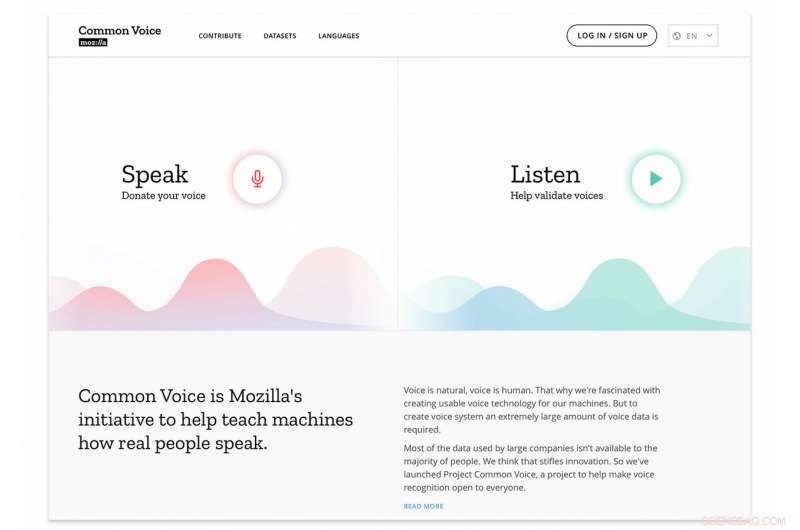
Questo può sembrare un boccone, ma significa davvero molto. Mozilla sta parlando del "più grande set di dati vocali trascritti di dominio pubblico fino ad oggi". Traduzione:Oltre 14 anni, 000 persone. In 18 lingue. Di quasi 1, 400 ore (1, 368 per l'esattezza) di voce registrata. Benvenuti a un'iniziativa chiamata Common Voice.
Questo è ciò che diceva l'annuncio di Mozilla, sotto forma di blog giovedì da George Roter.
"Oggi, siamo entusiasti di condividere il nostro primo set di dati multilingue con 18 lingue rappresentate, compreso l'inglese, Francese, tedesco e cinese mandarino (tradizionale), ma anche per esempio Welsh e Kabyle. Del tutto, il nuovo set di dati include circa 1, 400 ore di clip vocali da più di 42, 000 persone".
I contributori al progetto hanno specialità professionali che vanno dai dottorandi in riconoscimento vocale agli scienziati dell'apprendimento automatico a un professore di linguistica computazionale. Come tale, lo sforzo rappresenta una comunità globale di contributori vocali insieme a quelli che Mozilla ha accreditato come "volontari appassionati".
Lo scopo di Common Voice è aiutare a insegnare alle macchine come parlano le persone reali. In breve, si è evoluto in un'enorme raccolta di clip vocali in dozzine di lingue. Passaggi successivi:il set di dati completo sarà disponibile per il download sul sito Common Voice.
Sembra che anche i collaboratori del team Mozilla abbiano risolto gli inevitabili punti dolenti. Il blog ha menzionato questi punti. "Le persone che contribuiscono non solo vedono i progressi per lingua nella registrazione e nella convalida, ma hanno anche prompt migliorati che variano da clip a clip; nuova funzionalità da rivedere, ri-registrare, e saltare le clip come parte integrante dell'esperienza; la capacità di muoversi rapidamente tra parlare e ascoltare; così come una funzione per rinunciare a parlare per una sessione."
Sembra divertente o una sandbox accademica, ma in realtà ci sono aspirazioni più solide tra coloro che hanno contribuito a costruire il suo corpus.
Nel 2019, Mariella Moon in Engadget ha notato che la gamma di lingue ora include l'olandese, Hakha-Chin, Esperanto, farsi, basco, Spagnolo, Francese, Tedesco, cinese mandarino (tradizionale), Gallese e Kabyle.
TechRadar di Olivia Tambini, disse, "Fornendo gratuitamente una vasta libreria di voci umane in una vasta gamma di lingue, Mozilla potrebbe aprire le porte ad aziende che non hanno le risorse di Apple, Amazzonia, e Google, sviluppare i propri assistenti vocali."
Un altro vantaggio riguarda Mozilla stesso. Mariella Moon in Engadget disse, "L'organizzazione stessa prevede di utilizzare le clip che raccoglie per migliorare il suo Speech-to-Text, Motori Text-to-Speech e DeepSpeech."
Roter ha detto, chiaro e semplice, "Il nostro obiettivo è rilasciare noi stessi prodotti abilitati alla voce, sostenendo anche ricercatori e attori più piccoli".
Nota che i diritti di vanteria appartengono ad esso essendo il più grande, non l'unico, set di dati nel suo genere. Mozilla voleva che i visitatori del sito sapessero che era il più grande, non l'unico, e ha anche affermato che nel tempo i visitatori del sito possono "guardare a questa pagina come hub di riferimento per altri set di dati vocali open source".
Se visiti il sito di Common Voice, ricevi il messaggio sulla loro acuta ambizione. "Stiamo costruendo, " ha detto Mozilla. E cosa stanno costruendo? Un "open source, dataset multilingue di voci che chiunque può utilizzare per addestrare applicazioni abilitate alla voce."
I contributori possono scegliere di fornire metadati come la loro età, sesso, e accento. I clip vocali a loro volta sono contrassegnati con informazioni utili per l'addestramento dei motori vocali.
© 2019 Science X Network