Un modello dei ricercatori del MIT e di Microsoft identifica i casi in cui le auto autonome hanno "imparato" da esempi di addestramento che non corrispondono a ciò che sta effettivamente accadendo sulla strada, che può essere utilizzato per identificare quali azioni apprese potrebbero causare errori del mondo reale. Credito:MIT News
Un nuovo modello sviluppato dai ricercatori del MIT e di Microsoft identifica i casi in cui i sistemi autonomi hanno "imparato" da esempi di addestramento che non corrispondono a ciò che sta effettivamente accadendo nel mondo reale. Gli ingegneri potrebbero utilizzare questo modello per migliorare la sicurezza dei sistemi di intelligenza artificiale, come veicoli senza conducente e robot autonomi.
I sistemi di intelligenza artificiale che alimentano le auto senza conducente, Per esempio, sono ampiamente addestrati in simulazioni virtuali per preparare il veicolo per quasi tutti gli eventi sulla strada. Ma a volte l'auto commette un errore imprevisto nel mondo reale perché si verifica un evento che dovrebbe, ma non lo fa, alterare il comportamento dell'auto.
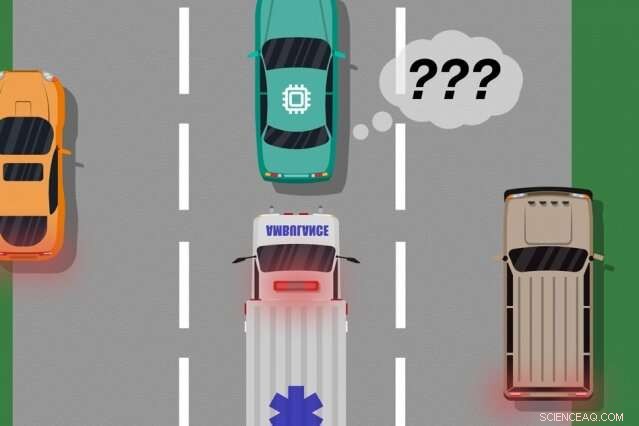
Considera un'auto senza conducente che non è stata addestrata, e soprattutto non ha i sensori necessari, distinguere tra scenari nettamente diversi, come grande, macchine bianche e ambulanze rosse, luci lampeggianti sulla strada. Se l'auto sta percorrendo l'autostrada e un'ambulanza accende le sirene, l'auto potrebbe non sapere come rallentare e accostare, perché non percepisce l'ambulanza come diversa da una grande macchina bianca.
In un paio di articoli, presentati alla conferenza Autonomous Agents and Multiagent Systems dello scorso anno e alla prossima conferenza dell'Associazione per l'avanzamento dell'intelligenza artificiale, i ricercatori descrivono un modello che utilizza l'input umano per scoprire questi "punti ciechi" di formazione.
Come con gli approcci tradizionali, i ricercatori hanno messo un sistema di intelligenza artificiale attraverso l'addestramento alla simulazione. Ma allora, un essere umano monitora da vicino le azioni del sistema mentre agisce nel mondo reale, fornire feedback quando il sistema ha effettuato, o stava per fare, eventuali errori. I ricercatori quindi combinano i dati di allenamento con i dati di feedback umani, e utilizzare tecniche di apprendimento automatico per produrre un modello che individui le situazioni in cui è molto probabile che il sistema abbia bisogno di maggiori informazioni su come agire correttamente.
I ricercatori hanno convalidato il loro metodo utilizzando videogiochi, con un umano simulato che corregge il percorso appreso di un personaggio sullo schermo. Ma il prossimo passo è incorporare il modello con i tradizionali approcci di formazione e test per auto e robot autonomi con feedback umano.
"Il modello aiuta i sistemi autonomi a conoscere meglio ciò che non sanno, " dice il primo autore Ramya Ramakrishnan, uno studente laureato nel Laboratorio di Informatica e Intelligenza Artificiale. "Molte volte, quando questi sistemi vengono implementati, le loro simulazioni addestrate non corrispondono all'impostazione del mondo reale [e] potrebbero commettere errori, come incorrere in incidenti. L'idea è di usare gli umani per colmare il divario tra la simulazione e il mondo reale, in modo sicuro, così possiamo ridurre alcuni di questi errori."
I coautori di entrambi gli articoli sono:Julie Shah, professore associato presso il Dipartimento di Aeronautica e Astronautica e responsabile del Gruppo di Robotica Interattiva del CSAIL; ed Ece Kamar, Debadeepta Dey, ed Eric Horvitz, tutto da Microsoft Research. Besmira Nushi è un coautore aggiuntivo del prossimo articolo.
Prendendo feedback
Alcuni metodi di allenamento tradizionali forniscono feedback umani durante le esecuzioni di test del mondo reale, ma solo per aggiornare le azioni del sistema. Questi approcci non identificano i punti ciechi, che potrebbe essere utile per un'esecuzione più sicura nel mondo reale.
