazione dell'immagine più accessibile in situazioni realistiche in cui non si hanno molti dati di addestramento, " dice la prima autrice Amy Zhao, uno studente laureato presso il Dipartimento di Ingegneria Elettrica e Informatica (EECS) e Laboratorio di Informatica e Intelligenza Artificiale (CSAIL). "Nel nostro approccio, puoi imparare a imitare le variazioni nelle scansioni senza etichetta per sintetizzare in modo intelligente un grande set di dati per addestrare la tua rete."
C'è interesse nell'usare il sistema, ad esempio, per aiutare a formare modelli di analisi predittiva presso il Massachusetts General Hospital, Zhao dice, dove possono esistere solo una o due scansioni etichettate di condizioni cerebrali particolarmente rare tra i pazienti bambini.
Insieme a Zhao sulla carta ci sono:Guha Balakrishnan, un postdoc in EECS e CSAIL; professori EECS Fredo Durand e John Guttag, e autore senior Adrian Dalca, che è anche membro della facoltà di radiologia presso la Harvard Medical School.
La "Magia" dietro il sistema
Sebbene ora applicato all'imaging medico, il sistema in realtà è nato come mezzo per sintetizzare i dati di allenamento per un'app per smartphone in grado di identificare e recuperare informazioni sulle carte dal popolare gioco di carte collezionabili, "Magia:l'adunata". Uscito nei primi anni '90, "Magic" ha più di 20, 000 carte uniche, con altre rilasciate ogni pochi mesi, che i giocatori possono utilizzare per creare mazzi di gioco personalizzati.
Zhao, un appassionato giocatore di "Magia", voleva sviluppare un'app basata sulla CNN che scattasse una foto di qualsiasi carta con la fotocamera di uno smartphone e estraesse automaticamente informazioni come prezzo e valutazione dai database delle carte online. "Quando stavo scegliendo le carte da un negozio di giochi, Mi sono stancato di inserire tutti i loro nomi nel telefono e cercare valutazioni e combo, " dice Zhao. "Non sarebbe fantastico se potessi scansionarli con il mio telefono e recuperare queste informazioni?"
Ma si è resa conto che è un compito di addestramento alla visione artificiale molto difficile. "Avresti bisogno di molte foto di tutti e 20, 000 carte, in tutte le diverse condizioni di illuminazione e angoli. Nessuno raccoglierà quel set di dati, " dice Zhao.
Anziché, Zhao ha addestrato una CNN su un set di dati più piccolo di circa 200 carte, con 10 foto distinte di ogni carta, per imparare a deformare una carta in varie posizioni. Ha calcolato un'illuminazione diversa, angoli, e riflessi, per quando le carte vengono inserite in buste di plastica, a versioni deformate realistiche sintetizzate di qualsiasi carta nel set di dati. È stato un progetto di passione entusiasmante, Zhao afferma:"Ma ci siamo resi conto che questo approccio era davvero adatto per le immagini mediche, perché questo tipo di deformazione si adatta molto bene alla risonanza magnetica."
Distorsione della mente
Le immagini di risonanza magnetica (MRI) sono composte da pixel tridimensionali, chiamati voxel. Quando si segmenta la risonanza magnetica, gli esperti separano ed etichettano le regioni voxel in base alla struttura anatomica che le contiene. La diversità delle scansioni, causati da variazioni nei singoli cervelli e nelle apparecchiature utilizzate, pone una sfida all'utilizzo dell'apprendimento automatico per automatizzare questo processo.
Alcuni metodi esistenti possono sintetizzare esempi di addestramento da scansioni etichettate utilizzando "aumento dei dati, " che deforma i voxel etichettati in posizioni diverse. Ma questi metodi richiedono che gli esperti scrivano a mano varie linee guida per l'aumento, e alcune scansioni sintetizzate non assomigliano per niente a un cervello umano realistico, che può essere dannoso per il processo di apprendimento.
Anziché, il sistema dei ricercatori impara automaticamente come sintetizzare scansioni realistiche. I ricercatori hanno addestrato il loro sistema su 100 scansioni senza etichetta di pazienti reali per calcolare trasformazioni spaziali, corrispondenze anatomiche da scansione a scansione. Questo ha generato altrettanti "campi di flusso, " che modellano il modo in cui i voxel si spostano da una scansione all'altra. Contemporaneamente, calcola le trasformazioni di intensità, che catturano le variazioni di aspetto causate dal contrasto dell'immagine, rumore, e altri fattori.
Nella generazione di una nuova scansione, il sistema applica un campo di flusso casuale alla scansione etichettata originale, che si sposta intorno ai voxel finché non corrisponde strutturalmente a un reale, scansione senza etichetta. Quindi, si sovrappone a una trasformazione di intensità casuale. Finalmente, il sistema mappa le etichette alle nuove strutture, seguendo come si sono mossi i voxel nel campo di flusso. Alla fine, le scansioni sintetizzate assomigliano molto a quelle reali, scansioni senza etichetta, ma con etichette accurate.
Per testare la loro precisione di segmentazione automatizzata, i ricercatori hanno utilizzato i punteggi Dice, che misurano quanto bene una forma 3D si adatta a un'altra, su una scala da 0 a 1. Hanno confrontato il loro sistema con i metodi di segmentazione tradizionali, manuali e automatizzati, su 30 diverse strutture cerebrali attraverso 100 scansioni di prova trattenute. Le grandi strutture erano comparabilmente accurate tra tutti i metodi. Ma il sistema dei ricercatori ha superato tutti gli altri approcci su strutture più piccole, come l'ippocampo, che occupa solo circa lo 0,6 percento di un cervello, per volume.
"Ciò dimostra che il nostro metodo migliora rispetto ad altri metodi, soprattutto quando si entra nelle strutture più piccole, che può essere molto importante per comprendere la malattia, " dice Zhao. "E lo abbiamo fatto mentre avevamo solo bisogno di una singola scansione etichettata a mano".
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.