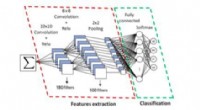
I ricercatori del MIT hanno sviluppato un algoritmo efficiente che potrebbe fornire una soluzione "a pulsante" per la progettazione automatica di reti neurali ad esecuzione rapida su hardware specifico. Credito:Chelsea Turner, MIT
Una nuova area dell'intelligenza artificiale prevede l'utilizzo di algoritmi per progettare automaticamente sistemi di apprendimento automatico noti come reti neurali, che sono più precisi ed efficienti di quelli sviluppati da ingegneri umani. Ma questa cosiddetta tecnica di ricerca dell'architettura neurale (NAS) è computazionalmente costosa.
Uno degli algoritmi NAS all'avanguardia recentemente sviluppato da Google ha impiegato 48, 000 ore di lavoro da parte di una squadra di unità di elaborazione grafica (GPU) per produrre una singola rete neurale convoluzionale, utilizzato per la classificazione delle immagini e le attività di identificazione. Google ha i mezzi per eseguire centinaia di GPU e altri circuiti specializzati in parallelo, ma questo è fuori portata per molti altri.
In un documento presentato alla Conferenza internazionale sulle rappresentazioni dell'apprendimento a maggio, I ricercatori del MIT descrivono un algoritmo NAS in grado di apprendere direttamente reti neurali convoluzionali (CNN) specializzate per piattaforme hardware di destinazione, quando eseguito su un enorme set di dati di immagini, in sole 200 ore GPU, che potrebbe consentire un uso molto più ampio di questi tipi di algoritmi.
I ricercatori e le aziende a corto di risorse potrebbero trarre vantaggio dall'algoritmo che consente di risparmiare tempo e denaro, dicono i ricercatori. L'obiettivo generale è "democratizzare l'IA, " dice il coautore Song Han, un assistente professore di ingegneria elettrica e informatica e ricercatore nei Microsystems Technology Laboratories del MIT. "Vogliamo consentire sia agli esperti di intelligenza artificiale che ai non esperti di progettare in modo efficiente architetture di rete neurale con una soluzione a pulsante che funziona velocemente su un hardware specifico".
Han aggiunge che tali algoritmi NAS non sostituiranno mai gli ingegneri umani. "L'obiettivo è scaricare il lavoro ripetitivo e noioso che deriva dalla progettazione e dal perfezionamento delle architetture di rete neurale, "dice Han, che è affiancato sulla carta da due ricercatori del suo gruppo, Han Cai e Ligeng Zhu.
Binizzazione e potatura "a livello di percorso"
Nel loro lavoro, i ricercatori hanno sviluppato modi per eliminare i componenti di progettazione della rete neurale non necessari, per ridurre i tempi di elaborazione e utilizzare solo una frazione della memoria hardware per eseguire un algoritmo NAS. Un'ulteriore innovazione garantisce che ogni CNN emessa funzioni in modo più efficiente su piattaforme hardware specifiche:CPU, GPU, e dispositivi mobili, rispetto a quelli progettati con approcci tradizionali. Nei test, le CNN dei ricercatori sono state misurate 1,8 volte più velocemente su un telefono cellulare rispetto ai tradizionali modelli gold standard con una precisione simile.
L'architettura di una CNN è costituita da strati di calcolo con parametri regolabili, chiamati "filtri, " e le possibili connessioni tra questi filtri. I filtri elaborano i pixel dell'immagine in griglie di quadrati, ad esempio 3x3, 5x5, o 7x7, con ogni filtro che copre un quadrato. I filtri essenzialmente si muovono attraverso l'immagine e combinano tutti i colori della loro griglia di pixel coperta in un singolo pixel. Strati diversi possono avere filtri di dimensioni diverse, e connettersi per condividere i dati in modi diversi. L'output è un'immagine condensata, dalle informazioni combinate di tutti i filtri, che può essere analizzata più facilmente da un computer.
