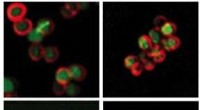
Un chip che comprende diversi dispositivi PCM. Le sonde elettriche che entrano in contatto con esso vengono utilizzate per inviare segnali ai singoli dispositivi per eseguire la moltiplicazione in memoria. Credito:IBM
Questa settimana, all'International Electron Devices Meeting (IEDM) e alla Conference on Neural Information Processing Systems (NeurIPS), I ricercatori IBM presenteranno il nuovo hardware che porterà l'IA più avanti di quanto non sia stato prima:fino al limite. I nostri nuovi approcci per i chip AI digitali e analogici aumentano la velocità e riducono la domanda di energia per il deep learning, senza rinunciare alla precisione. Dal lato digitale, stiamo preparando il terreno per un nuovo standard di settore nella formazione sull'intelligenza artificiale con un approccio che raggiunge la massima precisione con una precisione a otto bit, accelerando il tempo di formazione da due a quattro volte rispetto ai sistemi odierni. Dal lato analogico, riportiamo la precisione a otto bit, la più alta finora, per un chip analogico, circa il doppio della precisione rispetto ai precedenti chip analogici, consumando 33 volte meno energia rispetto a un'architettura digitale di precisione simile. Questi risultati annunciano una nuova era dell'hardware di elaborazione progettato per liberare tutto il potenziale dell'IA.
Nell'era post-GPU
Dal 2009, le innovazioni nel software e nell'hardware per l'intelligenza artificiale hanno in gran parte alimentato un miglioramento di 2,5 volte all'anno nelle prestazioni di elaborazione per l'intelligenza artificiale. quando le GPU sono state adottate per la prima volta per accelerare il deep learning. Ma stiamo raggiungendo i limiti di ciò che GPU e software possono fare. Per risolvere i nostri problemi più difficili, l'hardware deve essere scalato. La prossima generazione di applicazioni AI richiederà tempi di risposta più rapidi, carichi di lavoro AI più grandi, e dati multimodali da numerosi flussi. Per liberare tutto il potenziale dell'IA, stiamo riprogettando l'hardware pensando all'intelligenza artificiale:dagli acceleratori all'hardware appositamente progettato per i carichi di lavoro dell'intelligenza artificiale, come i nostri nuovi chip, e infine il calcolo quantistico per l'intelligenza artificiale. La scalabilità dell'AI con nuove soluzioni hardware fa parte di un più ampio sforzo di IBM Research per passare da una stretta AI, spesso utilizzato per risolvere specifici, compiti ben definiti, all'IA ampia, che raggiunge le diverse discipline per aiutare gli esseri umani a risolvere i nostri problemi più urgenti.
Acceleratori digitali AI con precisione ridotta
IBM Research ha lanciato l'approccio a precisione ridotta all'addestramento e all'inferenza del modello di intelligenza artificiale con un documento fondamentale che descrive un nuovo approccio al flusso di dati per le tecnologie CMOS convenzionali per potenziare le piattaforme hardware riducendo drasticamente la precisione in bit di dati e calcoli. Sono stati mostrati modelli addestrati con precisione a 16 bit, per la prima volta, per non mostrare alcuna perdita di precisione rispetto ai modelli addestrati con precisione a 32 bit. Negli anni successivi, l'approccio a precisione ridotta è stato rapidamente adottato come standard del settore, con l'addestramento a 16 bit e l'inferenza a otto bit ormai all'ordine del giorno, e ha stimolato un'esplosione di startup e capitale di rischio per chip AI digitali basati sulla precisione ridotti.
Il prossimo standard del settore per la formazione sull'intelligenza artificiale
Il prossimo importante punto di riferimento nella formazione a precisione ridotta sarà presentato al NeurIPS in un documento intitolato "Training Deep Neural Networks with otto bit Floating Point Numbers" (autori:Naigang Wang, Jungwook Choi, Daniele Marca, Chia Yu Chen, Kailash Gopalakrishnan). In questo documento, sono state proposte una serie di nuove idee per superare le sfide (e le ortodossie) precedenti associate alla riduzione della precisione dell'addestramento al di sotto dei 16 bit. Utilizzando questi nuovi approcci proposti, abbiamo dimostrato, per la prima volta, la capacità di addestrare modelli di deep learning con precisione a otto bit preservando completamente l'accuratezza del modello in tutte le principali categorie di set di dati AI:immagine, discorso, e testo. Le tecniche accelerano il tempo di addestramento per le reti neurali profonde (DNN) da due a quattro volte rispetto agli odierni sistemi a 16 bit. Sebbene in precedenza fosse considerato impossibile ridurre ulteriormente la precisione per l'allenamento, prevediamo che questa piattaforma di formazione a otto bit diventi uno standard di settore ampiamente adottato nei prossimi anni.
