Un algoritmo sta semplicemente seguendo regole progettate direttamente o indirettamente da un essere umano. Credito:Shutterstock/miliardi di foto
Il ruolo degli algoritmi nelle nostre vite sta crescendo rapidamente, dal semplice suggerimento di risultati di ricerca online o contenuti nel nostro feed di social media, a questioni più critiche come aiutare i medici a determinare il nostro rischio di cancro.
Ma come facciamo a sapere che possiamo fidarci della decisione di un algoritmo? Nel mese di giugno, quasi 100 conducenti negli Stati Uniti hanno imparato a proprie spese che a volte gli algoritmi possono sbagliare di grosso.
Google Maps li ha bloccati tutti su una strada privata fangosa in una deviazione fallita per sfuggire a un ingorgo diretto all'aeroporto internazionale di Denver, in Colorado.
Poiché la nostra società diventa sempre più dipendente da algoritmi per la consulenza e il processo decisionale, sta diventando urgente affrontare la spinosa questione di come possiamo fidarci di loro.
Gli algoritmi sono regolarmente accusati di pregiudizio e discriminazione. Hanno attirato la preoccupazione dei politici statunitensi, tra le affermazioni abbiamo uomini bianchi che sviluppano algoritmi di riconoscimento facciale addestrati a funzionare bene solo per gli uomini bianchi.
Ma gli algoritmi non sono altro che programmi per computer che prendono decisioni basate su regole:o regole che abbiamo dato loro, o regole che hanno capito da soli sulla base degli esempi che abbiamo fornito loro.
In entrambi i casi, gli esseri umani hanno il controllo di questi algoritmi e di come si comportano. Se un algoritmo è difettoso, è opera nostra.
Quindi, prima che finiamo tutti in un metaforico (o letterale!) ingorgo fangoso, c'è un urgente bisogno di rivisitare il modo in cui noi umani scegliamo di mettere alla prova quelle regole e guadagnare fiducia negli algoritmi.
Algoritmi messi alla prova, tipo
Gli umani sono creature naturalmente sospettose, ma la maggior parte di noi può essere convinta dalle prove.
Dati un numero sufficiente di esempi di test, con risposte corrette note, sviluppiamo fiducia se un algoritmo fornisce costantemente la risposta corretta, e non solo per facili esempi ovvi, ma anche per quelli impegnativi, esempi realistici e diversificati. Quindi possiamo essere convinti che l'algoritmo sia imparziale e affidabile.
Sembra abbastanza facile, Giusto? Ma è così che vengono solitamente testati gli algoritmi? È più difficile di quanto sembri assicurarsi che gli esempi di test siano imparziali e rappresentativi di tutti i possibili scenari che potrebbero verificarsi.
Più comunemente, vengono utilizzati esempi di benchmark ben studiati perché facilmente reperibili dai siti web. (Microsoft aveva un database di volti di celebrità per testare gli algoritmi di riconoscimento facciale, ma è stato recentemente eliminato a causa di problemi di privacy.)
Il confronto degli algoritmi è anche più semplice se testato su benchmark condivisi, ma questi esempi di test sono raramente esaminati per i loro pregiudizi. Persino peggio, le prestazioni degli algoritmi sono generalmente riportate in media negli esempi di test.
Sfortunatamente, sapere che un algoritmo funziona bene in media non ci dice nulla sul fatto che possiamo fidarci di esso in casi specifici.
Non sorprende leggere che i medici sono scettici sull'algoritmo di Google per la diagnosi del cancro, che offre in media l'89% di precisione. Come fa un medico a sapere se il suo paziente è uno degli sfortunati 11% con una diagnosi errata?
Con la crescente domanda di medicina personalizzata su misura per l'individuo (non solo Mr/Ms Average), e con medie note per nascondere ogni sorta di peccati, i risultati medi non conquisteranno la fiducia umana.
La necessità di nuovi protocolli di test
Chiaramente non è abbastanza rigoroso per testare una serie di esempi, benchmark ben studiati o meno, senza dimostrare che sono imparziali, e quindi trarre conclusioni sull'affidabilità di un algoritmo in media.
Eppure, paradossalmente, questo è l'approccio da cui dipendono i laboratori di ricerca di tutto il mondo per mostrare i loro muscoli algoritmici. Il processo di peer review accademico rafforza queste procedure di test ereditate e raramente messe in discussione.
Un nuovo algoritmo è pubblicabile se è in media migliore degli algoritmi esistenti su esempi di benchmark ben studiati. Se non è competitivo in questo modo, o è nascosto da ulteriori controlli di revisione paritaria, o vengono presentati nuovi esempi per i quali l'algoritmo sembra utile.
In questo modo, un caldo, luce lusinghiera brilla su ogni algoritmo appena pubblicato, con pochi tentativi di stressare i suoi punti di forza e di debolezza, e presentalo verruche e tutto. È la versione informatica dei ricercatori medici che non pubblicano i risultati completi degli studi clinici.
