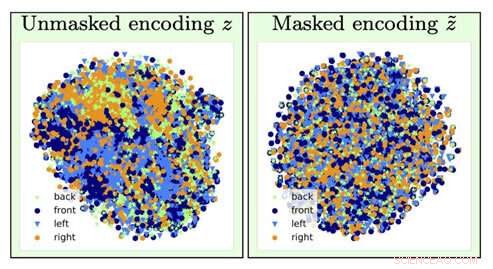
Per identificare il tipo di immagine della sedia, le informazioni sull'orientamento della sedia (un fattore di disturbo) vengono perse dall'operazione di dimenticanza (passando dalla visualizzazione di sinistra a quella di destra). Credito:University of Southern California
Immagina se la prossima volta che chiederai un prestito, un algoritmo informatico determina che devi pagare una tariffa più alta basata principalmente sulla tua razza, sesso o codice postale.
Ora, immagina che sia stato possibile addestrare un modello di deep learning AI per analizzare quei dati sottostanti inducendo l'amnesia:dimentica alcuni dati e si concentra solo su altri.
Se stai pensando che suona come la versione dell'informatico di "The Eternal Sunshine of the Spotless Mind, " saresti piuttosto azzeccato. E grazie ai ricercatori di intelligenza artificiale presso l'Information Sciences Institute (ISI) della USC, questo concetto, chiamato oblio contraddittorio, è ormai un vero e proprio meccanismo.
L'importanza di affrontare e rimuovere i pregiudizi nell'IA sta diventando sempre più importante man mano che l'IA diventa sempre più prevalente nella nostra vita quotidiana, ha osservato Ayush Jaiswal, l'autore principale del documento e il dottorato di ricerca. candidato alla USC Viterbi School of Engineering.
"AI e, più specificamente, i modelli di apprendimento automatico ereditano i pregiudizi presenti nei dati su cui vengono addestrati e sono inclini persino ad amplificarli, " ha spiegato. "L'intelligenza artificiale viene utilizzata per prendere diverse decisioni nella vita reale che riguardano tutti noi, [come] determinazione dei limiti di credito, approvare prestiti, punteggio delle domande di lavoro, ecc. Se, Per esempio, i modelli per prendere queste decisioni sono addestrati alla cieca sui dati storici senza controllare i pregiudizi, imparerebbero a trattare ingiustamente individui che appartengono a fasce storicamente svantaggiate della popolazione, come le donne e le persone di colore".
La ricerca è stata guidata da Wael AbdAlmageed, leader del gruppo di ricerca presso l'ISI e professore associato di ricerca presso il Dipartimento di Ingegneria Elettrica e Informatica di USC Viterbi, Ming Hsieh, e professore associato di ricerca Greg Ver Steeg, così come Premkumar Natarajan, professore di informatica e direttore esecutivo dell'ISI (in aspettativa). Sotto la loro guida, Jaiswal e il coautore Daniel Moyer, dottorato di ricerca, sviluppato l'approccio contraddittorio dell'oblio, che insegna ai modelli di deep learning a ignorare specifici, fattori di dati indesiderati in modo che i risultati che producono siano imparziali e più accurati.
Il documento di ricerca, intitolato "Rappresentazioni invarianti attraverso l'oblio contraddittorio, " è stato presentato alla conferenza dell'Association for the Advancement for Artificial Intelligence a New York City il 10 febbraio, 2020.
Inconvenienti e reti neurali
Il deep learning è un componente fondamentale dell'intelligenza artificiale e può insegnare ai computer come trovare correlazioni e fare previsioni con i dati, aiutando a identificare persone o oggetti, Per esempio. I modelli cercano essenzialmente associazioni tra le diverse caratteristiche all'interno dei dati e l'obiettivo che dovrebbe prevedere. Se un modello è stato incaricato di trovare una persona specifica da un gruppo, analizzerebbe le caratteristiche del viso per distinguere tutti e quindi identificare la persona presa di mira. Semplice, Giusto?
