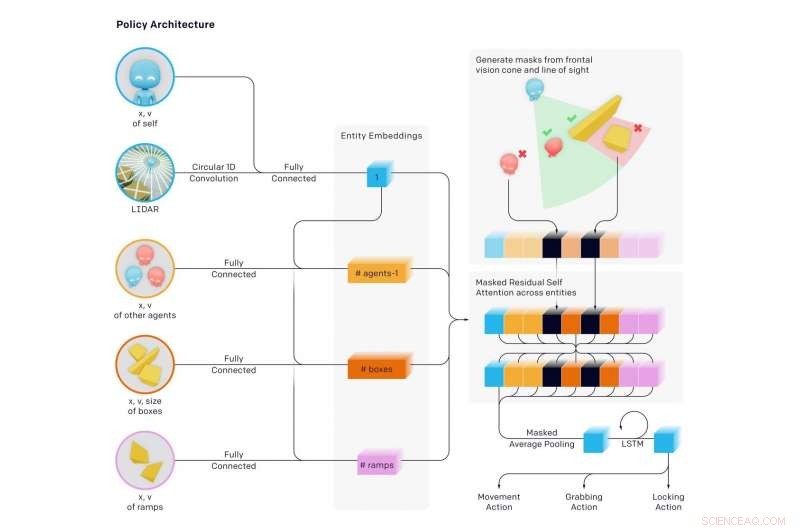
Attestazione:openai
I ricercatori hanno fatto notizia lasciando che le loro ambizioni di intelligenza artificiale giocassero un formidabile gioco a nascondino con risultati formidabili. L'ambiente degli agenti aveva pareti e scatole mobili per una sfida dove alcuni erano i nascondigli e altri, cercatori. Molte cose sono successe lungo la strada, con sorprese.
Affermando quanto appreso, gli autori hanno scritto sul blog:"Abbiamo osservato agenti che hanno scoperto un uso di strumenti progressivamente più complesso mentre giocavano a un semplice gioco di nascondino, " dove gli agenti hanno costruito "una serie di sei strategie e controstrategie distinte, alcuni dei quali non sapevamo che il nostro ambiente fosse supportato."
In un nuovo documento pubblicato all'inizio di questa settimana, la squadra ha rivelato i risultati. La loro carta, "Utilizzo di strumenti emergenti da autocurricula multi-agente, " aveva sette autori, sei dei quali avevano una rappresentanza OpenAI elencata, e uno, Google cervello.
Gli autori hanno commentato che tipo di sfida stavano affrontando. "La creazione di agenti artificiali intelligenti in grado di risolvere un'ampia varietà di compiti complessi relativi all'uomo è stata una sfida di lunga data nella comunità dell'intelligenza artificiale".
Il team ha affermato che "troviamo che gli agenti creano un autocurriculum autocontrollato che induce più cicli distinti di strategia emergente, molti dei quali richiedono l'uso e il coordinamento di strumenti sofisticati."
Attraverso il nascondino, (1) I cercatori hanno imparato a inseguire chi si nasconde e chi nasconde ha imparato a scappare (2) I cacciatori hanno imparato l'uso di strumenti di base:scatole e muri per costruire forti. (3) I cercatori hanno imparato a usare le rampe per saltare nel rifugio dei cacciatori (4) I cercatori hanno imparato a spostare le rampe lontano da dove costruiranno il loro forte, e bloccarli in posizione (5) I cercatori hanno imparato che possono saltare dalle rampe chiuse alle scatole e navigare nella scatola fino al rifugio dei nascondigli e (6) I cacciatori hanno imparato a chiudere le scatole inutilizzate prima di costruire il loro forte.
Queste sei strategie sono emerse quando gli agenti si sono addestrati l'uno contro l'altro a nascondino:ogni nuova strategia ha creato una pressione precedentemente inesistente per gli agenti per passare alla fase successiva, senza alcun incentivo diretto per gli agenti a interagire con gli oggetti o ad esplorare. Le strategie erano il risultato dell'"autocurriculum" indotto dalla competizione multi-agente e dalle dinamiche del nascondino.
Gli autori del blog hanno affermato di aver appreso "molto spesso gli agenti trovano un modo per sfruttare l'ambiente che costruisci o il motore fisico in un modo non intenzionale".
