Credito:IBM
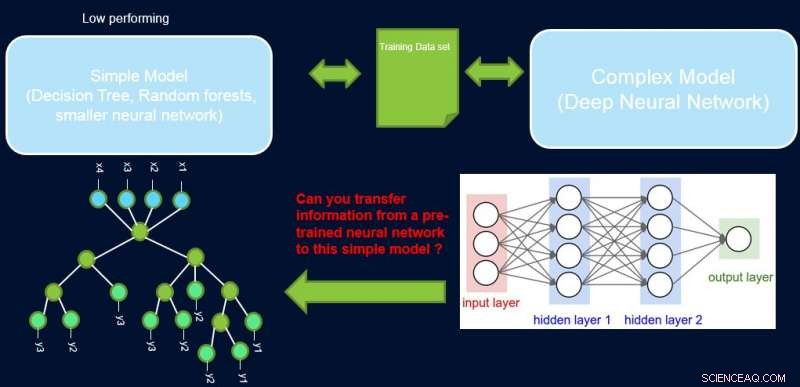
L'interpretabilità e le prestazioni di un sistema sono generalmente in contrasto tra loro, poiché molti dei modelli più performanti (vale a dire le reti neurali profonde) sono di natura scatola nera. Nel nostro lavoro, Miglioramento di modelli semplici con profili di fiducia, cerchiamo di colmare questa lacuna proponendo un metodo per trasferire informazioni da una rete neurale ad alte prestazioni a un altro modello che l'esperto di dominio o l'applicazione potrebbero richiedere. Per esempio, in biologia ed economia computazionali, sono spesso preferiti modelli lineari sparsi, mentre in domini strumentati complessi come la produzione di semiconduttori, gli ingegneri potrebbero preferire l'uso di alberi decisionali. Tali modelli interpretabili più semplici possono creare fiducia con l'esperto e fornire informazioni utili che portano alla scoperta di fatti nuovi e precedentemente sconosciuti. Il nostro obiettivo è illustrato pittoricamente di seguito, per un caso specifico in cui stiamo cercando di migliorare le prestazioni di un albero decisionale.
Il presupposto è che la nostra rete sia un insegnante ad alte prestazioni, e possiamo usare alcune delle sue informazioni per insegnare il semplice, interpretabile, ma generalmente un modello studentesco a basso rendimento. La ponderazione dei campioni in base alla loro difficoltà può aiutare il modello semplice a concentrarsi su campioni più facili che può modellare con successo durante l'allenamento, e quindi ottenere migliori prestazioni complessive. La nostra configurazione è diversa dal potenziamento:in questo approccio, esempi difficili rispetto a un precedente allievo 'debole' sono evidenziati per la formazione successiva per creare diversità. Qui, esempi difficili sono rispetto a un modello complesso accurato. Ciò significa che queste etichette sono quasi casuali. Inoltre, se un modello complesso non può risolverli, c'è poca speranza per il modello semplice di complessità fissa. Quindi, è importante nella nostra configurazione evidenziare esempi facili che il modello semplice può risolvere.
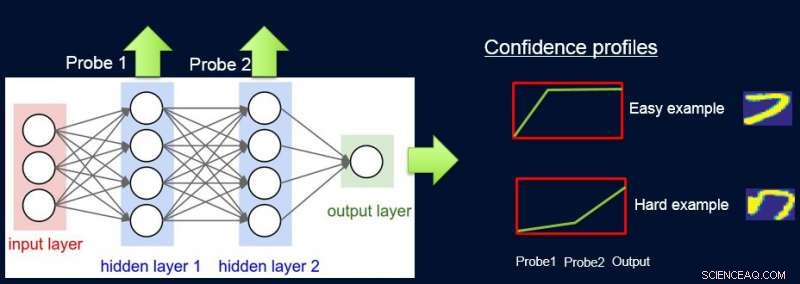
Per fare questo, assegniamo pesi ai campioni in base alla difficoltà della rete per classificarli, e lo facciamo introducendo le sonde. Ogni sonda prende il suo input da uno degli strati nascosti. Ogni sonda ha un singolo livello completamente connesso con un livello softmax della dimensione dell'uscita di rete ad esso collegata. La sonda nel livello i funge da classificatore che utilizza solo il prefisso della rete fino al livello i. Il presupposto è che le istanze facili saranno classificate correttamente con elevata confidenza anche con le sonde di primo livello, e quindi otteniamo livelli di confidenza p io da tutte le sonde per ciascuna delle istanze. Usiamo tutti p io per calcolare la difficoltà dell'istanza w io , per esempio. come l'area sotto la curva (AUC) di p io 'S.