L'approccio dei ricercatori mette prima un sistema di intelligenza artificiale attraverso l'addestramento alla simulazione, dove produrrà una "politica" che essenzialmente mappa ogni situazione alla migliore azione che può intraprendere nelle simulazioni. Quindi, il sistema sarà distribuito nel mondo reale, dove gli esseri umani forniscono segnali di errore in regioni in cui le azioni del sistema sono inaccettabili.
Gli esseri umani possono fornire dati in diversi modi, come attraverso "dimostrazioni" e "correzioni". Nelle manifestazioni, gli atti umani nel mondo reale, mentre il sistema osserva e confronta le azioni dell'essere umano con quello che avrebbe fatto in quella situazione. Per le auto senza conducente, ad esempio, un essere umano controllerà manualmente l'auto mentre il sistema produce un segnale se il suo comportamento pianificato si discosta dal comportamento dell'essere umano. Corrispondenze e discrepanze con le azioni dell'essere umano forniscono indicazioni rumorose di dove il sistema potrebbe agire in modo accettabile o inaccettabile.
In alternativa, l'umano può fornire correzioni, con l'essere umano che controlla il sistema mentre agisce nel mondo reale. Un essere umano potrebbe sedersi al posto di guida mentre l'auto autonoma si guida lungo il percorso pianificato. Se le azioni dell'auto sono corrette, l'umano non fa nulla. Se le azioni dell'auto non sono corrette, però, l'umano può prendere il volante, che invia un segnale che il sistema non ha agito in modo inaccettabile in quella specifica situazione.
Una volta compilati i dati di feedback dell'essere umano, il sistema ha essenzialmente un elenco di situazioni e, per ogni situazione, più etichette dicendo che le sue azioni erano accettabili o inaccettabili. Una singola situazione può ricevere molti segnali diversi, perché il sistema percepisce molte situazioni come identiche. Per esempio, un'auto autonoma può aver viaggiato molte volte accanto a un'auto grande senza rallentare e accostare. Ma, in un solo caso, un'ambulanza, che appare esattamente lo stesso al sistema, crociere di. L'auto autonoma non si ferma e riceve un segnale di feedback che il sistema ha intrapreso un'azione inaccettabile.
"A quel punto, al sistema sono stati dati molteplici segnali contraddittori da un essere umano:alcuni con una grande macchina accanto, e andava bene, e uno in cui c'era un'ambulanza nella stessa posizione esatta, ma non andava bene. Il sistema fa una piccola nota che ha fatto qualcosa di sbagliato, ma non sa perché, " dice Ramakrishnan. "Poiché l'agente sta ricevendo tutti questi segnali contraddittori, il passo successivo è compilare le informazioni da chiedere, 'Quanto è probabile che io commetta un errore in questa situazione in cui ho ricevuto questi segnali contrastanti?'"
Aggregazione intelligente
L'obiettivo finale è etichettare queste situazioni ambigue come punti ciechi. Ma questo va oltre il semplice conteggio delle azioni accettabili e inaccettabili per ogni situazione. Se il sistema ha eseguito azioni corrette nove volte su 10 in situazione di ambulanza, ad esempio, un voto a maggioranza semplice etichetterebbe quella situazione come sicura.
"Ma poiché le azioni inaccettabili sono molto più rare delle azioni accettabili, il sistema alla fine imparerà a prevedere tutte le situazioni come sicure, che può essere estremamente pericoloso, " dice Ramakrishnan.
A quello scopo, i ricercatori hanno utilizzato l'algoritmo di Dawid-Skene, un metodo di apprendimento automatico utilizzato comunemente per il crowdsourcing per gestire il rumore delle etichette. L'algoritmo prende come input un elenco di situazioni, ciascuno con una serie di rumorose etichette "accettabile" e "inaccettabile". Quindi aggrega tutti i dati e utilizza alcuni calcoli di probabilità per identificare i modelli nelle etichette dei punti ciechi previsti e i modelli per le situazioni sicure previste. Utilizzando tali informazioni, emette una singola etichetta aggregata "sicuro" o "punto cieco" per ogni situazione insieme al suo livello di confidenza in quell'etichetta. In particolare, l'algoritmo può apprendere in una situazione in cui può avere, ad esempio, eseguito in modo accettabile il 90 percento del tempo, la situazione è ancora abbastanza ambigua da meritare un "punto cieco".
Alla fine, l'algoritmo produce una sorta di "mappa termica, " in cui a ogni situazione dell'addestramento originale del sistema viene assegnata una probabilità da bassa ad alta di essere un punto cieco per il sistema.
"Quando il sistema viene distribuito nel mondo reale, può utilizzare questo modello appreso per agire in modo più cauto e intelligente. Se il modello appreso prevede che uno stato sia un punto cieco con alta probabilità, il sistema può interrogare un essere umano per l'azione accettabile, consentendo un'esecuzione più sicura, " dice Ramakrishnan.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.