Credito:Bıyık et al.
Negli ultimi anni, i ricercatori hanno cercato di sviluppare metodi che consentano ai robot di apprendere nuove abilità. Un'opzione è che un robot impari queste nuove abilità dagli umani, fare domande ogni volta che non è sicuro di come comportarsi, e imparare dalle risposte dell'utente umano.
Un team di ricerca della Stanford University ha recentemente sviluppato un approccio intuitivo all'apprendimento attivo della ricompensa che può essere utilizzato per addestrare i robot facendo in modo che gli utenti umani rispondano alle loro domande. Questo nuovo approccio, presentato in un articolo prepubblicato su arXiv, addestra i robot a porre domande a cui sarà facile rispondere per un utente umano e che non sono ridondanti o inutili.
"Il nostro gruppo è interessato a come i robot possono imparare ciò che vogliono gli umani, " I ricercatori hanno detto a TechXplore via e-mail. "Un modo intuitivo per imparare è fare domande. Per esempio, preferiresti che un'auto autonoma guidasse con cautela o in modo aggressivo? Questa macchina autonoma dovrebbe fondersi davanti o dietro un'auto a guida umana?"
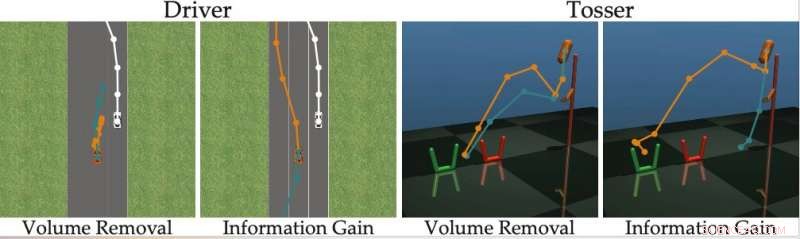
L'assunto principale alla base del recente studio è che idealmente, i robot dovrebbero porre domande informative che raccolgano quante più informazioni possibili dagli utenti umani. In altre parole, un robot dovrebbe essere in grado di capire ciò di cui un essere umano ha bisogno o vuole che faccia ponendo il minor numero di domande possibile.
In realtà, però, la maggior parte degli approcci formativi esistenti basati sulla risposta alle domande non considera quanto sarà facile per gli utenti umani rispondere a domande specifiche formulate dal robot. Ciò comporta spesso che gli utenti perdano tempo rispondendo a un sacco di domande non necessarie o non siano in grado di rispondere con certezza.
"Abbiamo scoperto che la maggior parte degli algoritmi all'avanguardia mostra le alternative umane che sono (quasi) indistinguibili, impedendo alla persona di rispondere correttamente alle domande del robot, " hanno detto i ricercatori. "Tornando al nostro esempio, questi approcci potrebbero chiedere:"Preferiresti fonderti davanti all'auto a guida umana a una velocità di 29 mph, o una velocità di 31 mph?" Questo può essere informativo per il robot per decidere se l'essere umano vuole andare più veloce di 30 mph o no, ma le opzioni sono così vicine che gli umani non possono rispondere in modo affidabile".
Per superare i limiti dei metodi di apprendimento attivo esistenti, i ricercatori hanno sviluppato un algoritmo in grado di selezionare domande più efficaci da porre agli utenti umani. L'algoritmo identifica le domande che riducono maggiormente l'incertezza del robot sulle preferenze di un utente umano (ad es. che massimizzano il guadagno di informazioni), considerando anche quanto sarà facile per un utente umano rispondere.

Credito:Bıyık et al.
"Ispirato dalle carenze dei lavori precedenti, quando abbiamo sviluppato questo algoritmo, ci siamo concentrati sulla contabilizzazione della capacità dell'essere umano di rispondere effettivamente alle domande che il robot sta ponendo, " hanno detto i ricercatori. "Questo si basa sull'idea che solo i robot che rappresentano la capacità dell'essere umano di rispondere possono imparare in modo accurato ed efficiente ciò che gli umani vogliono".
I ricercatori hanno calcolato il guadagno di informazioni misurando la diminuzione dell'entropia (cioè, una misura di incertezza) sulle preferenze dell'utente umano in funzione della domanda posta dal robot. In altre parole, una domanda che massimizza il guadagno di informazioni ridurrà maggiormente l'incertezza del robot su quali siano le preferenze dell'utente umano. Ciò offre ai robot un obiettivo formale che possono utilizzare per selezionare le domande più informative.
