Le previsioni dei suoni sono state ottenute con un metodo migliorato sviluppato da un team internazionale di ricercatori. Credito: IEEE/CAA Journal of Automatica Sinica
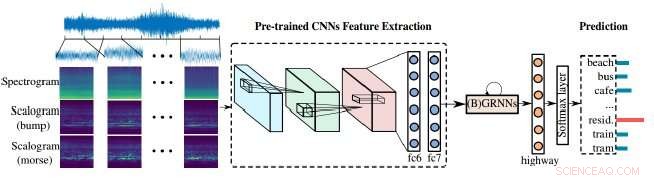
I ricercatori hanno dimostrato un metodo migliorato per le macchine di analisi audio per elaborare il nostro mondo rumoroso. Il loro approccio si basa sulla combinazione di scalogrammi e spettrogrammi, le rappresentazioni visive dell'audio, nonché di reti neurali convoluzionali (CNN), gli strumenti di apprendimento utilizzati dalle macchine per analizzare meglio le immagini visive. In questo caso, le immagini visive vengono utilizzate per analizzare l'audio per identificare e classificare meglio il suono.
Il team ha pubblicato i risultati sulla rivista IEEE/CAA Journal of Automatica Sinica ( JAS ), una pubblicazione congiunta dell'IEEE e dell'Associazione cinese di automazione.
"Le macchine hanno fatto grandi progressi nell'analisi della parola e della musica, ma l'analisi generale del suono è rimasta molto indietro—di solito, "eventi" sonori per lo più isolati come colpi di pistola e simili sono stati presi di mira in passato, " ha detto Björn Schuller, professore e cattedra di Embedded Intelligence per l'assistenza sanitaria e il benessere presso l'Università di Augsburg in Germania, che ha condotto la ricerca. "L'audio del mondo reale è di solito un mix altamente miscelato di diverse sorgenti sonore, ognuna delle quali ha stati e tratti diversi".
Schuller addita il rumore di un'auto come esempio. Non è un singolo evento audio; parti piuttosto diverse delle parti dell'auto, i suoi pneumatici interagiscono con la strada, il marchio e la velocità dell'auto forniscono tutte le proprie firme uniche.
"Allo stesso tempo, potrebbe esserci musica o discorsi in macchina, " disse Schuller, che è anche professore associato di Machine Learning presso l'Imperial College di Londra, e visiting professor presso la School of Computer Science and Technology presso l'Harbin Institute of Technology in Cina. "Una volta che i computer possono comprendere tutte le parti di questa 'scena acustica', saranno considerevolmente più bravi a scomponerlo in ciascuna parte e ad attribuire ciascuna parte come descritto."
Gli spettrogrammi forniscono una rappresentazione visiva di scene audio, ma hanno una risoluzione tempo-frequenza fissa, questo è il momento in cui le frequenze cambiano. Scalogrammi, d'altra parte, offrono una rappresentazione visiva più dettagliata delle scene acustiche rispetto agli spettrogrammi, ad esempio, scene acustiche come la musica o il discorso o altri suoni nell'auto ora possono essere rappresentate meglio.
"Di solito ci sono più suoni che accadono in una scena quindi... ci dovrebbero essere più frequenze e cambiano con il tempo, " disse Zhao Ren, un autore sulla carta e un dottorato di ricerca. candidato all'Università di Augusta che lavora con Schuller. "Fortunatamente, scalograms potrebbe risolvere esattamente questo problema poiché incorpora più scale."
"Gli scalagrammi possono essere impiegati per aiutare gli spettrogrammi nell'estrazione di caratteristiche per la classificazione della scena acustica, "Ren ha detto, e sia gli spettrogrammi che gli scalogrammi devono essere in grado di imparare per continuare a migliorare.
"Ulteriore, le reti neurali pre-addestrate creano un ponte tra [l']immagine e l'elaborazione audio".
Le reti neurali pre-addestrate utilizzate dagli autori sono le reti neurali convoluzionali (CNN). Le CNN si ispirano al modo in cui i neuroni funzionano nella corteccia visiva degli animali e le reti neurali artificiali possono essere utilizzate per elaborare con successo le immagini visive. Tali reti sono cruciali nell'apprendimento automatico, e in questo caso, aiutando a migliorare gli scalogrammi.
Le CNN ricevono un po' di addestramento prima di essere applicate a una scena, ma imparano principalmente dall'esposizione. Imparando i suoni da una combinazione di diverse frequenze e scale, l'algoritmo può prevedere meglio le fonti e, infine, prevedere il risultato di un rumore insolito, come un malfunzionamento del motore di un'auto.
"L'obiettivo finale è ascoltare/ascoltare la macchina in modo olistico... attraverso il discorso, musica, e suona proprio come farebbe un essere umano, "Schuller ha detto, osservando che ciò si unirebbe al lavoro già avanzato nell'analisi del parlato per fornire una comprensione più ricca e più profonda, "per poi essere in grado di ottenere 'l'intera immagine' nell'audio."