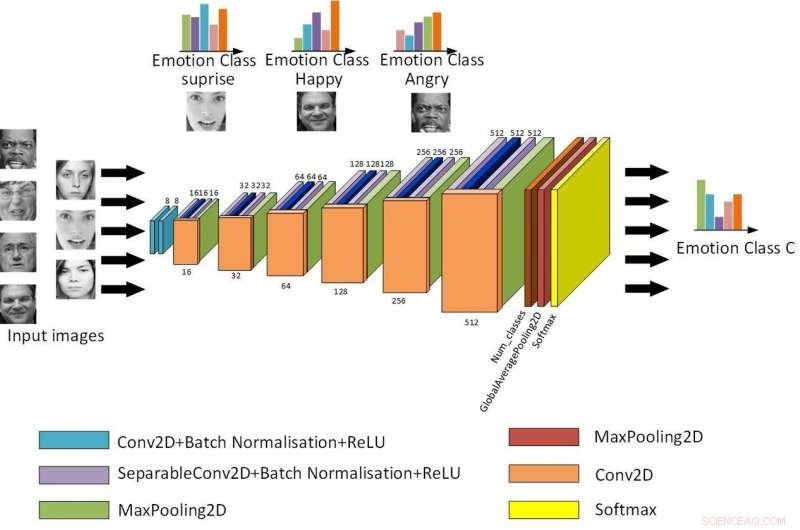
La struttura di base della Light-CNN. Credito:Jie &Yongsheng.
Due ricercatori della Shanghai University of Electric Power hanno recentemente sviluppato e valutato nuovi modelli di rete neurale per il riconoscimento delle espressioni facciali (FER) in natura. Il loro studio, pubblicato sulla rivista Neurocomputing di Elsevier, presenta tre modelli di reti neurali convoluzionali (CNN):una Light-CNN, una CNN a doppio ramo e una CNN pre-addestrata.
"A causa della mancanza di informazioni sui volti non frontali, FER in natura è un punto difficile nella visione artificiale, "Qian Yongsheng, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "I metodi esistenti di riconoscimento delle espressioni facciali naturali basati su reti neurali convoluzionali profonde (CNN) presentano diversi problemi, compreso il montaggio eccessivo, elevata complessità computazionale, singola caratteristica e campioni limitati."
Sebbene molti ricercatori abbiano sviluppato approcci della CNN per FER, finora, pochissimi di loro hanno cercato di determinare quale tipo di rete è più adatto a questo particolare compito. Consapevole di questa lacuna in letteratura, Yongsheng e il suo collega Shao Jie hanno sviluppato tre diverse CNN per FER e hanno effettuato una serie di valutazioni per identificare i loro punti di forza e di debolezza.
"Il nostro primo modello è una CNN leggera poco profonda che introduce un modulo separabile in profondità con il modulo di rete residuo, riducendo i parametri di rete modificando il metodo di convoluzione, " Yongsheng ha detto. "Il secondo è una CNN a doppio ramo, che combina caratteristiche globali e caratteristiche di texture locali, cercando di ottenere caratteristiche più ricche e compensare la mancanza di invarianza di rotazione di convoluzione. La terza CNN pre-addestrata utilizza pesi addestrati nello stesso grande database distribuito per riaddestrarsi sul proprio piccolo database, riducendo i tempi di formazione e migliorando il tasso di riconoscimento."
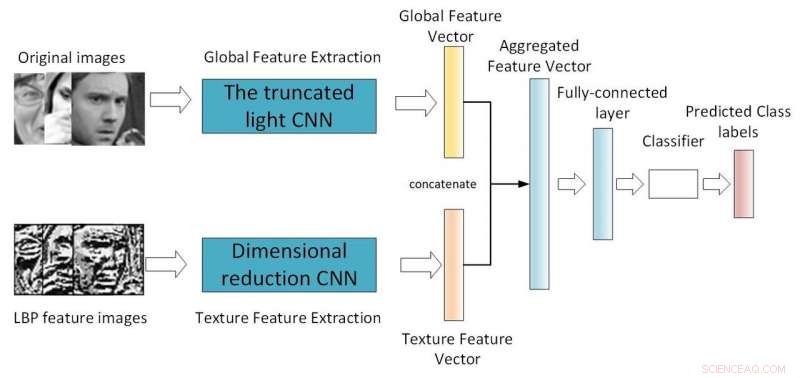
Quadro della CNN a doppio ramo. Credito:Jie &Yongsheng.
I ricercatori hanno effettuato valutazioni approfondite dei loro modelli CNN su tre set di dati comunemente usati per FER:il CK+ pubblico, set di dati multivista BU-3DEF e FER2013. Sebbene i tre modelli della CNN presentassero differenze nelle prestazioni, tutti hanno ottenuto risultati promettenti, superando diversi approcci all'avanguardia per FER.
"Attualmente, i tre modelli CNN vengono utilizzati separatamente, " Yongsheng ha spiegato. "La rete superficiale è più adatta per l'hardware integrato. La CNN pre-addestrata può ottenere risultati migliori, ma richiede pesi pre-addestrati. La rete a due filiali non è molto efficace. Certo, si potrebbe anche provare a usare i tre modelli insieme."
Nelle loro valutazioni, i ricercatori hanno osservato che combinando il modulo di rete residua e il modulo separabile in profondità, come hanno fatto per il loro primo modello della CNN, i parametri di rete potrebbero essere ridotti. Questo potrebbe alla fine risolvere alcune delle carenze dell'hardware informatico. Inoltre, hanno scoperto che il modello CNN pre-addestrato ha trasferito un grande database al proprio database e potrebbe quindi essere addestrato con campioni limitati.
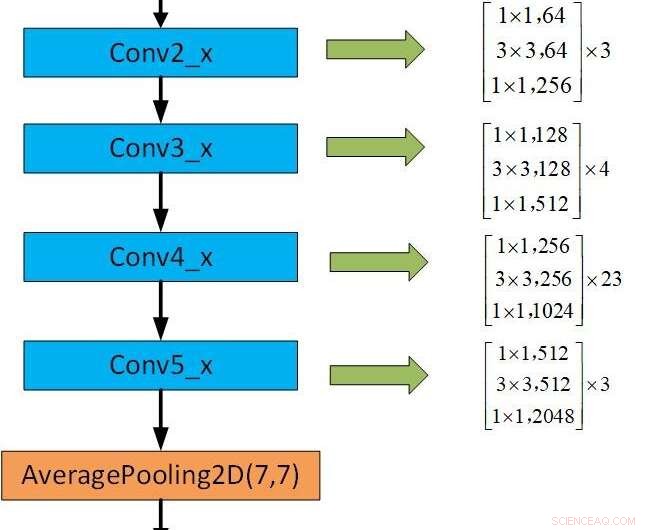
Il quadro della CNN preaddestrata. Credito:Jie &Yongsheng.
Le tre CNN per FER proposte da Yongsheng e Jie potrebbero avere numerose applicazioni, ad esempio, aiutando lo sviluppo di robot in grado di identificare le espressioni facciali degli umani con cui interagiscono. I ricercatori stanno ora pianificando di apportare ulteriori modifiche ai loro modelli, al fine di migliorare ulteriormente le loro prestazioni.
"Nel nostro lavoro futuro, proveremo ad aggiungere diverse funzionalità manuali tradizionali per unire la CNN a doppio ramo e cambiare la modalità di fusione, " ha detto Yongsheng. "Utilizzeremo anche parametri di rete di formazione cross-database per ottenere migliori capacità di generalizzazione e adottare un approccio di deep transfer learning più efficace".
© 2019 Scienza X Rete