Man mano che la fiducia algoritmica diventa più cruciale, abbiamo urgente bisogno di aggiornare questa metodologia per verificare se gli esempi di test scelti sono adatti allo scopo. Finora, i ricercatori sono stati trattenuti da un'analisi più rigorosa dalla mancanza di strumenti adeguati.
Abbiamo creato uno stress test migliore
Dopo oltre un decennio di ricerche, il mio team ha lanciato un nuovo strumento di analisi degli algoritmi online chiamato MATILDA:Melbourne Algorithm Test Instance Library con Data Analytics.
Aiuta gli algoritmi di stress test in modo più rigoroso creando potenti visualizzazioni di un problema, mostrando tutti gli scenari o gli esempi che un algoritmo dovrebbe prendere in considerazione per un test completo.
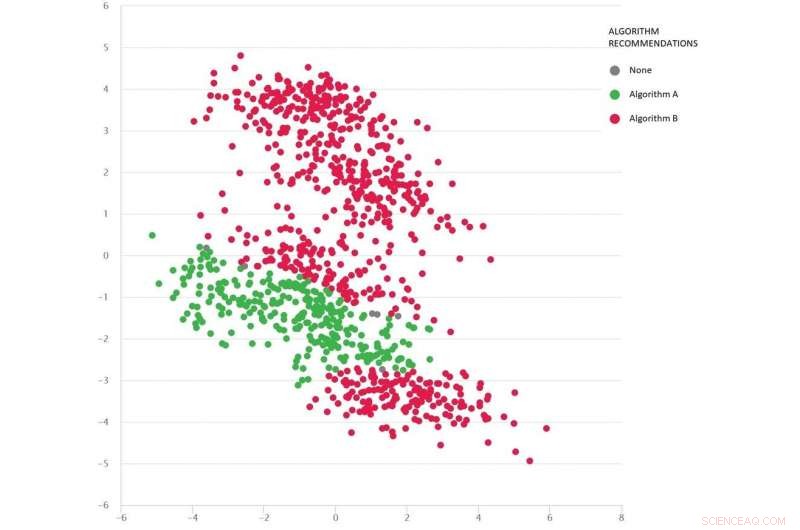
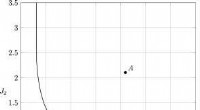
Un problema di tipo Google Maps con diversi scenari di test come punti:l'algoritmo B (rosso) è il migliore in media, ma l'algoritmo A (verde) è migliore in molti casi. Attestazione:MATILDA, Autore fornito
MATILDA identifica i punti di forza e di debolezza unici di ogni algoritmo, raccomandando quale degli algoritmi disponibili utilizzare in scenari diversi e perché.
Per esempio, se la pioggia recente ha trasformato strade sterrate in fango, alcuni algoritmi del "percorso più breve" potrebbero essere inaffidabili a meno che non siano in grado di anticipare il probabile impatto del tempo sui tempi di viaggio quando consigliano il percorso più veloce. A meno che gli sviluppatori non mettano alla prova tali scenari, non sapranno mai di tali punti deboli finché non sarà troppo tardi e non saremo bloccati nel fango.
MATILDA ci aiuta a vedere la diversità e la completezza dei benchmark, e dove dovrebbero essere progettati nuovi esempi di test per riempire ogni angolo del possibile spazio in cui si potrebbe chiedere all'algoritmo di operare.
L'immagine seguente mostra una serie diversificata di scenari (punti) per un tipo di problema di Google Maps. Ogni scenario varia le condizioni, come le posizioni di origine e di destinazione, la rete stradale disponibile, condizioni meteo, tempi di viaggio su varie strade e tutte queste informazioni vengono acquisite matematicamente e riassunte dalle coordinate bidimensionali di ogni scenario nello spazio.
Vengono confrontati due algoritmi (rosso e verde) per vedere quale può trovare il percorso più breve. Ogni algoritmo si è dimostrato il migliore (o si è dimostrato inaffidabile) in diverse regioni a seconda di come si comporta in questi scenari testati.
Possiamo anche indovinare quale algoritmo è probabilmente il migliore per gli scenari mancanti (gap) che non abbiamo ancora testato.
La matematica dietro MATILDA aiuta a creare questa visualizzazione, analizzando i dati di affidabilità degli algoritmi da scenari di test, e trovare un modo per vedere facilmente i modelli.
Gli approfondimenti e le spiegazioni ci consentono di scegliere l'algoritmo migliore per il problema in questione, piuttosto che incrociare le dita e sperare di poterci fidare dell'algoritmo che funziona meglio in media.
Sottoponendo rigorosamente gli algoritmi allo stress test in questo modo - verruche e tutto il resto - dovremmo ridurre il rischio di decisioni di algoritmi canaglia, assicurandosi la fiducia di Mr/Ms Average, e forse anche gli umani più scettici.
Questo articolo è stato ripubblicato da The Conversation con una licenza Creative Commons. Leggi l'articolo originale.