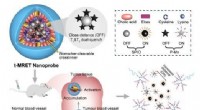
Per la consegna dell'ultimo miglio, i robot del futuro potrebbero usare un nuovo algoritmo del MIT per trovare la porta d'ingresso, usando indizi nel loro ambiente. Credito:MIT News
In un futuro non troppo lontano, i robot possono essere spediti come veicoli di consegna dell'ultimo miglio per lasciare il tuo ordine da asporto, pacchetto, o l'abbonamento al kit pasto a portata di mano, se riescono a trovare la porta.
Gli approcci standard per la navigazione robotica comportano la mappatura di un'area in anticipo, quindi utilizzando algoritmi per guidare un robot verso un obiettivo specifico o una coordinata GPS sulla mappa. Sebbene questo approccio possa avere senso per esplorare ambienti specifici, come il layout di un particolare edificio o un percorso ad ostacoli pianificato, può diventare ingombrante nel contesto della consegna dell'ultimo miglio.
Immaginare, ad esempio, dover mappare in anticipo ogni singolo quartiere all'interno della zona di consegna di un robot, inclusa la configurazione di ogni casa all'interno di quel quartiere insieme alle coordinate specifiche della porta d'ingresso di ogni casa. Tale compito può essere difficile da scalare a un'intera città, soprattutto perché gli esterni delle case cambiano spesso con le stagioni. Mappare ogni singola casa potrebbe anche incorrere in problemi di sicurezza e privacy.
Ora gli ingegneri del MIT hanno sviluppato un metodo di navigazione che non richiede la mappatura anticipata di un'area. Anziché, il loro approccio consente a un robot di utilizzare indizi nel suo ambiente per pianificare un percorso verso la sua destinazione, che può essere descritto in termini semantici generali, come "porta d'ingresso" o "garage, " piuttosto che come coordinate su una mappa. Ad esempio, se a un robot viene chiesto di consegnare un pacco alla porta di casa di qualcuno, potrebbe iniziare sulla strada e vedere un vialetto, che è stato addestrato a riconoscere come suscettibile di condurre verso un marciapiede, che a sua volta rischia di condurre alla porta d'ingresso.
La nuova tecnica può ridurre notevolmente il tempo che un robot trascorre esplorando una proprietà prima di identificare il suo obiettivo, e non si basa su mappe di residenze specifiche.
"Non vorremmo dover fare una mappa di ogni edificio che avremmo bisogno di visitare, "dice Michael Everett, uno studente laureato presso il Dipartimento di Ingegneria Meccanica del MIT. "Con questa tecnica, speriamo di far cadere un robot alla fine di ogni vialetto e fargli trovare una porta".
Everett presenterà i risultati del gruppo questa settimana alla Conferenza internazionale sui robot e i sistemi intelligenti. La carta, che è co-autore di Jonathan How, professore di aeronautica e astronautica al MIT, e Justin Miller della Ford Motor Company, è finalista per "Miglior documento per robot cognitivi".
"Un senso di cosa sono le cose"
Negli ultimi anni, i ricercatori hanno lavorato sull'introduzione di prodotti naturali, linguaggio semantico ai sistemi robotici, addestrare i robot a riconoscere gli oggetti dalle loro etichette semantiche, in modo che possano elaborare visivamente una porta come una porta, Per esempio, e non semplicemente come un solido, ostacolo rettangolare.
"Ora abbiamo la capacità di dare ai robot un'idea di come stanno le cose, in tempo reale, "dice Everett.
Everett, Come, e Miller stanno usando tecniche semantiche simili come trampolino di lancio per il loro nuovo approccio alla navigazione, che sfrutta algoritmi preesistenti che estraggono caratteristiche dai dati visivi per generare una nuova mappa della stessa scena, rappresentati come indizi semantici, o contesto.
Nel loro caso, i ricercatori hanno utilizzato un algoritmo per costruire una mappa dell'ambiente mentre il robot si muoveva, utilizzando le etichette semantiche di ogni oggetto e un'immagine di profondità. Questo algoritmo è chiamato SLAM semantico (Simultaneous Localization and Mapping).
