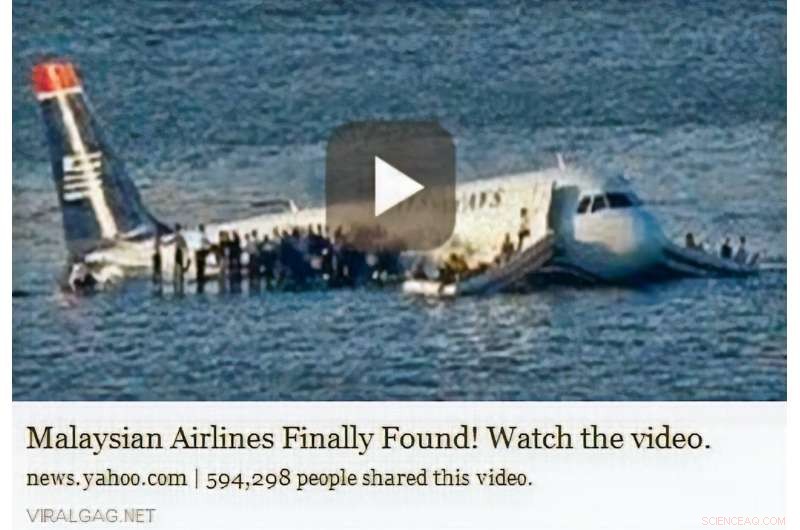
Un video del volo US Airways 1549 è stato preso in prestito dalle notizie sul volo Malaysia Airlines 370. Credito:Wen, Su &Yu.
I ricercatori della UC Davis hanno recentemente sviluppato un nuovo strumento basato sull'apprendimento automatico per verificare le voci multimediali online. La loro carta, pre-pubblicato su arXiv, propone funzionalità multilingua e multipiattaforma per la verifica delle voci, che sfruttano la somiglianza semantica tra voci e informazioni su altri siti web. Il loro metodo può combinare informazioni provenienti da più lingue per ottenere un quadro completo delle notizie online.
Un numero crescente di persone in tutto il mondo utilizza ora dispositivi per leggere le notizie e conoscere ciò che sta accadendo nel mondo. Però, le piattaforme di social media sono in gran parte non moderate, con conseguente proliferazione di fake news, che è spesso accompagnato da contenuti multimediali fabbricati o decontestualizzati. Le voci false possono diffondersi molto rapidamente online, causando scompiglio e confusione tra i lettori, quindi lo sviluppo di strumenti per verificare l'autenticità delle informazioni online è di fondamentale importanza.
"La nostra ricerca è ispirata dalla crescente popolarità delle fake news allegate da contenuti multimediali nei social network, "Weim Wen, uno dei ricercatori laureati che ha condotto lo studio, ha detto a Tech Xplore. "Si tratta principalmente di come utilizzare le tecniche di PNL per verificare le voci con contenuti multimediali. L'idea di base è risolvere il problema attraverso l'apprendimento automatico, estraendo caratteristiche specifiche da questo tipo di voci e costruendo un modello per classificare le voci come false o reali".
La precedente ricerca sulla verifica delle voci ha utilizzato contenuti multimediali come funzionalità di input, sfruttando le caratteristiche forensi di immagini o video per determinare se sono stati manomessi. Sebbene queste immagini presentino risultati migliori, la maggior parte di questi studi non ha potuto utilizzare efficacemente i contenuti multimediali per verificare in modo coerente le voci su Twitter.
Una possibile ragione di ciò è che spesso, il contenuto multimediale allegato alle fake news è semplicemente preso in prestito da eventi autentici ed è in qualche modo semanticamente allineato con il testo che lo accompagna. Ciò significa che l'immagine stessa è reale, ma è collocato in una storia completamente diversa per rendere più credibile la falsa voce.
