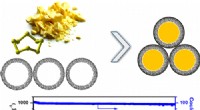
Immagini fisse di esempio di traduzioni generate dal modello (la riga superiore sono immagini umane reali, la riga in basso sono immagini di robot falsi). Credito:Smith et al.
Negli ultimi anni, i team di ricerca di tutto il mondo hanno utilizzato l'apprendimento per rinforzo (RL) per insegnare ai robot come completare una serie di compiti. Allenando questi algoritmi, però, può essere molto impegnativo, poiché richiede anche notevoli sforzi umani per definire correttamente i compiti che il robot deve completare.
Un modo per insegnare ai robot come completare compiti specifici è attraverso dimostrazioni umane. Anche se questo può sembrare semplice, può essere molto difficile da implementare, principalmente perché i robot e gli umani hanno corpi molto diversi, quindi sono capaci di movimenti diversi.
I ricercatori dell'Università della California Berkeley hanno recentemente sviluppato una nuova struttura che potrebbe aiutare a superare alcune delle sfide incontrate durante l'addestramento dei robot tramite l'apprendimento per imitazione (ad es. usando dimostrazioni umane). Il loro quadro, chiamato AVID, in base a due modelli di deep learning sviluppati in precedenti ricerche.
"Durante lo sviluppo di AVID, abbiamo costruito in gran parte su due opere recenti, CicloGAN e SOLARE, che ha introdotto approcci per affrontare le limitazioni fondamentali che hanno precluso l'apprendimento dai video umani nel cambio di dominio e l'addestramento su un robot fisico dall'input visivo, rispettivamente, "Laura Smith, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore.
Invece di utilizzare tecniche che non tengono conto delle differenze tra un robot e il corpo di un utente umano, Smith e i suoi colleghi hanno utilizzato Cycle-GAN, una tecnica in grado di trasformare le immagini a livello di pixel. Utilizzando Cycle-GAN, il loro metodo converte le dimostrazioni umane su come completare un determinato compito in video di un robot che completa lo stesso compito. Hanno quindi utilizzato questi video per sviluppare una funzione di ricompensa per un algoritmo RL.

Immagini fisse di esempio di traduzioni generate dal modello (la riga superiore sono immagini umane reali, la riga in basso sono immagini di robot falsi). Credito:Smith et al.
"AVID funziona facendo in modo che il robot osservi un essere umano mentre esegue alcuni compiti, quindi immagina come sarebbe se eseguisse la stessa cosa, " ha spiegato Smith. "Per imparare come raggiungere effettivamente questo successo immaginato, lasciamo che il robot impari per tentativi ed errori."
Utilizzando il framework sviluppato da Smith e dai suoi colleghi, un robot impara i compiti un passo alla volta, reimpostando ogni fase e riprovando senza richiedere l'intervento di un utente umano. Il processo di apprendimento diventa così in gran parte automatizzato, con il robot che apprende nuove abilità con il minimo intervento umano.
"Un vantaggio chiave del nostro approccio è che l'insegnante umano può interagire con lo studente robot mentre sta imparando, "Spiegò Smith. "Inoltre, progettiamo la nostra struttura di formazione per essere suscettibili di apprendere comportamenti a lungo termine con il minimo sforzo."
I ricercatori hanno valutato il loro approccio in una serie di prove e hanno scoperto che può insegnare efficacemente ai robot come completare compiti complessi, come il funzionamento di una macchina da caffè, semplicemente elaborando 20 minuti di video dimostrativi umani grezzi e praticando la nuova abilità per 180 minuti. Inoltre, AVID ha superato tutte le altre tecniche a cui era destinato, compresa l'ablazione per imitazione, ablazione pixel-space, e approcci di clonazione comportamentale.
"Quello che abbiamo scoperto è che possiamo sfruttare CycleGAN per rendere in modo efficace i video delle dimostrazioni umane comprensibili al robot senza richiedere un noioso processo di raccolta dati, "Smith ha detto. "Mostriamo anche che sfruttando la natura a più stadi di attività temporalmente estese ci consente di apprendere comportamenti robusti rendendo facile la formazione. Consideriamo il nostro lavoro un passo significativo verso l'implementazione nel mondo reale di robot autonomi a portata di mano in quanto ci offre un'esperienza molto naturale, modo intuitivo per insegnarglielo."
Il nuovo quadro di apprendimento introdotto da Smith e dai suoi colleghi consente un diverso tipo di apprendimento per imitazione, dove un robot impara a completare un obiettivo di livello superiore alla volta, concentrandosi su ciò che trova più impegnativo in ogni fase. Inoltre, invece di richiedere agli utenti umani di ripristinare la scena dopo ogni prova pratica, consente ai robot di ripristinare automaticamente la scena e continuare a esercitarsi. Nel futuro, AVID potrebbe migliorare i processi di apprendimento per imitazione, consentendo agli sviluppatori di addestrare i robot in modo più rapido ed efficace.
"Uno dei principali limiti del nostro lavoro finora è che richiediamo la raccolta dei dati e l'addestramento del CycleGAN per ogni nuova scena che il robot potrebbe incontrare. Speriamo di essere in grado di trattare l'addestramento CycleGAN come una volta, costo iniziale tale che l'addestramento una volta su un grande corpus di dati può consentire al robot di acquisire molto rapidamente un'ampia varietà di abilità con poche dimostrazioni e un po' di pratica."
© 2020 Scienza X Rete