La riduzione della precisione dei bit è una strategia che dovrebbe contribuire a piattaforme di apprendimento automatico su larga scala più efficienti, e questi risultati segnano un significativo passo avanti nella scalabilità dell'IA. Combinando questo approccio con un'architettura del flusso di dati personalizzata, un'architettura a chip singolo può essere utilizzata per eseguire in modo efficiente l'addestramento e l'inferenza su una vasta gamma di carichi di lavoro e reti grandi e piccole. Questo approccio può ospitare anche "mini-batch" di dati, richiesto per ampie capacità di intelligenza artificiale critiche senza compromettere le prestazioni. La realizzazione di tutte queste funzionalità con una precisione a otto bit per l'addestramento apre anche il regno dell'IA ampia ed efficiente dal punto di vista energetico all'edge.
Chip analogici per l'elaborazione in memoria
Grazie ai suoi bassi requisiti di potenza, alta efficienza energetica, e alta affidabilità, la tecnologia analogica è una scelta naturale per l'IA ai margini. Gli acceleratori analogici alimenteranno una tabella di marcia dell'accelerazione hardware AI oltre i limiti degli approcci digitali convenzionali. Però, considerando che l'hardware AI digitale è in corsa per ridurre la precisione, l'analogico è stato finora limitato dalla sua precisione intrinseca relativamente bassa, impatto sulla precisione del modello. Abbiamo sviluppato una nuova tecnica per compensare questo, ottenendo la massima precisione mai vista per un chip analogico. La nostra carta allo IEDM, "Moltiplicazione in memoria di precisione a 8 bit con memoria a cambiamento di fase proiettata" (autori:Iason Giannopoulos, Abu Sebastian, Manuel Le Gallo, V.P. Jonnalagadda, M. Sousa, M.N.Boon, Evangelos Eleftheriou), mostra che questa tecnica ha raggiunto una precisione di otto bit in un'operazione di moltiplicazione scalare, raddoppiando all'incirca la precisione dei precedenti chip analogici, e consumato 33 volte meno energia rispetto a un'architettura digitale di precisione simile.
La chiave per ridurre il consumo di energia è cambiare l'architettura dell'informatica. Con l'hardware informatico di oggi, i dati devono essere spostati dalla memoria ai processori per essere utilizzati nei calcoli, che richiede molto tempo ed energia. Un'alternativa è l'elaborazione in memoria, in cui le unità di memoria illuminano la luna come processori, svolgendo efficacemente il doppio compito di archiviazione e calcolo. Ciò evita la necessità di trasferire i dati tra memoria e processore, risparmiando tempo e riducendo la domanda di energia del 90% o più.
Memoria a cambiamento di fase
Il nostro dispositivo utilizza la memoria a cambiamento di fase (PCM) per l'elaborazione in memoria. PCM registra i pesi sinaptici nel suo stato fisico lungo un gradiente tra amorfo e cristallino. La conduttanza del materiale cambia insieme al suo stato fisico e può essere modificata mediante impulsi elettrici. Ecco come PCM è in grado di eseguire calcoli. Poiché lo stato può essere ovunque lungo il continuum tra zero e uno, è considerato un valore analogico, al contrario di un valore digitale, che è uno zero o uno, niente in mezzo.
Abbiamo migliorato la precisione e la stabilità dei pesi memorizzati nel PCM con un nuovo approccio, chiamato PCM proiettato (Proj-PCM), in cui inseriamo un segmento di proiezione non isolante in parallelo al segmento a cambiamento di fase. Durante il processo di scrittura, il segmento di proiezione ha un impatto minimo sul funzionamento del dispositivo. Però, durante la lettura, i valori di conduttanza degli stati programmati sono per lo più determinati dal segmento di proiezione, che è notevolmente immune alle variazioni di conduttanza. Ciò consente ai dispositivi Proj-PCM di ottenere una precisione molto più elevata rispetto ai precedenti dispositivi PCM.
La maggiore precisione raggiunta dal nostro team di ricerca indica che l'elaborazione in memoria potrebbe essere in grado di ottenere un apprendimento profondo ad alte prestazioni in ambienti a bassa potenza, come IoT e applicazioni edge. Come con i nostri acceleratori digitali, i nostri chip analogici sono progettati per scalare per l'addestramento e l'inferenza dell'intelligenza artificiale attraverso elementi visivi, discorso, e set di dati di testo ed estendendosi all'IA ampia emergente. Dimostreremo un chip PCM precedentemente pubblicato per tutta la settimana a NeurIPS, utilizzandolo per classificare le cifre scritte a mano in tempo reale tramite il cloud.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.