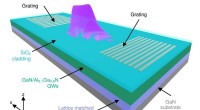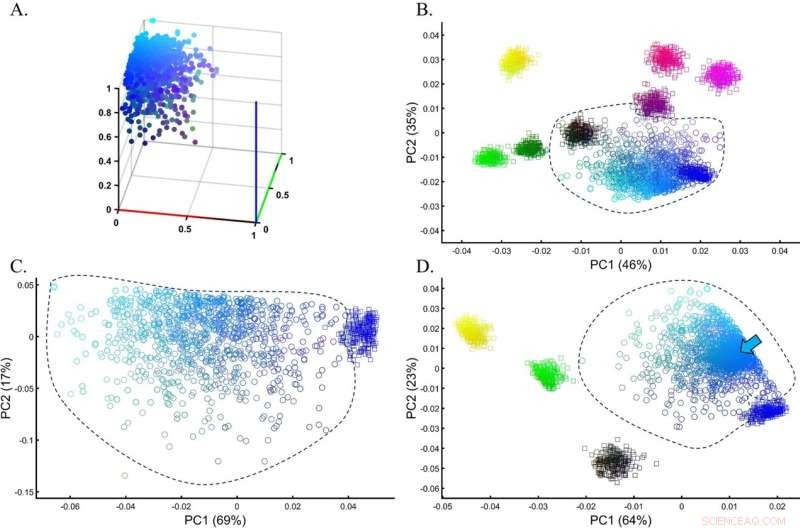
Valutazione dell'accuratezza del clustering PCA per una popolazione di test eterogenea in una simulazione di un'impostazione GWAS. (A) La vera distribuzione della popolazione ciano del test (n = 1000). (B) PCA della popolazione di prova con otto campioni di dimensioni pari (n = 250) da popolazioni di riferimento. (C) La PCA della popolazione di prova con Blue dell'analisi precedente mostra una sovrapposizione minima tra le coorti. (D) PCA della popolazione di prova con cinque campioni di dimensioni pari (n = 250) da popolazioni di riferimento, incluso ciano (contrassegnato da una freccia). I colori (B) dall'alto in basso e da sinistra a destra includono:giallo [1,1,0], rosso chiaro [1,0,0,5], viola [1,0,1], viola scuro [0,5,0,0,5 ], Nero [0,0,0], Verde scuro [0,0.5,0], Verde [0,1,0] e Blu [1,0,0]. Credito:Rapporti scientifici (2022). DOI:10.1038/s41598-022-14395-4
Il metodo analitico più comune all'interno della genetica delle popolazioni è profondamente imperfetto, secondo un nuovo studio dell'Università di Lund in Svezia. Ciò potrebbe aver portato a risultati errati e idee sbagliate sull'etnia e sulle relazioni genetiche. Il metodo è stato utilizzato in centinaia di migliaia di studi, influenzando i risultati all'interno della genetica medica e persino i test di ascendenza commerciale. Lo studio è pubblicato in Rapporti scientifici .
La velocità con cui i dati scientifici possono essere raccolti sta aumentando in modo esponenziale, portando a set di dati enormi e altamente complessi, soprannominati la "rivoluzione dei Big Data". Per rendere questi dati più gestibili, i ricercatori utilizzano metodi statistici che mirano a compattare e semplificare i dati pur conservando la maggior parte delle informazioni chiave. Forse il metodo più utilizzato è chiamato PCA (analisi dei componenti principali). Per analogia, pensa al PCA come a un forno con farina, zucchero e uova come input di dati. Il forno può fare sempre la stessa cosa, ma il risultato, una torta, dipende in modo critico dalle proporzioni degli ingredienti e da come vengono combinati.
"Ci si aspetta che questo metodo dia risultati corretti perché è usato così frequentemente. Ma non è né una garanzia di affidabilità né produce conclusioni statisticamente solide", afferma il dott. Eran Elhaik, professore associato di biologia cellulare molecolare presso l'Università di Lund.
Secondo Elhaik, il metodo ha contribuito a creare vecchie percezioni su razza ed etnia. Svolge un ruolo nella produzione di racconti storici su chi e da dove provengono le persone, non solo dalla comunità scientifica ma anche dalle aziende di ascendenza commerciale. Un esempio famoso è quando un importante politico americano ha fatto un test di ascendenza prima della campagna presidenziale del 2020 per sostenere le sue affermazioni ancestrali. Un altro esempio è l'idea sbagliata degli ebrei ashkenaziti come una razza o un gruppo isolato guidato dai risultati dell'APC.
"Questo studio dimostra che quei risultati non erano affidabili", afferma Eran Elhaik.
La PCA è utilizzata in molti campi scientifici, ma lo studio di Elhaik si concentra sul suo utilizzo nella genetica delle popolazioni, dove l'esplosione delle dimensioni dei set di dati è particolarmente acuta, a causa dei costi ridotti del sequenziamento del DNA.
Il campo della paleogenomica, dove vogliamo conoscere i popoli antichi e gli individui come gli europei dell'età del rame, fa molto affidamento sulla PCA. La PCA viene utilizzata per creare una mappa genetica che posiziona il campione sconosciuto accanto a campioni di riferimento noti. Finora, si presume che i campioni sconosciuti siano correlati alla popolazione di riferimento a cui si sovrappongono o si trovano più vicini sulla mappa.
Tuttavia, Elhaik scoprì che il campione sconosciuto poteva essere fatto giacere praticamente vicino a qualsiasi popolazione di riferimento semplicemente modificando il numero e il tipo dei campioni di riferimento, generando versioni storiche praticamente infinite, tutte matematicamente "corrette", ma solo una poteva essere biologicamente corretta .
Nello studio, Elhaik ha esaminato le dodici applicazioni genetiche di popolazione più comuni della PCA. Ha utilizzato dati genetici simulati e reali per mostrare quanto possano essere flessibili i risultati della PCA. Secondo Elhaik, questa flessibilità significa che le conclusioni basate sulla PCA non possono essere attendibili poiché qualsiasi modifica al riferimento o ai campioni di prova produrrà risultati diversi.
Tra 32.000 e 216.000 articoli scientifici sulla sola genetica hanno utilizzato la PCA per esplorare e visualizzare somiglianze e differenze tra individui e popolazioni e hanno basato le loro conclusioni su questi risultati.
"Credo che questi risultati debbano essere rivalutati", afferma Elhaik.
Spera che il nuovo studio svilupperà un approccio migliore per mettere in discussione i risultati e quindi contribuirà a rendere la scienza più affidabile. Ha trascorso gran parte dell'ultimo decennio sperimentando metodi come la struttura geografica della popolazione (GPS), per prevedere la biogeografia dal DNA, e Pairwise Matcher, che migliora le corrispondenze caso-controllo utilizzate nei test genetici e nelle sperimentazioni sui farmaci.
"Le tecniche che offrono tale flessibilità incoraggiano la cattiva scienza e sono particolarmente pericolose in un mondo in cui c'è un'intensa pressione alla pubblicazione. Se un ricercatore esegue più volte la PCA, la tentazione sarà sempre quella di selezionare l'output che rende la storia migliore", aggiunge il prof. William Amos, dell'Università di Cambridge, che non è stato coinvolto nello studio. + Esplora ulteriormente