Quello che stava accadendo era una "complessità emergente auto-controllata". E questo "suggerisce inoltre che il co-adattamento multi-agente potrebbe un giorno produrre un comportamento estremamente complesso e intelligente". Allo stesso modo, gli autori hanno affermato nel loro articolo che "indurre l'autocurricula in ambienti fisicamente radicati e aperti potrebbe alla fine consentire agli agenti di acquisire un numero illimitato di abilità rilevanti per l'uomo".
Douglas Paradiso, Nuovo scienziato , ha davvero suscitato l'interesse dei lettori per il modo in cui ha descritto l'accaduto:
"All'inizio, i cacciatori sono semplicemente scappati. Ma, presto capirono che il modo più rapido per mettere in difficoltà i cercatori era trovare oggetti nell'ambiente per nascondersi alla vista, usandoli come una sorta di strumento. Per esempio, impararono che le scatole potevano essere usate per bloccare le porte e costruire semplici nascondigli. I cercatori hanno appreso che potevano spostare una rampa e usarla per scavalcare i muri. I bot hanno poi scoperto che essere un giocatore di squadra, passandosi oggetti l'un l'altro o collaborando a un nascondiglio, era il modo più rapido per vincere".
Questo era un progetto ambizioso. Esaminando il loro lavoro, Revisione della tecnologia del MIT ha notato che l'IA ha imparato a usare gli strumenti dopo quasi 500 milioni di partite a nascondino. Giocando a nascondino centinaia di milioni di round, due squadre opposte di agenti di intelligenza artificiale hanno sviluppato complesse strategie di nascondersi e cercare.
Karen Hao ha presentato un interessante indicatore di ciò che gli agenti hanno appreso dopo quanti round:"...intorno ai 25 milioni di partite, il gioco è diventato più sofisticato. I cacciatori hanno imparato a spostare e bloccare le scatole e le barricate nell'ambiente per costruire forti intorno a sé in modo che i cercatori non li vedessero mai."
Più milioni di round:i ricercatori hanno scoperto una contro-strategia, mentre imparavano a spostare una rampa vicino al forte dei nascondigli e ad usarla per scavalcare le mura. Più giri dopo, i cacciatori impararono a bloccare le rampe in posizione prima di costruire il loro forte.
Ancora più strategie sono emerse alla soglia dei 380 milioni di partite. sono emerse altre due strategie. I cercatori hanno sviluppato una strategia per irrompere nel forte dei nascondigli usando una rampa chiusa per salire su una scatola aperta, quindi "navigare" in cima alla scatola fino al forte e oltre le sue mura. Nella fase finale, i cacciatori impararono ancora una volta a bloccare tutte le rampe e le scatole prima di costruire il loro forte.
Hao ha citato Bowen Baker, uno degli autori del saggio. "Non abbiamo detto agli nascondigli o ai cercatori di correre vicino a una scatola o di interagire con essa... Ma attraverso la competizione multiagente, hanno creato nuovi compiti l'uno per l'altro in modo tale che l'altra squadra ha dovuto adattarsi."
Pensaci. Baker ha detto che non l'hanno detto ai nascondigli, e non dissero ai cercatori, correre vicino alle scatole né interagire con esse.
Devin Coldewey in TechCrunch Ci ho pensato. "Lo studio intendeva, e ha esaminato con successo la possibilità per gli agenti di apprendimento automatico di apprendere in modo sofisticato, tecniche rilevanti per il mondo reale senza alcuna interferenza dei suggerimenti dei ricercatori".
Coldewey ha azzeccato tutto questo lavoro. "Come spiegano gli autori del documento, questo è un po' il modo in cui siamo nati".
Noi, come negli esseri umani. Coldewey ha citato un passaggio dal loro articolo.
"La grande quantità di complessità e diversità sulla Terra si è evoluta a causa della coevoluzione e della competizione tra organismi, diretto dalla selezione naturale. Quando emerge una nuova strategia o mutazione di successo, cambia la distribuzione implicita dei compiti che gli agenti vicini devono risolvere e crea una nuova pressione per l'adattamento. Queste corse agli armamenti evolutive creano autocurricula impliciti in cui agenti in competizione creano continuamente nuovi compiti l'uno per l'altro".
© 2019 Scienza X Rete