Sfortunatamente, le cose non vanno sempre così bene, poiché il modello può finire per imparare cose che possono sembrare controintuitive. Potrebbe associare la tua identità a un particolare sfondo o configurazione di illuminazione e non essere in grado di identificarti se l'illuminazione o lo sfondo sono stati alterati; potrebbe associare la tua calligrafia a una certa parola, e ti confondi se la stessa parola è stata scritta con la calligrafia di qualcun altro. Questi fattori di disturbo giustamente denominati non sono correlati all'attività che stai cercando di svolgere, e associarli erroneamente all'obiettivo di previsione può effettivamente diventare pericoloso.
I modelli possono anche apprendere i bias nei dati che sono correlati con l'obiettivo di previsione ma non sono desiderati. Per esempio, in compiti svolti da modelli che coinvolgono dati socioeconomici storicamente raccolti, come la determinazione dei punteggi di credito, linee di credito, e l'idoneità al prestito, il modello può fare previsioni false e mostrare distorsioni creando connessioni tra le distorsioni e l'obiettivo di previsione. Può saltare alla conclusione che, poiché sta analizzando i dati di una donna, deve avere un punteggio di credito basso; poiché sta analizzando i dati di una persona di colore, non devono poter beneficiare di un prestito. Non mancano le storie di banche che vengono prese di mira per le decisioni distorte dei loro algoritmi su quanto addebitano alle persone che hanno preso prestiti in base alla loro razza, Genere, e istruzione, anche se hanno lo stesso identico profilo di credito di qualcuno in un segmento di popolazione socialmente più privilegiato.
Come ha spiegato Jaiswal, il meccanismo dell'oblio contraddittorio "ripara" le reti neurali, che sono potenti modelli di deep learning che imparano a prevedere gli obiettivi dai dati. Il limite di credito che hai sulla nuova carta di credito a cui ti sei registrato? Probabilmente una rete neurale ha analizzato i tuoi dati finanziari per ottenere quel numero.
Il team di ricerca ha sviluppato il meccanismo di dimenticanza contraddittorio in modo che potesse prima addestrare la rete neurale a rappresentare tutti gli aspetti sottostanti dei dati che sta analizzando e quindi dimenticare i pregiudizi specifici. Nell'esempio del limite della carta di credito, ciò significherebbe che il meccanismo potrebbe insegnare all'algoritmo della banca a prevedere il limite mentre si dimentica, o essere invariante a, i dati particolari relativi al genere o alla razza. "[Il meccanismo] può essere utilizzato per addestrare le reti neurali in modo che siano invarianti rispetto ai pregiudizi noti nei set di dati di addestramento, " ha detto Jaiswal. "Questo, a sua volta, comporterebbe modelli addestrati che non sarebbero prevenuti mentre si prendono decisioni".
Gli algoritmi di deep learning sono ottimi per imparare cose, ma è più difficile assicurarsi che gli algoritmi non imparino certe cose. Lo sviluppo di algoritmi è un processo molto guidato dai dati, e i dati tendono a contenere pregiudizi.
Ma non possiamo semplicemente eliminare tutti i dati sulla razza, Genere, e l'istruzione per rimuovere i pregiudizi?
Non del tutto. Esistono molti altri fattori di dati correlati a questi fattori sensibili che sono importanti da analizzare per gli algoritmi. Il tasto, come hanno scoperto i ricercatori dell'ISI AI, sta aggiungendo vincoli nel processo di addestramento del modello per forzare il modello a fare previsioni pur essendo invariante a fattori specifici di dati, essenzialmente, dimenticanza selettiva.
Combattere i pregiudizi
L'invarianza si riferisce alla capacità di identificare un oggetto specifico anche se il suo aspetto (cioè, dati) è in qualche modo alterato, e Jaiswal e i suoi colleghi hanno iniziato a pensare a come applicare questo concetto per migliorare gli algoritmi. "Il mio coautore, Dan [Moyer], e in realtà ho avuto questa idea in modo un po' naturale basandomi sulle nostre precedenti esperienze nel campo dell'apprendimento della rappresentazione invariante, " ha osservato. Ma concretizzare il concetto non è stato un compito semplice. "Le parti più impegnative sono state [il] confronto rigoroso con i lavori precedenti in questo dominio su una vasta gamma di set di dati (che ha richiesto l'esecuzione di un numero molto elevato di esperimenti) e [ sviluppando] un'analisi teorica del processo di dimenticanza, " Egli ha detto.