"Una bella caratteristica del guadagno di informazioni è che massimizza intrinsecamente l'incertezza del robot (in modo che il robot impari molto dalla domanda) riducendo al minimo l'incertezza dell'essere umano (in modo che la domanda sia facile per l'essere umano a rispondere), " hanno spiegato i ricercatori. "Generare le domande utilizzando il guadagno di informazioni migliora così l'apprendimento attivo, non solo perché le domande sono massimamente informative, ma anche perché l'umano dà meno risposte errate».
L'approccio ideato dai ricercatori seleziona avidamente la domanda che massimizza il guadagno di informazioni in ogni momento. Essenzialmente, il robot mantiene una convinzione (cioè, una distribuzione di probabilità) sulle preferenze dell'utente con cui sta interagendo e campiona sia questa convinzione che lo spazio delle possibili domande.
In definitiva, il robot sceglie la domanda che fornisce il maggior guadagno di informazioni nell'attuale distribuzione delle possibili preferenze umane. Successivamente, aggiorna le sue convinzioni su ciò che l'utente desidera in base alla risposta che riceve. Questo processo si ripete continuamente, permettendo al robot di migliorare gradualmente le sue prestazioni imparando le preferenze dell'utente.
"Abbiamo formulato un metodo gestibile dal punto di vista computazionale che ci consente di scoprire rapidamente le preferenze umane su compiti robotici reali, superando i metodi precedenti, " hanno detto i ricercatori. "Nel nostro studio, gli utenti hanno preferito il nostro metodo ad altre tecniche all'avanguardia."
Nel loro studio, il team di Stanford ha dimostrato che addestrare un robot a porre domande che massimizzano il guadagno di informazioni ha la stessa complessità computazionale dei metodi all'avanguardia. In altre parole, non è più difficile per il robot trovare queste domande informative, rispetto a quelli generati da altri approcci.
"Segnaliamo anche che il nostro approccio ha diverse proprietà matematiche desiderabili, come la submodularità, che ci consente di prendere le estensioni e i limiti teorici che sono stati sviluppati per gli approcci precedenti e usarli anche con il nostro metodo, " hanno detto i ricercatori. "Ad esempio, possiamo utilizzare i lavori precedenti per trovare diverse domande informative contemporaneamente, invece di cercare una domanda alla volta."
Il team ha valutato il loro approccio attivo all'apprendimento della ricompensa in una serie di simulazioni e ha scoperto che consente ai robot di cogliere le preferenze umane più velocemente e con maggiore precisione rispetto ad altri metodi all'avanguardia. Questo è stato riscontrato anche in situazioni in cui gli umani possono rispondere correttamente a domande difficili o quando la loro risposta è "Non lo so".
I ricercatori hanno anche condotto uno studio sugli utenti in cui hanno chiesto ai partecipanti umani di rispondere a domande generate dal loro metodo e ad altre generate utilizzando altri approcci all'avanguardia. Il feedback che hanno raccolto suggerisce che le persone trovano molto più facile rispondere alle domande generate dal loro approccio. Inoltre, gli utenti spesso ritenevano che i robot che utilizzavano il nuovo metodo avessero acquisito una rappresentazione più accurata delle loro preferenze rispetto agli approcci proposti in precedenza.
"Considerando tutti i nostri contributi insieme, abbiamo fatto un passo avanti per consentire ai robot di determinare le preferenze umane, " the researchers said. "We showed that the true objective that we originally wanted the robot to maximize—-asking questions to gain as much information as possible—-can actually be solved with the same computational complexity as existing methods."
Nel futuro, the active reward-learning technique developed by this team of researchers could help to train robots more effectively, making them more attuned to user preferences. Inoltre, it could be used to teach robots to ask questions that humans can easily understand and answer. In their future studies, the researchers would also like to investigate methods for training robots to give useful explanations for their actions.
"We are excited about robots that not only ask good questions, but can also explain why they are asking those questions, " the researchers said. "We imagine a scenario where a self-driving car visualizes two different merging options for the human, and then clarifies that it is asking about these options because it is rush hour, and it wants to determine whether it should behave more or less aggressively."
© 2019 Science X Network