Poiché il numero di possibili architetture tra cui scegliere, chiamato "spazio di ricerca", è così ampio, l'applicazione del NAS per creare una rete neurale su enormi set di dati di immagini è computazionalmente proibitivo. Gli ingegneri in genere eseguono NAS su set di dati proxy più piccoli e trasferiscono le loro architetture CNN apprese all'attività di destinazione. Questo metodo di generalizzazione riduce l'accuratezza del modello, però. Inoltre, la stessa architettura in uscita viene applicata anche a tutte le piattaforme hardware, che porta a problemi di efficienza.
I ricercatori hanno addestrato e testato il loro nuovo algoritmo NAS su un'attività di classificazione delle immagini nel set di dati ImageNet, che contiene milioni di immagini in mille classi. Per prima cosa hanno creato uno spazio di ricerca che contiene tutti i possibili "percorsi" CNN candidati, ovvero come i livelli e i filtri si connettono per elaborare i dati. Questo dà all'algoritmo del NAS campo libero per trovare un'architettura ottimale.
Ciò significherebbe in genere che tutti i possibili percorsi devono essere archiviati in memoria, che supererebbe i limiti di memoria della GPU. Per affrontare questo, i ricercatori sfruttano una tecnica chiamata "binizzazione a livello di percorso, " che memorizza solo un percorso campionato alla volta e consente di risparmiare un ordine di grandezza nel consumo di memoria. Combinano questa binarizzazione con "eliminazione a livello di percorso, " una tecnica che tradizionalmente apprende quali "neuroni" in una rete neurale possono essere eliminati senza influire sull'output. Invece di scartare i neuroni, però, l'algoritmo NAS dei ricercatori elimina interi percorsi, che cambia completamente l'architettura della rete neurale.
In allenamento, a tutti i percorsi viene inizialmente data la stessa probabilità di selezione. L'algoritmo quindi traccia i percorsi, memorizzandone solo uno alla volta, per annotare l'accuratezza e la perdita (una penalità numerica assegnata per previsioni errate) dei loro output. Quindi regola le probabilità dei percorsi per ottimizzare sia la precisione che l'efficienza. Alla fine, l'algoritmo elimina tutti i percorsi a bassa probabilità e mantiene solo il percorso con la probabilità più alta, che è l'architettura CNN finale.
Consapevole dell'hardware
Un'altra innovazione chiave è stata rendere l'algoritmo NAS "consapevole dell'hardware, "Han dice, il che significa che utilizza la latenza su ciascuna piattaforma hardware come segnale di feedback per ottimizzare l'architettura. Per misurare questa latenza sui dispositivi mobili, ad esempio, grandi aziende come Google impiegheranno una "fattoria" di dispositivi mobili, che è molto costoso. I ricercatori hanno invece costruito un modello che prevede la latenza utilizzando un solo telefono cellulare.
Per ogni strato scelto della rete, l'algoritmo campiona l'architettura su quel modello di previsione della latenza. Quindi utilizza tali informazioni per progettare un'architettura che funzioni il più rapidamente possibile, pur ottenendo un'elevata precisione. Negli esperimenti, la CNN dei ricercatori ha funzionato quasi il doppio della velocità di un modello gold standard sui dispositivi mobili.
Un risultato interessante, Han dice, era che il loro algoritmo NAS ha progettato architetture CNN che sono state a lungo respinte come troppo inefficienti, ma, nei test dei ricercatori, erano effettivamente ottimizzati per determinati hardware. Ad esempio, gli ingegneri hanno sostanzialmente smesso di usare filtri 7x7, perché sono computazionalmente più costosi di multipli, filtri più piccoli. Ancora, l'algoritmo NAS dei ricercatori ha scoperto che le architetture con alcuni strati di filtri 7x7 funzionavano in modo ottimale sulle GPU. Questo perché le GPU hanno un'elevata parallelizzazione, il che significa che calcolano molti calcoli contemporaneamente, quindi possono elaborare un singolo filtro di grandi dimensioni contemporaneamente in modo più efficiente rispetto all'elaborazione di più filtri piccoli uno alla volta.
"Questo va contro il precedente pensiero umano, " dice Han. "Più grande è lo spazio di ricerca, le cose più sconosciute che riesci a trovare. Non sai se qualcosa sarà migliore della passata esperienza umana. Lascia che sia l'IA a capirlo."