Ora possiamo usare i pesi per riaddestrare il modello semplice sul set di dati pesato finale. Chiamiamo questa pipeline di sondaggio, ottenere pesi di fiducia, e riqualificare ProfWeight.
Credito:IBM
Presentiamo due alternative su come calcoliamo i pesi per gli esempi nel set di dati. Nell'approccio AUC sopra menzionato, notiamo l'errore di convalida/accuratezza del modello semplice quando addestrato sul set di addestramento originale. Selezioniamo sonde che hanno una precisione almeno α (> 0) maggiore del modello semplice. Ogni esempio è ponderato in base al punteggio di confidenza medio per l'etichetta true che viene calcolato utilizzando le singole previsioni soft delle sonde.
Una seconda alternativa prevede l'ottimizzazione utilizzando una rete neurale. Qui impariamo i pesi ottimali per il training set ottimizzando il seguente obiettivo:
S*=min w min ? E[λ(Swβ (x), e)], sub. a. E[w]=1
dove w sono i pesi da trovare per ogni istanza, denota lo spazio dei parametri del modello semplice S, e è la sua funzione di perdita. Dobbiamo limitare i pesi, poiché altrimenti la soluzione banale di tutti i pesi che vanno a zero sarà ottimale per l'obiettivo di cui sopra. Mostriamo nell'articolo che il nostro vincolo di E[w]=1 ha una connessione con la ricerca del campionamento di importanza ottimale.
Credito:IBM
Più in generale ProfWeight può essere utilizzato per trasferire modelli ancora più semplici ma opachi come reti neurali più piccole, che può essere utile in domini con forti limitazioni di memoria e alimentazione. Tali vincoli si verificano quando si distribuiscono modelli su dispositivi perimetrali in sistemi IoT o su dispositivi mobili o su veicoli aerei senza equipaggio.
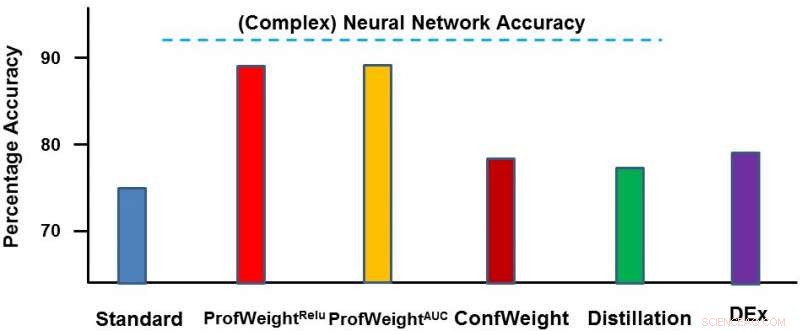
Abbiamo testato il nostro metodo su due domini:un set di dati di immagini pubbliche CIFAR-10 e un set di dati di produzione proprietario. Sul primo set di dati, i nostri modelli semplici erano reti neurali più piccole che sarebbero state conformi a rigidi vincoli di memoria e alimentazione e in cui abbiamo riscontrato un miglioramento del 3-4 percento. Sul secondo set di dati, il nostro modello semplice era un albero decisionale e l'abbiamo migliorato significativamente del 13% circa, che ha portato a risultati attuabili da parte dell'ingegnere. Di seguito rappresentiamo ProfWeight rispetto agli altri metodi su questo set di dati. Osserviamo qui che superiamo gli altri metodi con un certo margine.
In futuro vorremmo trovare le condizioni necessarie/sufficienti quando il trasferimento dalla nostra strategia porterebbe a migliorare modelli semplici. Vorremmo anche sviluppare metodi più sofisticati per il trasferimento delle informazioni rispetto a quanto abbiamo già realizzato.
Presenteremo questo lavoro in un documento intitolato "Improving Simple Models with Confidence Profiles" alla Conferenza 2018 sui sistemi di elaborazione delle informazioni neurali, di mercoledì, 5 dicembre durante la sessione poster serale dalle 17:00 alle 19:00 nelle aule 210 e 230 AB (#90).
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.