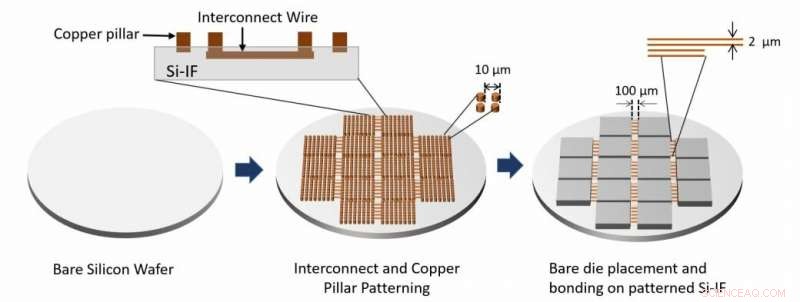
Viene mostrato il flusso del processo di assemblaggio del sistema. Gli strati di interconnessione e i pilastri di rame sono realizzati elaborando il wafer di silicio nudo. Gli stampi nudi vengono quindi incollati sul wafer utilizzando TCB. Credito:architettura di processori Waferscale - Un case study GPU, HPCA 19.
Ricercatori dell'Università dell'Illinois a Urbana-Champaign e dell'Università della California, Los Angeles, sono alla base del recente sviluppo di un computer in scala wafer che mira a essere più veloce, più efficiente dal punto di vista energetico, rispetto alle controparti contemporanee.
Gli ingegneri mirano a utilizzare qualcosa chiamato "tessuto di interconnessione di silicio" per costruire un computer con 40 GPU su un singolo wafer di silicio. TechSpot e altri siti segnalati sul loro lavoro e sulla loro carta, da presentare questo mese.
Alcuni retroscena sul Si-IF:"Negli ultimi due decenni, i chip di silicio sono diminuiti di 1000 volte, mentre i pacchetti sui circuiti stampati si sono ridotti solo di 4 volte, " ha affermato il gruppo di sviluppo tecnologico dell'UCLA. Una soluzione è "Silicio interconnect fabric (Si-IF)."
Samuel Moore a Spettro IEEE ha un articolo molto citato sull'argomento in cui ha annotato i risultati:"Le simulazioni di questo mostro multiprocessore hanno velocizzato i calcoli di quasi 19 volte e hanno tagliato la combinazione di consumo di energia e ritardo del segnale di oltre 140 volte".
Vale a dire, lo sforzo di ricerca è tra i membri del dipartimento di ingegneria elettrica e informatica, Università della California, Los Angeles, e dipartimento di ingegneria elettrica e informatica, Università dell'Illinois a Urbana-Champaign. Il loro articolo è intitolato "Architecting Waferscale Processors—A GPU Case Study".
Il professore associato di ingegneria informatica dell'llinois Rakesh Kumar ei suoi colleghi hanno già iniziato a lavorare per costruire un prototipo di sistema di processore prototipo in scala wafer. Il gruppo lo esplorerà ulteriormente per approfondimenti su eventuali problemi che potrebbero sorgere. Credevano che i tempi fossero maturi per rivisitare le architetture in scala di wafer.
Mark Tyson in Hexus :"Gli ingegneri dell'Università dell'Illinois Urbana-Champaign e dell'Università della California di Los Angeles pensano che sia giunto il momento di fare un altro tentativo di creare un computer in scala wafer".
L'accento può essere messo sulla parola rivisitare . Il team ha scritto nel loro documento, "Non sorprende, i processori in scala di wafer sono stati studiati approfonditamente negli anni '80. Ci sono stati anche diversi tentativi commerciali di costruire processori su scala wafer. Sfortunatamente, nonostante la promessa, tali processori non sono riusciti a trovare successo nel mainstream a causa di problemi di rendimento."
Hanno detto "maggiore è la dimensione del processore, più bassa era la resa:la resa a scala di wafer a quei tempi era debilitante. Sosteniamo che da allora sono stati compiuti notevoli progressi nella tecnologia di produzione e confezionamento e che potrebbe essere il momento di rivedere la fattibilità dei processori in scala di wafer".
Il professore associato di ingegneria informatica dell'Illinois Rakesh Kumar e i suoi collaboratori sono pronti a sostenere il caso di un computer in scala wafer composto da ben 40 GPU. Il miglior titolo per ricordarci perché questo è interessante può essere trovato su Spettro IEEE . "Cosa c'è di meglio di 40 server basati su GPU? Un server con 40 GPU."
Cosa c'è di speciale:hanno chip GPU standard che hanno superato i test di qualità:stanno creando una tecnologia che chiamano silicio interconnect fabric (SiIF) per connetterli meglio.
Shawn Knight in TechSpot ha scritto su questo. "Con un'integrazione così stretta, " disse Cavaliere, "dal punto di vista del programmatore, sembrerebbe una GPU gigante invece di 40 GPU singole."
SiIF sostituisce il circuito stampato con il silicio; non c'è bisogno di un pacchetto di chip, disse Moore. Ha riferito che in un progetto sono stati in grado di spremere 41 GPU. "Hanno testato una simulazione di questo progetto e hanno scoperto che accelera sia il calcolo che il movimento dei dati, consumando meno energia rispetto a 40 server GPU standard".
Tyson ha scritto che "come molti lettori di HEXUS sapranno, di solito i supercomputer diffondono applicazioni su centinaia di GPU su PCB separati, comunicare su collegamenti a lungo raggio. Tali collegamenti sono lenti e inefficienti dal punto di vista energetico rispetto alle interconnessioni all'interno dell'architettura del chip." Ha osservato che Kumar ha parlato di ottenere dati da una GPU all'altra creando un'incredibile quantità di sovraccarico.
Spettro IEEE Moore ha spiegato il loro lavoro in modo più dettagliato.
"Il wafer SiIF è modellato con uno o più strati di interconnessioni in rame larghe 2 micrometri distanziate di appena 4 micrometri. È paragonabile al livello superiore delle interconnessioni su un chip. Nei punti in cui le GPU devono essere collegate , il wafer di silicio è modellato con brevi pilastri di rame distanziati di circa 5 micrometri l'uno dall'altro. La GPU è allineata sopra questi, premuto, e riscaldato. Questo processo consolidato, chiamato legame a compressione termica, fa sì che i pilastri di rame si fondino con le interconnessioni in rame della GPU. "
Il loro lavoro ha suscitato commenti favorevoli. Tyson l'ha definita una mossa coraggiosa ma forse tempestiva per l'industria.
Qual è il prossimo? Il team presenterà i propri risultati all'IEEE International Symposium on High-Performance Computer Architecture. L'evento è dal 16 al 20 febbraio a Washington DC.
© 2019 Scienza X Rete