Il meccanismo di dimenticanza contraddittoria può essere utilizzato anche per aiutare a migliorare la generazione di contenuti in una varietà di campi. "Il campo in erba del machine learning equo esamina i modi per ridurre i pregiudizi nel processo decisionale algoritmico basato sui dati dei consumatori, " ha affermato Ver Steeg. "Un'area più speculativa riguarda la ricerca sull'utilizzo dell'intelligenza artificiale per generare contenuti, inclusi tentativi di libri, musica, arte, Giochi, e anche ricette. Affinché la generazione di contenuti abbia successo, abbiamo bisogno di nuovi modi per controllare e manipolare le rappresentazioni della rete neurale e il meccanismo dell'oblio potrebbe essere un modo per farlo".
Quindi, in primo luogo, come si manifestano i pregiudizi nel modello?
La maggior parte dei modelli utilizza dati storici, quale, Sfortunatamente, può essere ampiamente sbilanciato verso comunità tradizionalmente emarginate come le donne, minoranze, anche alcuni codici postali. È costoso e complicato raccogliere dati, quindi gli scienziati tendono a ricorrere a dati già esistenti e ad addestrare modelli basati su di essi, ecco come i pregiudizi entrano in scena.
La buona notizia è che questi pregiudizi vengono riconosciuti, e mentre il problema è lontano dall'essere risolto, si stanno facendo progressi per comprendere e affrontare questi problemi. "
La determinazione di quali fattori debbano essere considerati irrilevanti o distorti viene effettuata da esperti del settore e si basa su analisi statistiche. "Finora, l'invarianza è stata principalmente utilizzata per rimuovere fattori che sono ampiamente considerati indesiderati/irrilevanti all'interno della comunità di ricerca sulla base di prove statistiche, " ha dichiarato Jaiswal.
Però, poiché i ricercatori determinano ciò che è irrilevante o di parte, ci può essere la possibilità che tali determinazioni si trasformino in pregiudizi stessi. Questo è un fattore su cui stanno lavorando anche i ricercatori. "Capire quali fattori dimenticare è un problema critico che può facilmente portare a conseguenze indesiderate, " ha osservato Ver Steeg. "Un recente articolo di Nature sull'apprendimento equo sottolinea che dobbiamo comprendere i meccanismi alla base della discriminazione se speriamo di specificare correttamente le soluzioni algoritmiche".
L'elaborazione delle informazioni umane è estremamente complessa, e il meccanismo di dimenticanza contraddittorio ci aiuta ad avvicinarci di un passo allo sviluppo di un'IA che possa pensare come noi. Come ha osservato Ver Steeg, gli esseri umani tendono a separare diverse forme di informazioni sul mondo che li circonda mediante algoritmi istintivi per fare lo stesso è la sfida a portata di mano.
"Se qualcuno passa davanti alla tua macchina, sbatti sulle pause e lo slogan sulla loro maglietta non ti viene nemmeno in mente, " disse Ver Steeg. "Ma se incontrassi quella persona in un contesto sociale, queste informazioni potrebbero essere rilevanti e aiutarti a iniziare una conversazione. Per l'intelligenza artificiale, diversi tipi di informazioni sono tutti mescolati insieme. Se possiamo insegnare alle reti neurali a separare concetti utili per compiti diversi, speriamo che porti l'IA a una comprensione più umana del mondo".
L'elaborazione delle informazioni umane è estremamente complessa, e il meccanismo di dimenticanza contraddittoria ci aiuta ad avvicinarci di un passo allo sviluppo di un'IA che possa pensare come noi. Come ha osservato Ver Steeg, gli esseri umani tendono a separare le diverse forme di informazione sul mondo che li circonda per istinto:far sì che gli algoritmi facciano lo stesso è la sfida a portata di mano.
"Se qualcuno passa davanti alla tua macchina, sbatti sulle pause e lo slogan sulla loro maglietta non ti viene nemmeno in mente, " disse Ver Steeg. "Ma se incontrassi quella persona in un contesto sociale, queste informazioni potrebbero essere rilevanti e aiutarti a iniziare una conversazione. Per l'intelligenza artificiale, diversi tipi di informazioni sono tutti mescolati insieme. Se possiamo insegnare alle reti neurali a separare concetti utili per compiti diversi, speriamo che porti l'IA a una comprensione più umana del mondo".