Mentre altri algoritmi semantici hanno permesso ai robot di riconoscere e mappare gli oggetti nel loro ambiente per quello che sono, non hanno permesso a un robot di prendere decisioni sul momento durante la navigazione in un nuovo ambiente, sul percorso più efficiente da intraprendere verso una destinazione semantica come una "porta d'ingresso".
"Prima, esplorare era solo, butta giù un robot e dì "vai, " e si muoverà e alla fine ci arriverà, ma sarà lento, "Come dice.
Il costo per andare
I ricercatori hanno cercato di accelerare la pianificazione del percorso di un robot attraverso una semantica, mondo a colori di contesto. Hanno sviluppato un nuovo "stimatore del costo di uscita, " un algoritmo che converte una mappa semantica creata da algoritmi SLAM preesistenti in una seconda mappa, che rappresenta la probabilità che una determinata località sia vicina all'obiettivo.
"Questo è stato ispirato dalla traduzione da immagine a immagine, dove fai una foto a un gatto e lo fai sembrare un cane, " dice Everett. "Lo stesso tipo di idea accade qui dove prendi un'immagine che sembra una mappa del mondo, e trasformala in quest'altra immagine che assomiglia alla mappa del mondo ma ora è colorata in base a quanto vicini sono i diversi punti della mappa all'obiettivo finale."
Questa mappa del costo da raggiungere è colorata, in scala di grigi, per rappresentare le regioni più scure come luoghi lontani da un obiettivo, e regioni più leggere come aree vicine all'obiettivo. Ad esempio, il marciapiede, codificato in giallo in una mappa semantica, potrebbe essere tradotto dall'algoritmo cost-to-go come una regione più scura nella nuova mappa, rispetto a un vialetto, che è progressivamente più leggero man mano che si avvicina alla porta d'ingresso, la regione più chiara nella nuova mappa.
I ricercatori hanno addestrato questo nuovo algoritmo su immagini satellitari di Bing Maps contenenti 77 case di un quartiere urbano e tre periferici. Il sistema ha convertito una mappa semantica in una mappa cost-to-go, e tracciato il percorso più efficiente, seguendo le regioni più chiare nella mappa, all'obiettivo finale. Per ogni immagine satellitare, Everett ha assegnato etichette semantiche e colori alle caratteristiche del contesto in un tipico cortile anteriore, come il grigio per una porta d'ingresso, blu per un vialetto, e verde per una siepe.
Durante questo percorso formativo, il team ha anche applicato maschere a ciascuna immagine per imitare la vista parziale che avrebbe probabilmente la telecamera di un robot mentre attraversa un cortile.
"Parte del trucco del nostro approccio è stato [dare al sistema] molte immagini parziali, Come spiega. "Quindi doveva davvero capire come tutta questa roba fosse interconnessa. Questo fa parte di ciò che rende questo lavoro robusto".
I ricercatori hanno quindi testato il loro approccio in una simulazione di un'immagine di una casa completamente nuova, al di fuori del set di dati di addestramento, prima utilizzando l'algoritmo SLAM preesistente per generare una mappa semantica, quindi applicando il loro nuovo stimatore del cost-to-go per generare una seconda mappa, e il percorso verso un obiettivo, in questo caso, la porta di fronte.
La nuova tecnica cost-to-go del gruppo ha trovato la porta d'ingresso il 189% più veloce dei classici algoritmi di navigazione, che non tengono conto del contesto o della semantica, e invece spendi passaggi eccessivi esplorando aree che difficilmente saranno vicine al loro obiettivo.
Everett afferma che i risultati illustrano come i robot possono utilizzare il contesto per individuare in modo efficiente un obiettivo, anche in modo sconosciuto, ambienti non mappati.
"Anche se un robot sta consegnando un pacco in un ambiente in cui non è mai stato, potrebbero esserci indizi che saranno gli stessi di altri posti in cui ha visto, " dice Everett. "Così il mondo può essere strutturato in modo un po' diverso, ma probabilmente ci sono alcune cose in comune."
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.