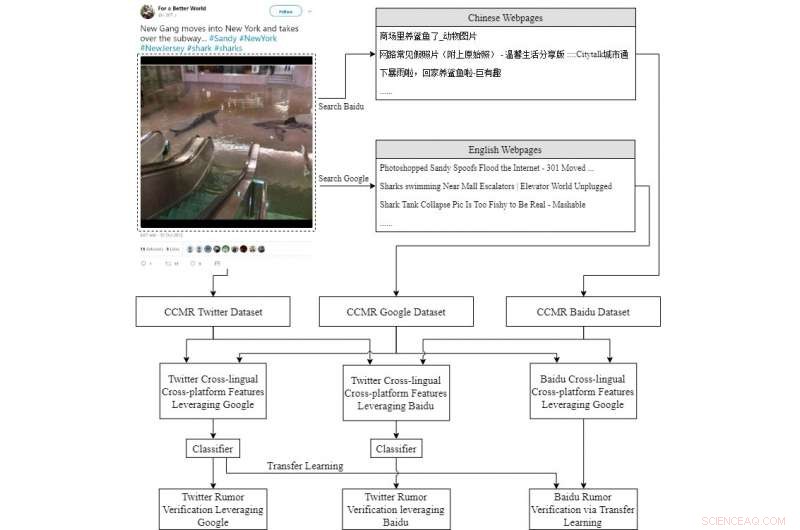
Il flusso di informazioni della nostra pipeline proposta. TFG rappresenta le funzionalità multipiattaforma multilingua per i tweet che sfruttano le informazioni di Google, mentre TFB è simile ma sfrutta invece le informazioni di Baidu. BFG significa funzionalità multipiattaforma multilingua per Baidu che sfrutta le informazioni di Google. Credito:Wen, Su &Yu.
I ricercatori della UC Davis hanno proposto un modo alternativo per verificare le voci che sfrutta i contenuti multimediali trovando informazioni ad essi associate su altre piattaforme di notizie.
La maggior parte dei set di dati di verifica delle voci esistenti sono monolingue, ad esempio, includendo solo contenuti multimediali presentati con testo in inglese o cinese. I ricercatori hanno creato un nuovo cross-lingual, set di dati di verifica delle voci multipiattaforma (CCMR), comprendente tre sottoinsiemi di dati:CCMR Twitter, CCMR Google e CCMR Baidu.
"Quando diciamo voci multimediali, intendiamo tweet o altri contenuti di social media che non sono verificati e hanno immagini o video insieme al testo, "Zhou Yu, assistente professore alla UC Davis, chi ha condotto lo studio, ha detto a Tech Xplore. "Testo e immagine sono considerati due diversi canali di informazione. Sfruttiamo le informazioni sulla visione in modo innovativo, usandolo come perno per collegare notizie da diverse piattaforme e in diverse lingue."
Le funzionalità sviluppate dai ricercatori incorporano sia la voce che i titoli associati su diverse pagine Web in vettori di 300 dimensioni con un incorporamento di frasi multilingue pre-addestrato. Hanno addestrato il loro algoritmo multilingue di incorporamento delle frasi su 453, 000 paia di notizie parallele inglesi e cinesi, così come i micro-blog nel set di dati UM-Corpus. Questo algoritmo può combinare notizie da più lingue, ottenere una verifica delle voci più efficace.
"Data una voce allegata con un'immagine, prima cerchiamo l'immagine tramite Google Image per ottenere una serie di post correlati, Wen ha spiegato. "Quindi estraiamo le caratteristiche di questa voce calcolando la somiglianza e l'accordo tra la voce e i post cercati. Finalmente, usiamo il nostro modello pre-addestrato per verificare questa voce usando le sue caratteristiche."

Esempio di voci parallele nell'evento Pig Fish. Credito:Wen, Su &Yu. Credito:Wen, Su &Yu.
Quando testato, metodi di apprendimento automatico che hanno utilizzato le funzionalità multilingua e multipiattaforma proposte dai ricercatori hanno ottenuto risultati di verifica delle voci all'avanguardia. Queste caratteristiche sono risultate anche compatte e generalizzabili tra le lingue.
"Penso che la parte più significativa del nostro studio sia che abbiamo sviluppato un framework di verifica delle voci che funziona specificamente per le voci multimediali, che è estremamente comune, ma non è stato studiato a fondo, " Wen ha detto. "Con questo quadro, possiamo verificare in modo efficiente le voci multimediali da piattaforme come Facebook e Twitter."
Questo studio potrebbe essere un'importante pietra miliare nel percorso verso lo sviluppo di modi efficaci per convalidare le voci online che sono accompagnate da contenuti multimediali. Inoltre, il set di dati inglese-cinese messo insieme dai ricercatori potrebbe essere utilizzato in ulteriori ricerche esplorando metodi per la verifica delle voci interlinguistiche.
"In futuro, abbiamo in programma di generare motivi per i nostri risultati di verifica su voci multimediali, " Wen ha detto. "Oltre a classificare una voce come falsa, vogliamo anche generare automaticamente un motivo, come "questo post è falso perché prende in prestito un'immagine da un altro evento per dimostrare la sua affermazione, '", ha detto Wen.
© 2018 Tech Xplore














